Unlock a world of possibilities! Login now and discover the exclusive benefits awaiting you.
- Qlik Community
- :
- All Forums
- :
- QlikView App Dev
- :
- Re: Is there a faster way to calculate a dimension...
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Is there a faster way to calculate a dimension?
Hi,
We use Qlikview for a dataset of 1.5 billion rows. Due to its size, normal methods of calcuating fields can take too long and I have to look for another method.
I am really struggling with the speed of one calculation that uses the aggr function. We want to roll up item level data to calculate the number of people who have bought 1,2,3 etc of a particular item in one transaction (a basket). The outcome looks as follows...
Target Units Basket Count
1 8,000,000
2 6,000,000
3 3,000,000
4 1,000,000
The calculated dimension and expression formula I have used for this is below. Does anyone know another way we could get this result using a different method that might run faster? The approach of using a dimension with the aggr function is taking 5 minutes to calculate!
Dimension =aggr(distinct sum(SALES_UNITS), BasketNumber)
Expression = count(distinct BasketNumber)
Many thanks for any help.
- « Previous Replies
-
- 1
- 2
- Next Replies »
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Tom,
Firstly, using COUNT(DISTINCT xxxx) across 1.5bn rows is going to hit your performance significantly I would think (depending on the number of distinct BasketNumbers). Try this first:
In your script, add a field to your Basket table:
,1 AS %Counter_Basket
I am assuming the Basket table contains only DISTINCT BasketNumbers. If not, extract to a different table:
BasketNumbers:
LOAD DISTINCT
BasketNumber
,1 AS %Counter_Basket
RESIDENT TableWithBasketNumberInIt;
(I have prefixed the field with % to hide it - you will need to add SET HidePrefix = '%'; to the top of your script)
Then, as your expression, use SUM(%Counter_Basket) instead of COUNT(DISTINCT BasketNumber).
Try that first and it should improve. If you still need more improvement then we can attack the Aggr() too.
Hope this helps,
Jason
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thanks Jason,
I have implemented your suggestions to remove the count distincts and it has improved the timings, but it still takes just over 4 minutes to run. Any further thoughts you may have on the aggr function would be appreciated.
John
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Can you post a screenshot of your data model?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
If possible, some pre aggregation in the script would be helpful. If the reporting dimension always a single item#? And can there be additional filters applied to ta basket/item combo?
What I'm getting at is doing a script calc of the unit count by BasketNumber, Item#. Then you could use the UnitCount as a dimension field and avoid the aggr/ Possible?
-Rob
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
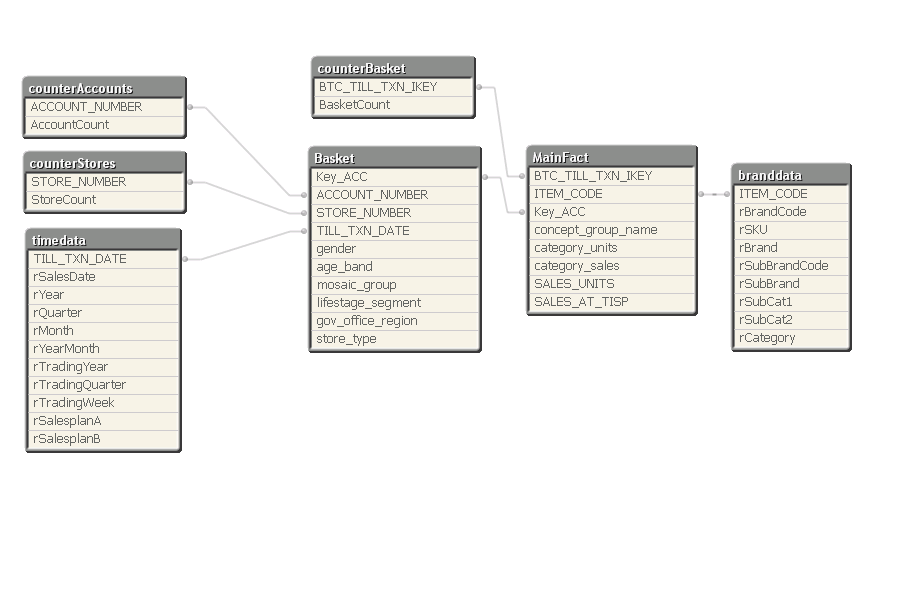
Hi Jason, Here is the layout of the tables. The BasketNumber in my earlier formulas equates to BTC_TILL_TXN_KEY in they tables.
Rob - Thank you for your input, sadly the selection criteria can be any possible combination of SKUs going right down to the lowest level so there is no way to roll the table up to a summarised level first.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hello,
Try to use a real star model or aggregation like adviced by Rob.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Can you check -- using windows task manager -- that multiple CPUs are being used in the calculation?
-Rob
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Rob,
why Qlikview use only 1 CPU ? It's a parameter that can be change ? I have already noticed that sometimes, on some tasks, Qlikview use only 1 CPU when the number of usable CPU specified in QEMC is 10.
Thanks
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Tom,
Well I'm glad we have a achieved a 20% performance improvement already! You might want to search this forum for "Best Practices" to get more tips on things like this.
Regarding the Aggr() - try removing the DISTINCT. I'm not sure you need it. Other than that I can't really think of another way. The reality is that unless you have some really serious hardware, calculating over 1.5bn records is going to be slow. Have you considered breaking up the qvw based on a dimension (gov_office_region, for example)? Or restricting the date range per application? You can use document chaining to move to archived data if necessary - is it really important to have all data available in the same application? I think you may need to start thinking along these lines.
On your data model, you might want to consider bringing the timedata table into the same table as Basket, and branddata into MainFact to reduce the joins.
Hope this helps,
Jason
- « Previous Replies
-
- 1
- 2
- Next Replies »