Unlock a world of possibilities! Login now and discover the exclusive benefits awaiting you.
- Qlik Community
- :
- All Forums
- :
- QlikView App Dev
- :
- Re: Do I use a loop for this?
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Do I use a loop for this?
I have two tables:
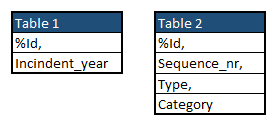
Of course, this is a simpified version of the original.
I have (inner) joined these tables to one new table, with the following contence:
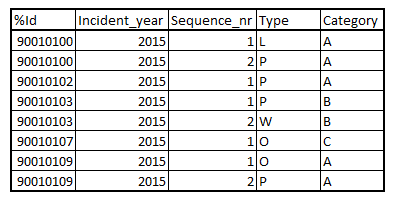
For my project I have to 'distill' a new table from this one. as you can see, the Sequence_nr determines the number of times the %Id appears in the table. In my new table, there would be only one unique value for %Id. Second: the contence of 'Type' is very relevant. It can only be 'L', 'O', 'P' of 'W', in the same order of importance.
One %Id can have any number of sequence numbers, but when type 'L' is present in one of those, the resulting record would only contain the source record of type 'L'. All other records should be discarded. If no 'L' is present and an 'O' record is present, the resulting unique record should be the one that originally contained the 'O' - again the rest should be discarded, etcetera. Of course, if only 1 Sequence_nr was present, no records are discarded.
Which should result in the following table:
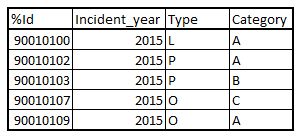
What would be the correct (and preferably fastest) way of achieving this? Should I use a loop on my concatenated table? And if yes, how? I am sure this would be an interesting case for anyone who wishes to create a table containing only unique values, determined by a value in one of the original tables...
- « Previous Replies
-
- 1
- 2
- Next Replies »
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
So you want to join only the records with sequence_nr 1. Try this then:
MyTable:
LOAD *
FROM [Table 1];
JOIN (MyTable)
LOAD *
FROM [Table 2]
WHERE Sequence_nr =1;
talk is cheap, supply exceeds demand
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi,
guessing Type doesn't have to appear in Table2 in your preferred order, one solution might be:
Table1:
LOAD * Inline [
%Id, Incident_year
90010100, 2015
90010102, 2015
90010103, 2015
90010107, 2015
90010109, 2015
90010110, 2015
];
Table2:
LOAD * Inline [
%Id, Sequence_nr, Type, Category
90010100, 1, L, A
90010100, 2, P, A
90010102, 1, P, A
90010103, 1, P, B
90010103, 2, W, B
90010107, 1, O, C
90010109, 1, O, A
90010109, 2, P, A
90010110, 1, W, D
90010110, 2, O, D
];
NoConcatenate
TabResult:
LOAD * Resident Table1;
Join (TabResult)
LOAD %Id,
Pick(WildMatch(Concat(Type,'|'),'*L*','*O*','*P*','*W*'),'L','O','P','W') as Type,
Only(Category) as Category
Resident Table2
Group By %Id;
DROP Tables Table1, Table2;
hope this helps
regards
Marco
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
or maybe like:
TabType:
LOAD * Inline [
Type
L
O
P
W
C
F
];
Table1:
LOAD * Inline [
%Id, Incident_year
90010100, 2015
90010102, 2015
90010103, 2015
90010107, 2015
90010109, 2015
90010110, 2015
90010111, 2015
];
Table2:
LOAD * Inline [
%Id, Sequence_nr, Type, Category
90010100, 1, L, A
90010100, 2, P, A
90010102, 1, P, A
90010103, 1, P, B
90010103, 2, W, B
90010107, 1, O, C
90010109, 1, O, A
90010109, 2, P, A
90010110, 1, W, D
90010110, 2, O, D
90010111, 1, F, H
90010111, 2, C, H
];
NoConcatenate
TabResult:
LOAD * Resident Table1;
Join (TabResult)
LOAD %Id,
FirstSortedValue(Type,FieldIndex('Type',Type)) as Type,
Only(Category) as Category
Resident Table2
Group By %Id;
DROP Tables Table1, Table2, TabType;
hope this helps
regards
Marco
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
another one:
TabType:
LOAD AutoNumber(Type,'Type') Inline [
Type
L
O
P
W
C
F
];
Table1:
LOAD * Inline [
%Id, Incident_year
90010100, 2015
90010102, 2015
90010103, 2015
90010107, 2015
90010109, 2015
90010110, 2015
90010111, 2015
];
Table2:
LOAD * Inline [
%Id, Sequence_nr, Type, Category
90010100, 1, L, A
90010100, 2, P, A
90010102, 1, P, A
90010103, 1, P, B
90010103, 2, W, B
90010107, 1, O, C
90010109, 1, O, A
90010109, 2, P, A
90010110, 1, W, D
90010110, 2, O, D
90010111, 1, F, H
90010111, 2, C, H
];
NoConcatenate
TabResult:
LOAD * Resident Table1;
Join (TabResult)
LOAD %Id,
FirstSortedValue(Type,AutoNumber(Type,'Type')) as Type,
Only(Category) as Category
Resident Table2
Group By %Id;
