Unlock a world of possibilities! Login now and discover the exclusive benefits awaiting you.
- Qlik Community
- :
- Forums
- :
- Analytics
- :
- New to Qlik Analytics
- :
- Re: Qlik sense scripting: use of codepage & delimi...
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Qlik sense scripting: use of codepage & delimiter
Dears,
Very silly questions, but hey, still an apprentice 🙂
In scripting, for loads from excel files, I'm used to the below to identify my source data
FROM
[$(vL.PipelineFile)]
(ooxml, embedded labels, header is 9 lines, table is [Incoming Pipeline])
where not isnull(CRM );
ow I see for a part of our script:
FROM
[$(vL.ExternalFundFile)]
(txt, codepage is 1252, embedded labels, delimiter is ';', msq)
As I don't understand what this does, I can't figger out how to simply add a column from the source file to my load in Qlik.
Can somebody explain what the above means? Thanks a lot
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi, thanks but no, it's not helping.
What is codepage? What does it do?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi there Camille,
Provided that you find Beck's clarification in regards to delimiters satisfactory let's then try and tackle the codepage notion. You might think of them similar to character sets.
Strictly speaking a code page is a table of characters and corresponding numerical representation. This provides the means of mapping the characters to their binary values. Character sets on the other hand are just a collection of symbols without a method of encoding applied.
In simple terms the codepage bit tells Qlik which 'map' to use in order to properly interpret the characters contained in your file.
Please see below an eloquent example:
Unicode is best described at www.unicode.org. The Unicode Standard says "The Unicode Standard is the universal character encoding scheme for written characters and text. It defines a consistent way of encoding multilingual text that enables the exchange of text data internationally..." Basically its kind of a enormous character set that encompasses all of the other characters. It’s encoded in UTF-8, UTF-16 or UTF-32. All 3 UTF encodings are representations of the same set of characters. Windows and .Net (and many other systems) use Unicode natively, and it’s the natural preferred encoding for .Net or Windows applications.
source and further reading here.
I also found this image to be helpful:
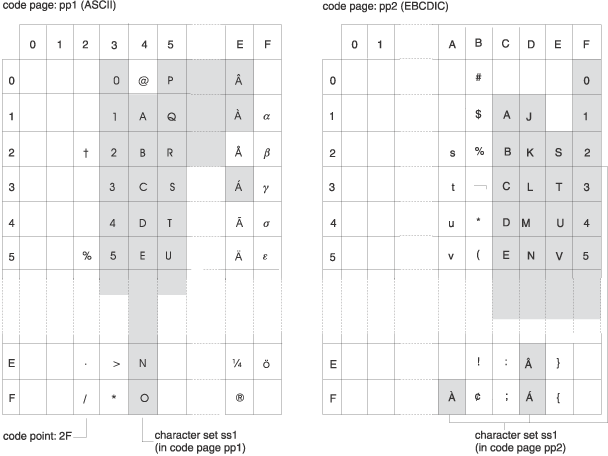
Hope this helps!
Cheers,
Alex
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
thanks Alexandru!