Unlock a world of possibilities! Login now and discover the exclusive benefits awaiting you.
- Qlik Community
- :
- Forums
- :
- Groups
- :
- Industry and Topics
- :
- Deployment Framework
- :
- Re: 3 Tier Architecture + QDF
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Feature this Topic
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
3 Tier Architecture + QDF
Hey guys,
I've been playing around with the QDF and am trying to think out a sound way to set up 3 tier architecture and mixing it with the QDF framework.
What I have so far is this as the base folder:
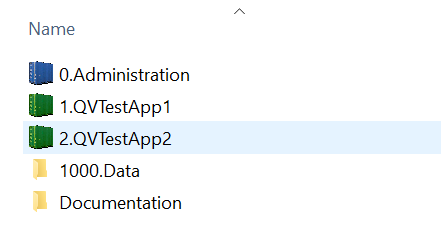
And then under 1000.Data I have 3 containers for each part (Extract, Transform, Load) and the thought is that the test apps will do binary loads from qvws stored in the "Load" container under the application folder there.
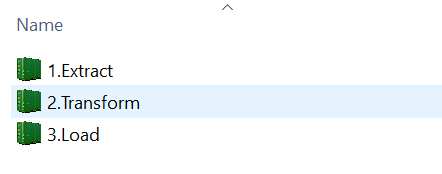
Now I am wondering what do you guys think about that as a general way of doing it? Just trying to create some best practice and get benefits from having a ETL centric process, QDF variable / container mindset and binary loads for speed.
And for the stages from Extract -> Transform -> Load -> Binary Load would you make variables to connect these? Or relative paths?
e.g. in the transform app I will load form a path variable named vG.ExtractQVDPath and from Load I will load from vGTransformQVDPath etc or does anyone have any suggestions for how to tie it all together?
Thanks for all responses and help.
Best,
Ali A
- Tags:
- Group_Discussions
Accepted Solutions
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Ali,
I don't think there is a correct or incorrect answer to this.
For the scenario where all the data for a given solution is coming from a single datasource I have often setup a single container with the following structure. I found that this is a simple structure. All artefacts reside in a single container so it is easier to move across DEV,UAT,PROD. I also find that this design pattern is often simplier for the client to grasp when they are new to Qlik.
Single Container
1.Application
-> 10.Extraction QVD Generator
-> 20.Transformation QVD Generator
-> Application
2.QVD
-> 10.Raw
-> 20.XForm
-> 30.Published
Alternatively the design you have document aligns more with the concept of a data catalogue. This is great where QVDs may come from many sources and also may be consumed by many applications. I find this is design pattern to be of more use when the organisation is more mature on their Qlik journey.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Ali,
I don't think there is a correct or incorrect answer to this.
For the scenario where all the data for a given solution is coming from a single datasource I have often setup a single container with the following structure. I found that this is a simple structure. All artefacts reside in a single container so it is easier to move across DEV,UAT,PROD. I also find that this design pattern is often simplier for the client to grasp when they are new to Qlik.
Single Container
1.Application
-> 10.Extraction QVD Generator
-> 20.Transformation QVD Generator
-> Application
2.QVD
-> 10.Raw
-> 20.XForm
-> 30.Published
Alternatively the design you have document aligns more with the concept of a data catalogue. This is great where QVDs may come from many sources and also may be consumed by many applications. I find this is design pattern to be of more use when the organisation is more mature on their Qlik journey.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Damian,
First of all thanks for the response. I agree with what you say above, that works quite well with a single source, but of curiosity, if the client wants to add another source - how would you do that then? Just create additional QVDs with maybe renaming? Example:
Excel_Products_QVD
SQL_Customer_QVD
And why do you have one structure within the QVD folder that does the transformation from Raw -> Xform ->Publish and then also a QVD generator that does extract and transform? Just wondering how you've tied this together.
Best,
Ali A
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Again there is no correct answer. I find that a single container is a simple starting point even when multiple data-sources. When I have single container I may create sub-folders for where they come from. I.e QVD\RAW\Excel.
However it is likely that in the future you would need to redesign the structure as you build more and more applications. Therefore it may be better to start with the data catalogue approach so that published QVDs are grouped together in a container. Such as Finance QVDs, HR QVDs etc. Then applications can then include these other containers.
In regards to your second point for extraction and transform. Reload times are greatly reduced when reading off QVD files. Therefore the first thing I do is create Raw QVD files from the source. I then use these to write the transformation logic. This has two benefits
1 - it it much faster to process so you don't waste time during development
2 - you do not have to be online where you data is coming from a database.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
This is the route we are also utilising. Dump the raw stuff from source data into QVD layers. Makes the field renaming etc. much easier to do in Qlik, much faster and the level 2 QVDs can employ resident or binary loading and all the great functions available within the application. This layering is much easier to manage when faced with multiple diverse data sources.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
In the QDF Example (option in QDF installation), they make use of the 4.Mart folder. The penny dropped.
We now make use of QDF with these routines..
2.QVD folders for storing QVD's - by all means have subfolders beneath these for say Extract (raw data), Transform and final Production qvd's. These are populated by QVD-Generator scripts in a subfolder of 1.Application (we use 1.QVDGenerators subfolder).
Then do development work on the front-end app loading from the Production folder (or wherever final qvd's are stored), ensuring the load and data model is correct and fit for use in charts/tables etc
Copy the front end app to the 4.Mart container and modify it so that only the load script remains - no charts/tables needed for this version as we are only interested in data load and data model. This 4.Mart version, going forward, does the heavy data loading for the front end.
The original front end app, from which the 4.Mart copy was produced, replace the qvd loading script with binary load from the 4.Mart version.
Now going forward......
Layer 1 - QVDGenerators loading the qvd's. (ET part of ETL)
Layer 2 - 4.Mart app loading from the qvd's (L part of ETL)
Layer 3 - Final front end app binary loaded from the 4.Mart app (Presentation, with fastest possible reload)
Also, no real need for extra containers and makes use of existing global variables for 2.QVD and 4.Mart folders.
I often wondered what the 4.Mart container was for.... guess the clue was in the container name.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Some really good responses guys! Thanks for sharing!