Unlock a world of possibilities! Login now and discover the exclusive benefits awaiting you.
- Qlik Community
- :
- Forums
- :
- Analytics
- :
- New to Qlik Analytics
- :
- Re: Fine tuning qvd files?
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Fine tuning qvd files?
Hi All,
I have two table which are QVD load InvoiceXtable(20M Rows) & CallData(6M Rows) are two big tables in the datalayer.
I want to tune the above two table. what is the best solution for tuning the table..
For reference, please find the attached screenshot
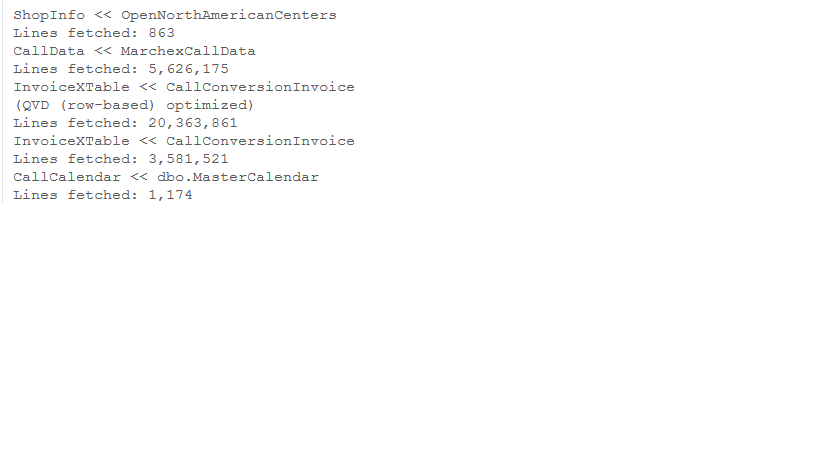{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
There is not much one can do re tuning QVD files.
Except maybe partition them into seperate monthly QVD's, but could well mess up any incremental loads.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Uses Exists and not Exists condition or Group by aggregation function to reduce the Rows and size.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
You can make sure that the QVD doesn't contain fields that you are not using. Also, and date/time fields where you don't need the time you can make them just dates and drop the times.
Other than that there is not a lot you can do on the front end to make them smaller.
Also, those sizes are not really what I would consider large.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
hi
count(distinct IF(InvoiceDateDT - CallDateDT >= 0 and InvoiceDateDT - CallDateDT <= $(vConversionLimit), CallerNumber)) / count(distinct CallerNumber)
Is the above expression gives bad performance? If yes, please suggest how we can modify above expression?
Thanks,
Siva
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
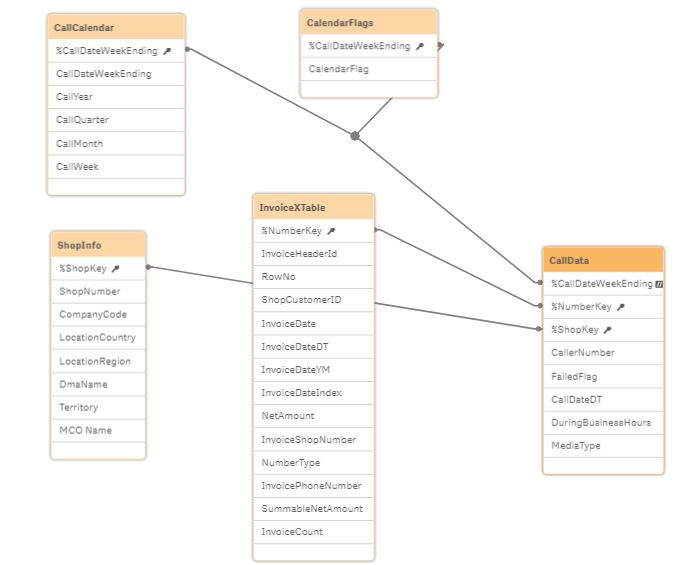
I assume InvoiceDateDT and CallDateDT are in different tables in your data model and doing calculations across a join between two tables is resource hungry and hence slow.
Could you post a screenshot of your data model ?
Also what is in your variable vConversionLimit ?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
!
vConversionLimit=14
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Better would be to put the condition on the outside of the aggregation and not the inside. I mean:
IF(InvoiceDateDT - CallDateDT >= 0 and InvoiceDateDT - CallDateDT <= $(vConversionLimit),
count(distinct CallerNumber), 0) / count(distinct CallerNumber)
- Marcus
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
If Marcus's suggestion does not give you enough improvement then think about concatenating your tables InvoiceXTable and CallData together, thus creating a classic star schema with a single central fact table.
You will need to think carefully before doing this, as there may be implications dependent on what your front expressions are.