DROP Tables Table1, Table2, TabType;
regards
Marco
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
or
MapType:
Mapping LOAD *,RecNo() Inline [
Type
L
O
P
W
C
F
];
Table1:
LOAD * Inline [
%Id, Incident_year
90010100, 2015
90010102, 2015
90010103, 2015
90010107, 2015
90010109, 2015
90010110, 2015
90010111, 2015
];
Table2:
LOAD * Inline [
%Id, Sequence_nr, Type, Category
90010100, 1, L, A
90010100, 2, P, A
90010102, 1, P, A
90010103, 1, P, B
90010103, 2, W, B
90010107, 1, O, C
90010109, 1, O, A
90010109, 2, P, A
90010110, 1, W, D
90010110, 2, O, D
90010111, 1, F, H
90010111, 2, C, H
];
NoConcatenate
TabResult:
LOAD * Resident Table1;
Join (TabResult)
LOAD %Id,
FirstSortedValue(Type,ApplyMap('MapType',Type)) as Type,
Only(Category) as Category
Resident Table2
Group By %Id;
DROP Tables Table1, Table2;
hope this helps
regards
Marco
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
The fastest way of doing this is by just making a chart in your UI without creating a new table. A chart can make exactly what you need.
You can create a straight table with:
1) Two dimensions: %Id, Incident_year
2) Two expressions:
Chr( Min( Ord( Type ) ) )
Only( Category )
That's all.
If you absolutely need or want to HAVE a new table in your load script you could create it like this:
DATA2:
LOAD
%Id AS %Id_,
Incident_year AS Incident_year_,
Chr( Min( Ord( Type ) ) ) AS Type_,
Only( Category ) AS Category_
RESIDENT
DATA
GROUP BY
%Id, Incident_year;
Have a look at the attached QVW for example of both.

- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Gijsbert,
That's not what I want.
Let's suppose that one %Id has ten records, each with a different sequence_nr.
- if ONE of those contains type 'L', (sequence_nr not important) then I just want THAT record. The rest must be discarded.
- if NONE of those contains type 'L', but ONE of those contains type 'O', then I just want THAT record - the rest must be discarded.
- if NONE of those contains either 'L' or 'O', but one contains type 'P', then I just want THAT one - the rest must be discarded.
- if NONE of those contains either 'L' or 'O' or 'P', but one contains type 'W' then I just want THAT one - the rest must be discarded.
So: If you have one %Id for ten records, and they ALL have 'P', then I only want one, prefereably the one with the lowest sequence_nr.
If there is ONE type record for an %Id, then there is no need for testing: I just want that one.
I hope this clears my problem. The L-O-P-W order is leading.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Dear Marco and Petter,
Again, I get the feeling I didn't explain my case properly, so I will repeat the post I did for Gijsbert:
The order LOPW is NOT a sorting order, it's the order of IMPORTANCE for de-doubling records.
Let's suppose that one %Id has ten records, each with a different sequence_nr.
- if ONE of those contains type 'L', (sequence_nr not important) then I just want THAT record. The rest must be discarded.
- if NONE of those contains type 'L', but ONE of those contains type 'O', then I just want THAT record - the rest must be discarded.
- if NONE of those contains either 'L' or 'O', but one contains type 'P', then I just want THAT one - the rest must be discarded.
- if NONE of those contains either 'L' or 'O' or 'P', but one contains type 'W' then I just want THAT one - the rest must be discarded.
So: If you have one %Id for ten records, and they ALL have 'P', then I only want one, prefereably the one with the lowest sequence_nr.
If there is ONE type record for an %Id, then there is no need for testing: I just want that one.
I hope this clears my problem. The L-O-P-W order is leading in the de-doubling of record sets..
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Perhaps like this:
Temp:
Load *, RecNo() as Sort Inline [
Type
L
O
P
W
];
LEFT JOIN (Temp)
LOAD * Inline [
%Id, Sequence_nr, Type, Category
90010100, 1, L, A
90010100, 2, P, A
90010102, 1, P, A
90010103, 1, P, B
90010103, 2, W, B
90010107, 1, O, C
90010109, 1, O, A
90010109, 2, P, A
90010110, 1, W, D
90010110, 2, O, D
90010111, 1, F, H
90010111, 2, C, H
];
Data:
Noconcatenate
LOAD * Resident Temp
Order By %Id, Sort;
Drop Table Temp;
Right Join (Data)
LOAD %Id, FirstValue(Type) as Type
Resident Data
Group By %Id
;
talk is cheap, supply exceeds demand
- « Previous Replies
-
- 1
- 2
- Next Replies »