Unlock a world of possibilities! Login now and discover the exclusive benefits awaiting you.
- Qlik Community
- :
- Forums
- :
- Analytics
- :
- New to Qlik Analytics
- :
- Re: Load data without duplicate records - multiple...
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Load data without duplicate records - multiple columns
Hi,
i want to load tables, but without duplicate records. The value in column Product + Customer must be unique. It should be load always the record with the highes SaleNumber.
How can i do it?
Example - the red marked records shouldn´t load:
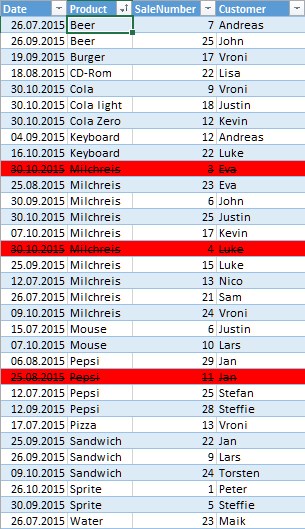
Regards,
sam
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
All your non-aggregated fields need to be in Group By statements or use FirstSortedValue here:
LOAD
Date,
Product,
Customer,
Max(SaleNumber) AS SaleNumber,
month (Date) as sMonth,
SubstringCount(Customer, ' ')+1 as countProductWords
FROM [lib://concatenate/mehrere-spalten-vergleichen.xlsx]
(ooxml, embedded labels, table is Tabelle1)
Group By Date, Product, Customer;
The newly created fields using existing fields doesn't have to go into Group By. For Example
sMonth is created using Date, so Date goes in group by, but sMonth doesn't. Same is true for countProductWords
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Mhh, my target now is to load tables, but without duplicate records. The value in column sMonth + countProductWords must be unique. It should be load always the record with the highes SaleNumber.
it´is not possible, if i create this fields in the load script?
Regards,
sam
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Why don't you try this:
LOAD Date(FirstSortedValue(Date, -SaleNumber)) as Date,
Product,
Customer,
Max(SaleNumber) AS SaleNumber,
Month(FirstSortedValue(Date, -SaleNumber)) as sMonth,
SubStringCount(Customer, ' ') + 1 as countProductWords
FROM [lib://concatenate/mehrere-spalten-vergleichen.xlsx]
(ooxml, embedded labels, table is Tabelle1)
Group By Product, Customer;
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I try it, but the table shows records with duplicate values in column sMonth + countProductWords
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I thought you wanted the corresponding date together with the sales figure. That is why I included this line because that is what I saw as a specification in your sample table.
Date(FirstSortedValue( Date, -SaleNumber)) AS Date
FirstSortedValue will pick the Date that is ranked by SaleNumber (highest) since ranking goes from lower to higher I have to invert the SaleNumber by inverting the sign (putting a minus in front does the trick).
This will guarantee that you get the corresponding date - but obviously that is not what you want in your resulting table as you made clear. Sunny T explained how the grouping list of fields has to follow the non-aggregated fields in what you want to get as result fields.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
LOAD
Date,
Product,
Customer,
Max(SaleNumber) AS SaleNumber,
month (Date) as sMonth,
SubstringCount(Customer, ' ')+1 as countProductWords
FROM [lib://concatenate/mehrere-spalten-vergleichen.xlsx]
(ooxml, embedded labels, table is Tabelle1)
//Group By Date, Product, Customer;
Group By sMonth, countProductWords;
The newly created fields using existing fields doesn't have to go into Group By. For Example
sMonth is created using Date, so Date goes in group by, but sMonth doesn't. Same is true for countProductWords
Mhh, my target now is to load tables, but without duplicate records. The value in column sMonth + countProductWords must be unique. It should be load always the record with the highes SaleNumber.
So, how can i get unique records, if i can´t use the created fields sMonth + countProductWords into Group By?
Regards,
sam
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
May be do it in the preceding load
LOAD sMonth,
countProductWords
Max(SaleNumber) as SaleNumber
Group By sMonth, countProductWords;
LOAD
Date,
Product,
Customer,
month (Date) as sMonth,
SubstringCount(Customer, ' ')+1 as countProductWords
FROM [lib://concatenate/mehrere-spalten-vergleichen.xlsx]
(ooxml, embedded labels, table is Tabelle1);
Now you next question will be that I lost Product and Customer and Date.... the problem is that you are only sharing bits and pieces of the information and since we don't know what the final goal is we might not be able to help you in one go.... it might help to explain what is the final requirement from this script? Do you just need sMonth and countProductWords or do you also need other fields from your original file? Do you still need to do this in one load? Avoid even preceding load?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Sunny,
yes, you are right, sorry. But i don´t always know all my questions before, because i test, test, test and test something and then i got the next idea, problem, error = question.
