Unlock a world of possibilities! Login now and discover the exclusive benefits awaiting you.
- Qlik Community
- :
- Forums
- :
- Analytics
- :
- New to Qlik Analytics
- :
- Re: Load data without duplicate records - multiple...
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Load data without duplicate records - multiple columns
Hi,
i want to load tables, but without duplicate records. The value in column Product + Customer must be unique. It should be load always the record with the highes SaleNumber.
How can i do it?
Example - the red marked records shouldn´t load:
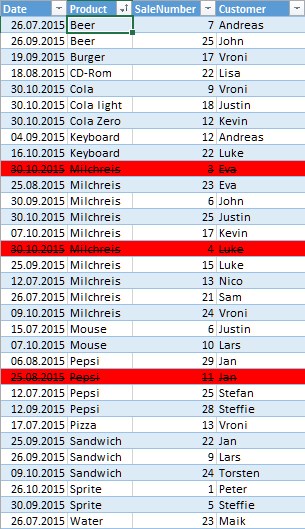
Regards,
sam
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi
This question has been answered
But Ive done this as follows (where I want to eliminate not combine duplicate lines)
Do an initial load of DATA: (order by only works with a resident load)
DATA:
LOAD
*
FROM ETC ;
then do a second resident load by ordering as appropriate
something like
DATA2:
// LEVEL 2
load
*
WHERE NOT EXISTS (temp1),
//level 1
load
* ,
Product & Customer AS temp1
RESIDENT DATA
ORDER BY SaleNumber desc ; // order by descending. Default ascending
drop table DATA ;
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Did you not look at my response completely? I did give you two script... did you try this?
Table:
LOAD Customer,
Product,
sMonth,
countProductWords,
Date(FirstSortedValue(Date, -SaleNumber)) as Date
Max(SaleNumber) as SaleNumber
Group By sMonth, countProductWords, Product, Customer;
LOAD
Date,
Product,
Customer,
month (Date) as sMonth,
SubstringCount(Customer, ' ')+1 as countProductWords
FROM [lib://concatenate/mehrere-spalten-vergleichen.xlsx]
(ooxml, embedded labels, table is Tabelle1);
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I think robert99 the problem is that OP doesn't want to do it in multiple loads. Although preceding load is also considered multiple also, but somehow OP is fine with that, but not resident load 
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I read it completly. You wrote
In case you don't want customer, you can try this
I don´t want to check the field customer for duplicates. Only for Product+sMonth+contProductWords
And in the load script i need this table with 2 created fields: sMonth and countProductWords
so that i can check the values from column Product+sMonth+contProductWords and get always the record with the highest SaleNumber. Then i can load from the csv less data in Qlik Sense.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
May be this then....
Table:
LOAD FirstSortedValue(Customer, -SaleNumber)) as Customer,
Product,
sMonth,
countProductWords,
Date(FirstSortedValue(Date, -SaleNumber)) as Date
Max(SaleNumber) as SaleNumber
Group By sMonth, countProductWords, Product, Customer;
LOAD
Date,
Product,
Customer,
month (Date) as sMonth,
SubstringCount(Customer, ' ')+1 as countProductWords
FROM [lib://concatenate/mehrere-spalten-vergleichen.xlsx]
(ooxml, embedded labels, table is Tabelle1);
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Sunny
I don't think this is possible unless the data is in the correct order
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Sunny,
thanks a lot for your help and patience 😉 Now it works.
I attched an example and would like to summarize again what the script makes for me and other user´s.
The script load Table "mehrere-spalten-vergleichen.xlsx" and add 2 new columns: tempMonth, countProductWords.
It checks the values from column Product+Customer+tempMonth for duplicates and load only records with unique values here. It loads always the record with the highest value for SaleNumber from duplicate records.
This table is loaded: mehrere-spalten-vergleichen.xlsx
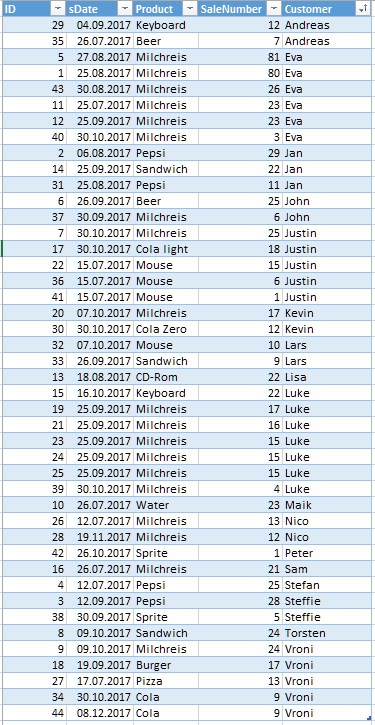
This is a section from the table after load in Qlik Sense:
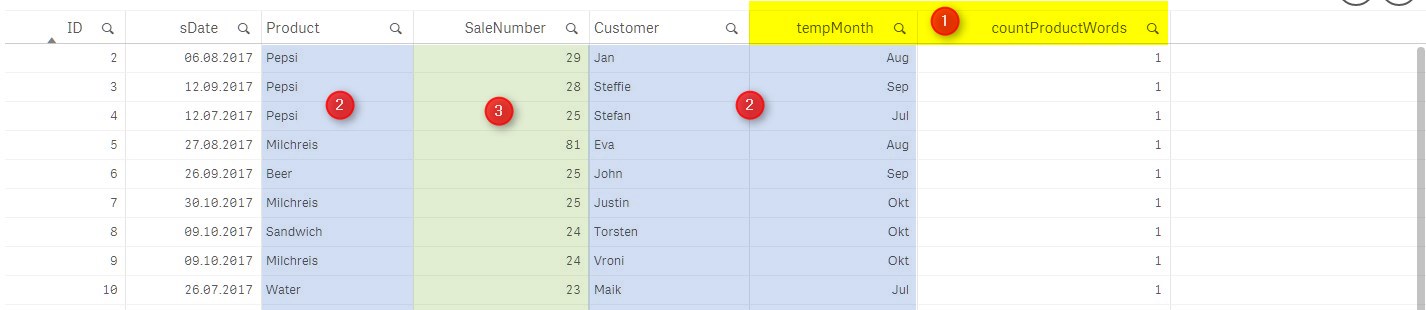
1. 2 added columns
2. Values check for duplicates (Group By Product, Customer, tempMonth;)
3. Check for the highest value for each duplicate record (Max(SaleNumber) as SaleNumber)
I hope I have described everything correctly and it also helps others.
