Unlock a world of possibilities! Login now and discover the exclusive benefits awaiting you.
- Qlik Community
- :
- Forums
- :
- Analytics
- :
- New to Qlik Analytics
- :
- Average on count of the whole loaded data
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Average on count of the whole loaded data
Hi. I'm trying to calculate average value on count of a field so that it would take the whole loaded data.
For example, I need to take average on count of sales by date. This works fine unless I apply filters:
Avg(Aggr(Count(sales), date))
If I apply filtering, the average will be recalculated, but I need it to be constant among the whole data. So I tried using
Avg(ALL Aggr(Count(sales), date))
But it didn't work. Is that possible at all in QlikSense without primary grouping on query level?
Any help is highly appreciated.
Thanks in advance!
- « Previous Replies
-
- 1
- 2
- Next Replies »
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hello Sunny,
Could you please explain the syntax of this formula in more detail. It became quite complicated now. For example, if I need to add more fields to aggregation, I have to understand each single part very well.
I tried to decompose it to several levels as follows:
Aggr
(
NODISTINCT
Avg
(
{1}
Aggr
(
Count
(
{1}
tran
),
[dt.autoCalendar.Month],
dt
)
),
[dt.autoCalendar.Month]
)
My questions are:
- The outer Aggr function has two parameters as Avg and [dt.autoCalendar.Month]. Why not three parameters as inner Aggr? What is attribute NODISTINCT for in front of Avg function?
- What does attribute {1} mean near the inner Aggr function?
- Inner Aggr function has three parameters. Why are there [dt.autoCalendar.Month] and dt at the same time? Does it mean that we aggregate by month and date field?
- Similar question to 2 about attribute {1} inside Count function.
Thank you in advance.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
My questions are:
