Unlock a world of possibilities! Login now and discover the exclusive benefits awaiting you.
- Qlik Community
- :
- All Forums
- :
- QlikView App Dev
- :
- Re: Semicolon in Data Source - How to load the dat...
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Semicolon in Data Source - How to load the data properly?
Hi guys,
I need your help, if there is anything possible.
The situation is as follows:
I have a csv file as data source which gets updated multiple times a day. The csv file is semicolon seperated. It always contains a fixed set of columns (20 columns). One column is a description. Like twice a week or so it happens that in 2-5 rows the description contains a semicolon in the text.
As I want to automate the whole data loading process you see the point, right? Is there any way or possibility to do not get an error when this happens, caused by the fact that the rows get displaced due to the semicolon in the text. My first idea was to just replace the semicolon seperator with something else when the source exports the csv file, but this is unfortunately not possible.
Is there any way to overcome this?
Thanks guys!
Greetings,
Seb
- « Previous Replies
- Next Replies »
Accepted Solutions
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi,
another version that includes an ID field to be able to load files with double rows.
(and some comments, Rob 😉
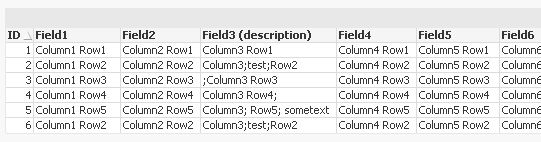
// defining the number of the column that might contain semicolons
LET vColumnWithSemicolon = 3;
LET vColumns = 20;
// load whole lines of csv file without headers and adding double quotes around values of above specified column
// quoted semicolons will not be treated as delimiters. Append Record numbers as additional column to let lines be distinct
table1:
LOAD Left([@1:n],Index([@1:n],';',$(vColumnWithSemicolon)-1))&'"'&Mid([@1:n],Index([@1:n],';',$(vColumnWithSemicolon)-1)+1,Index([@1:n],';',SubStringCount([@1:n],';')+$(vColumnWithSemicolon)-$(vColumns)+1)-Index([@1:n],';',$(vColumnWithSemicolon)-1)-1)&'"'&Mid([@1:n],Index([@1:n],';',SubStringCount([@1:n],';')+$(vColumnWithSemicolon)-$(vColumns)+1))&';'&(RecNo()-1) as line
FROM QlikCommunity_Thread_202456_v2.csv (fix, codepage is 1252)
Where RecNo()>1;
// load separate fields from previously loaded field "line"
// This load creates field names @1 to @n (n being the ID/RecNo field)
table2:
LOAD *
From_Field (table1, line) (txt, codepage is 1252, no labels, delimiter is ';', msq);
// calculate fieldnumber of ID field
LET vIDColumn = $(vColumns)+1;
// create temporary table having columns for old and new field names (header row of csv file + ID field)
tabFieldNames:
CrossTable (oldFieldName,newFieldName)
LOAD 1,*,'ID' as @$(vIDColumn)
FROM QlikCommunity_Thread_202456_v2.csv (txt, codepage is 1252, no labels, delimiter is ';', msq)
Where RecNo()=1;
// create mapping table to translate default field names (@1 to @n) to column headers of csv file
mapFieldNames:
Mapping LOAD oldFieldName, newFieldName
Resident tabFieldNames;
// drop temporary tables
DROP Tables table1, tabFieldNames;
// rename fields using the previously generated mapping table
RENAME Fields using mapFieldNames;
hope this helps
regards
Marco
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
You can use the function Subfield() to manually parse the field from your file with the delimiter.
For example,if you know that next field is e-mail address,therefore the next field should be checked for the presence of the char '@' .
if(subfield(@1,';',5) like '*@*',subfield(@1,';',4),
if(subfield(@1,';',6) like '*@*',subfield(@1,';',4) & subfield(@1,';',5)... as description
if(subfield(@1,';',5) like '*@*',subfield(@1,';',5),
if(subfield(@1,';',6) like '*@*',subfield(@1,';',6) ... as e_mail
It works fine if your field 'description' is the one of the last fields in your input file,
otherwise, all fields after 'description' mustbe processing through 'if' statement.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Unfortunately it is one of the first fields in the file.
Mhh.. is there any other way to overcome it?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Can you use quoting when you export the data to the csv-file? Like embedding each field value into double quotes:
"10"; "20"; "Text; with semi;colon"
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
No, I can't change the source file. I have to use it as it is. Unfortunately..
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Probably skip those line using a where condition
where SubStringCount(yourTextLine,';')>20
and you can write the lines where count of semicolon in the text is more than 20, into a different table or a log file for possible analysis and rectification.
Best solution would be to change the delimiter in your source file
HTH
Sasi
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Sasi,
how can I reference a whole textline in a CSV for a where clause like in your example as Qlikview already seperates the line of text by semicolon while loading. I'm not sure yet how to use it properly, you understand? But I understand your idea.
I know that to change the delimiter is the best solution, this was also my first idea, but not possible in this case.
Kind regards,
Seb
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi
Try like in the attachement.
SET vDel=';';
Temp:
LOAD @1
FROM
(txt, codepage is 1252, no labels, delimiter is '@', msq)
where SubStringCount(@1,'$(vDel)')<=20;
FinalTable:
Load
subfield(@1,'$(vDel)',1) as Column1,
subfield(@1,'$(vDel)',2) as Column2,
subfield(@1,'$(vDel)',3) as Column3
Resident Temp;
drop Table Temp;
hth
Sasi
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi,
one solution might be:
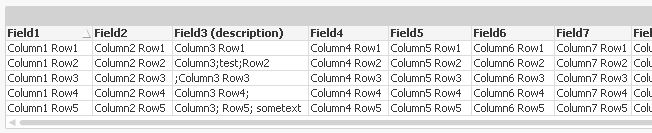
using this csv file:

table1:
LOAD Left([@1:n],Index([@1:n],';',2))&'"'&Mid([@1:n],Index([@1:n],';',2)+1,Index([@1:n],';',SubStringCount([@1:n],';')-16)-Index([@1:n],';',2)-1)&'"'&Mid([@1:n],Index([@1:n],';',SubStringCount([@1:n],';')-16)) as line
FROM QlikCommunity_Thread_202456.csv (fix, codepage is 1252)
Where RecNo()>1;
table2:
LOAD *
From_Field (table1, line) (txt, codepage is 1252, no labels, delimiter is ';', msq);
tabFieldNames:
CrossTable (oldFieldName,newFieldName)
LOAD 1,*
FROM QlikCommunity_Thread_202456.csv (txt, codepage is 1252, no labels, delimiter is ';', msq)
Where RecNo()=1;
mapFieldNames:
Mapping LOAD oldFieldName, newFieldName
Resident tabFieldNames;
DROP Tables table1, tabFieldNames;
RENAME Fields using mapFieldNames;
hope this helps
regards
Marco
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Very nice solution Marco, your fixing bad source file formatting on the fly. I think it will be extremely difficult to find a simpler solution.
Peter
- « Previous Replies
- Next Replies »