Regards,
Sam
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
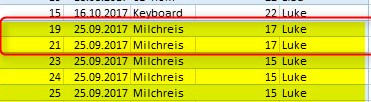
I have a problem, i want to load always 1 record from duplicates for Product, Customer, tempMonth.
Now in the source table are 2 records with the max(SaleNumber) wich is the same:
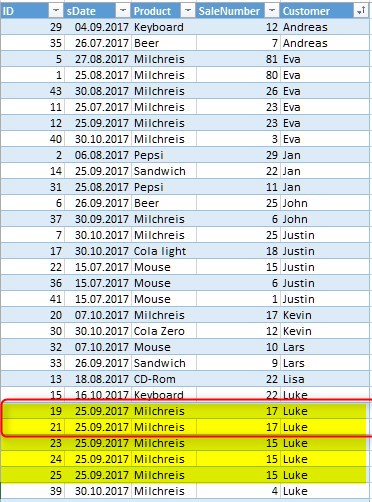
If i load...
// Each field wich want to load and not Group by must be aggregated
// Each field wich want to load and Group by must be not aggregated
tblSales:
LOAD
FirstSortedValue(ID, -SaleNumber) as ID,
Date(FirstSortedValue(sDate, -SaleNumber)) as sDate,
Product,
// To get the records with the highest value
Max(SaleNumber) as SaleNumber,
Customer,
// create field:
tempMonth,
// create field:
FirstSortedValue(countProductWords, -SaleNumber) as countProductWords
// Fields to check together for duplicates
Group By Product, Customer, tempMonth;
LOAD
ID,
sDate,
Product,
SaleNumber,
Customer,
month (sDate) as tempMonth,
SubstringCount(Customer, ' ')+1 as countProductWords
FROM [lib://sources/mehrere-spalten-vergleichen.xlsx]
(ooxml, embedded labels, table is Tabelle1);
... i got this:
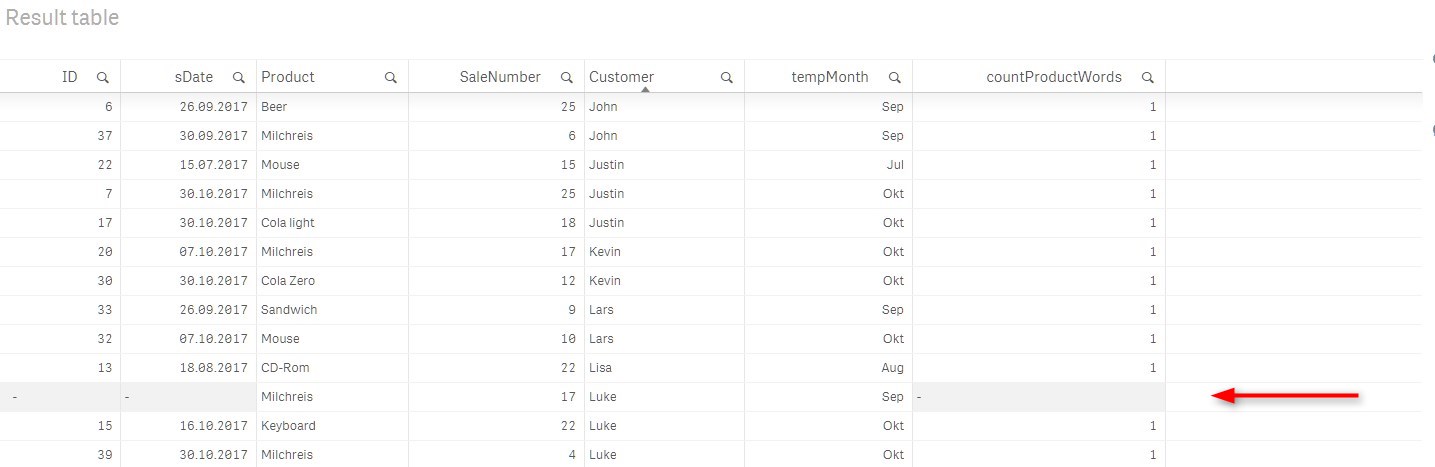
What can i do, to get only 1 of these bot records?
Regards,
Sam
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Try this:
tblSales:
LOAD
Min(ID) as ID,
Date(FirstSortedValue(DISTINCT sDate, -SaleNumber)) as sDate,
Product,
// To get the records with the highest value
Max(SaleNumber) as SaleNumber,
Customer,
// create field:
tempMonth,
// create field:
FirstSortedValue(DISTINCT countProductWords, -SaleNumber) as countProductWords
// Fields to check together for duplicates
Group By Product, Customer, tempMonth;
LOAD
ID,
sDate,
Product,
SaleNumber,
Customer,
month (sDate) as tempMonth,
SubstringCount(Customer, ' ')+1 as countProductWords
FROM [lib://sources/mehrere-spalten-vergleichen.xlsx]
(ooxml, embedded labels, table is Tabelle1);
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