- The outer Aggr function has two parameters as Avg and [dt.autoCalendar.Month]. Why not three parameters as inner Aggr? What is attribute NODISTINCT for in front of Avg function?
Not sure I follow the first part of the question, but you can read about NODISTINCT here What NODISTINCT parameter does in AGGR function?
2. What does attribute {1} mean near the inner Aggr function?
It is just set analysis used to ignore selections. Read about set analysis here Set Analysis: syntaxes, examples
3. Inner Aggr function has three parameters. Why are there [dt.autoCalendar.Month] and dt at the same time? Does it mean that we aggregate by month and date field?
The best way to understand Aggr() function is to create a straight table with Aggr() dimensions as your dimension and inner expression within Aggr() as your expression. The challenges of getting the right average is what made me choose the expression...
4. Similar question to 2 about attribute {1} inside Count function.
Same reason as 2. above
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hello Sunny,
I came across one more challenge with this issue. I need to include store identifier into the existing aggregation. So now it should display averages by months independently on selections, except for selection of a store. In the attached example I added data for two stores. Using the following formula (just added store_id as aggregation parameter) I found that it shows correct monthly averages if each store is selected separately:
Aggr(NODISTINCT Avg({1} Aggr(Count({1} tran_id), [date.autoCalendar.YearMonth], date, store_id)), [date.autoCalendar.YearMonth], store_id)
But when I select both stores, it goes completely unpredictable. Please see the screenshots below:
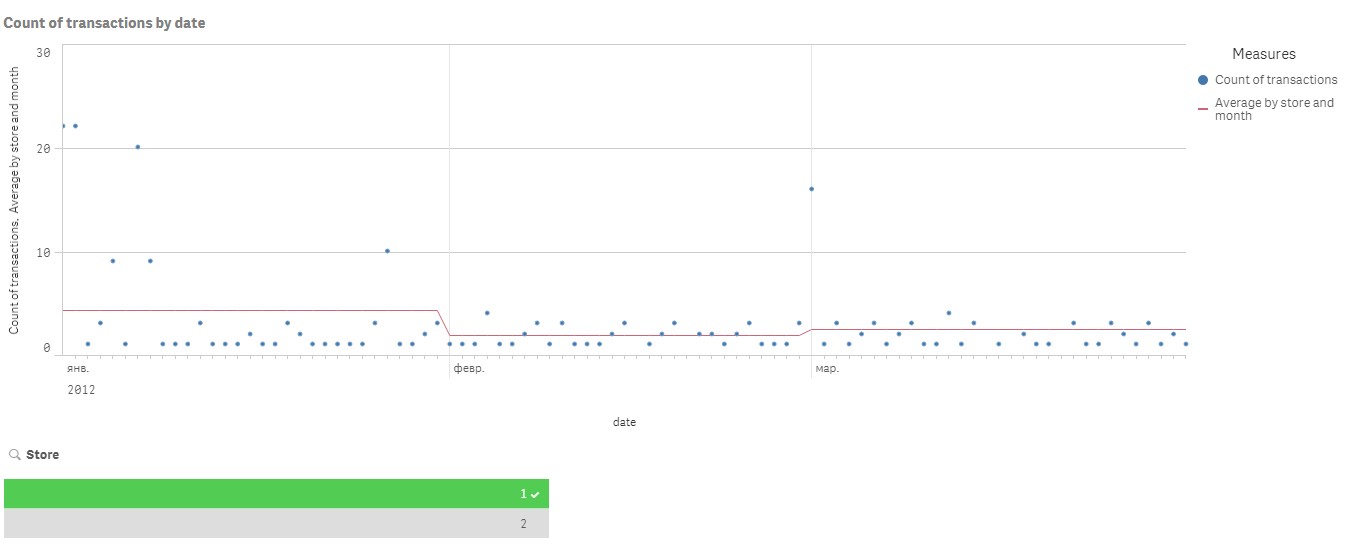
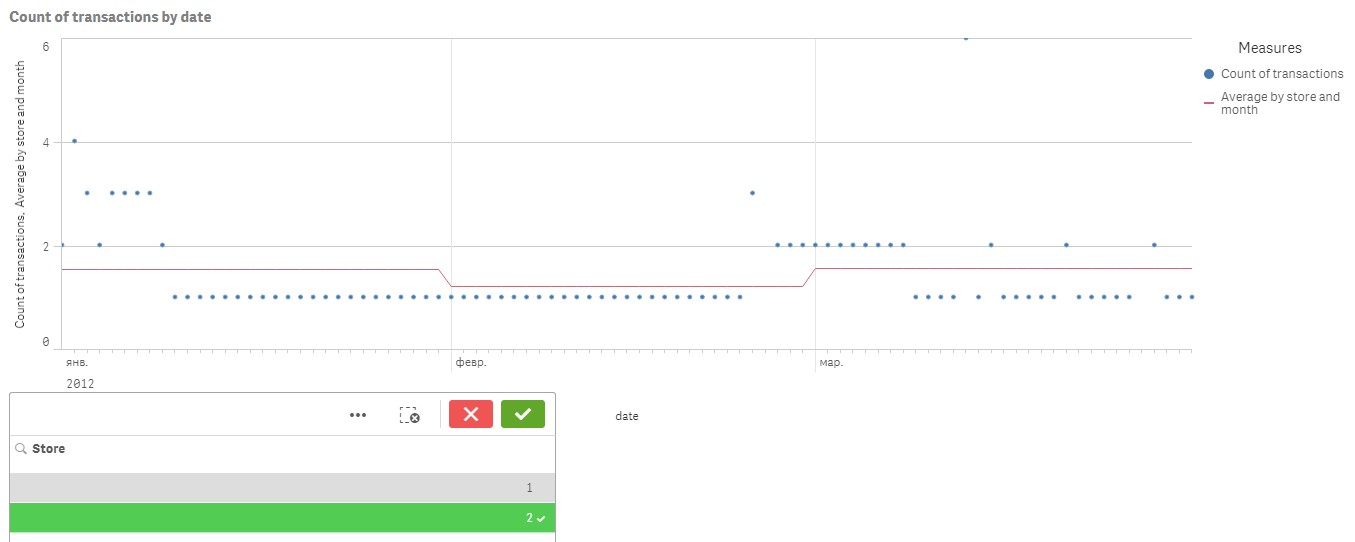
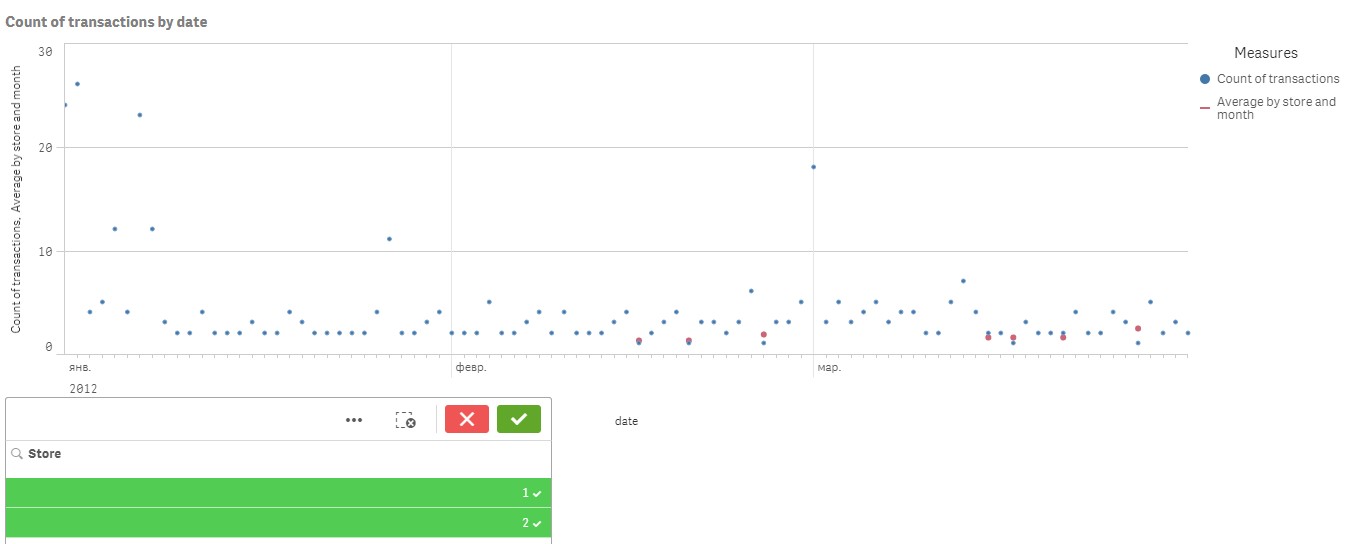
Is there a way to show correct monthly averages when both stores are selected?
Thanks in advance.
- « Previous Replies
-
- 1
- 2
- Next Replies »