So i try to describe the situation and final goal:
The Table and data wich i use here are only test data, because it is easier to use and explain. Actually I have some csv files and they are very big (>300 MB) and have a lot of duplicates. I want to load the files from a directory. With the time new files are added and all csv files should allways load.
I don´t want load all data from theses csv files in Qlik Sense, because to need less time to load and less memory. So i want to load only unique records and check the values of different columns for duplicates to load less data without duplicates.
But in the csv are not all columns wich i need to check for duplicates. So i must first create the columns in the load script.
In this example this is a csv:
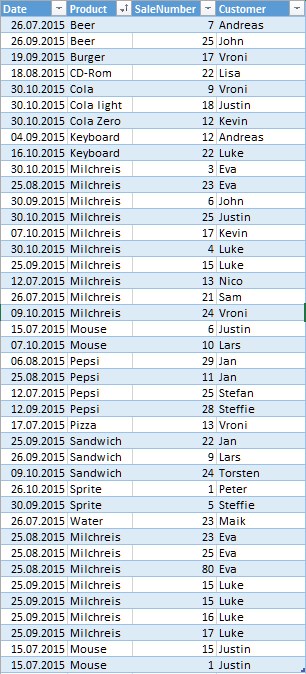
And in the load script i need this table with 2 created fields: sMonth and countProductWords
so that i can check the values from column Product+sMonth+contProductWords and get always the record with the highest SaleNumber. Then i can load from the csv less data in Qlik Sense.
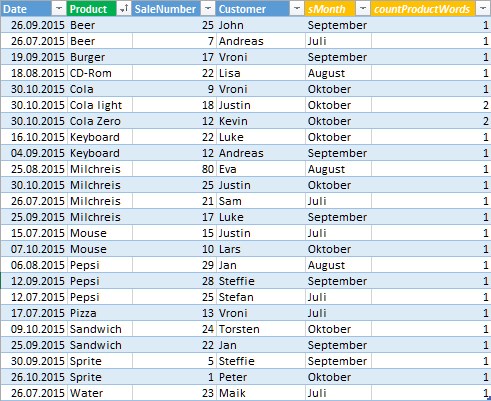
I hope I could describe my goal completely.
Regards,
sam
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I think you need to try this:
Table:
LOAD Customer,
Product,
sMonth,
countProductWords,
Date(FirstSortedValue(Date, -SaleNumber)) as Date
Max(SaleNumber) as SaleNumber
Group By sMonth, countProductWords, Product, Customer;
LOAD
Date,
Product,
Customer,
month (Date) as sMonth,
SubstringCount(Customer, ' ')+1 as countProductWords
FROM [lib://concatenate/mehrere-spalten-vergleichen.xlsx]
(ooxml, embedded labels, table is Tabelle1);
This will give you all the fields you need and it will group by sMonth, Product, Customer and countProductWords. In case you don't want customer, you can try this
Table:
LOAD Product,
sMonth,
countProductWords,
Date(FirstSortedValue(Date, -SaleNumber)) as Date
Max(SaleNumber) as SaleNumber
Group By sMonth, countProductWords, Product;
LOAD
Date,
Product,
Customer,
month (Date) as sMonth,
SubstringCount(Customer, ' ')+1 as countProductWords
FROM [lib://concatenate/mehrere-spalten-vergleichen.xlsx]
(ooxml, embedded labels, table is Tabelle1);
I hope this gives you what you are looking for....
Best,
Sunny
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
In case you don't want customer, you can try this
Table:
LOAD Product,
sMonth,
countProductWords,
Date(FirstSortedValue(Date, -SaleNumber)) as Date
Max(SaleNumber) as SaleNumber
Group By sMonth, countProductWords, Product;
LOAD
Date,
Product,
Customer,
month (Date) as sMonth,
SubstringCount(Customer, ' ')+1 as countProductWords
FROM [lib://concatenate/mehrere-spalten-vergleichen.xlsx]
(ooxml, embedded labels, table is Tabelle1);
I want to load all columns from the csv, but check duplicates based on sMonth, countProductWords, Product. So i try this. But now i cant´t find the field "Customer" under the fields.
Regards,
Sam