Unlock a world of possibilities! Login now and discover the exclusive benefits awaiting you.
- Qlik Community
- :
- Forums
- :
- Analytics
- :
- New to Qlik Analytics
- :
- Re: Group By not working as I would expect
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Group By not working as I would expect
!
Hello -
I have the following table:
| ID | Start Date | active_date | Contact Date |
| 4e1205d9-439a-48d2-bf86-49c9d413652f | 6/20/2013 | 5/24/2018 | 2/10/2018 |
| 4e1205d9-439a-48d2-bf86-49c9d413652f | 6/20/2013 | 5/24/2018 | 3/17/2018 |
| 4e1205d9-439a-48d2-bf86-49c9d413652f | 6/20/2013 | 5/24/2018 | 3/31/2018 |
I want to figure out how many times a contact occured before/after the start/active dates.
I have the following script
load
NoConcatenate
"ID",
sum(if("Contact Date" <= [Start Date],1,0)) as calls_before,
sum(if("Contact Date" > [Start Date] and "Contact Date" < "active_date",1,0)) as calls_after,
sum(if("Contact Date" > date("active_date"),1,0)) as calls_after_discharge,
count("Contact Date") as total_calls
resident res_contacts
group by "ID";
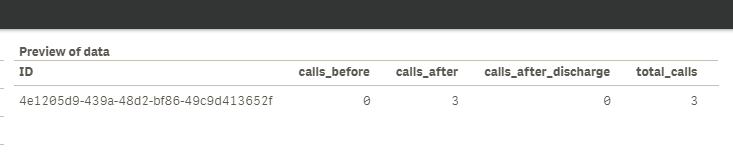
My expectation would be I would get a single row like this
| ID | calls_before | calls_after | calls_after_discharge | total_calls |
| 4e1205d9-4 !39a-48d2-bf86-49c9d413652f | 0 | 3 | 0 | 3 |
However, what I get is
| ID | calls_before | calls_after | calls_after_discharge | total_calls |
| 4e1205d9-439a-48d2-bf86-49c9d413652f | 0 | 9 | 0 | 9 |
I'm coming from a SQL background so this grouping behavior doesn't make sense to me. I've made sure there is not assoications or linkings inside the application to make sure I'm not getting a cartesian product. Even in Data Manager it shows the wrong values.
!
- « Previous Replies
-
- 1
- 2
- Next Replies »
Accepted Solutions
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
The last grouping doesn't removes duplicates because you are doing a count of a field that has a value, so all rows will be counted, duplicated or not...
Before group by:
UniqueID, Contact Date
1, 01/01/0217
1, 01/01/0217
1, 01/01/0217
After group by:
UniqueID, Total_calls
1, 3
There are 3 rows to counts, doesn't matter if they have the same values, if you do a count the result is '3', maybe counting different UniqueId with:
Count(Distinct UniqueID&[Contact Date]) as total_calls
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi,
If you want to achieve this in the script, below is a solution. No doubt there is a more elegant way to get the same result, but it's late here and I should sleep 😉
TEMP:
load * inline [
ID, Start Date, active_date, Contact Date
4e1205d9-439a-48d2-bf86-49c9d413652f, 6/20/2013, 5/24/2018, 2/10/2018,
4e1205d9-439a-48d2-bf86-49c9d413652f, 6/20/2013, 5/24/2018, 3/17/2018,
4e1205d9-439a-48d2-bf86-49c9d413652f, 6/20/2013, 5/24/2018, 3/31/2018
];
FINAL:
LOAD ID,
only(active_date) as active_date,
only([Start Date]) as [Start Date]
Resident TEMP group by ID;
left join(FINAL)
LOAD ID,
Count([Contact Date]) as calls_before
resident TEMP
where [Contact Date]<=[Start Date]
group by ID;
left join(FINAL)
LOAD ID,
Count([Contact Date]) as calls_after
resident TEMP
where [Contact Date]>=[Start Date] and [Contact Date]<=active_date
group by ID;
left join(FINAL)
LOAD ID,
Count([Contact Date]) as calls_afterDischarge
resident TEMP
where [Contact Date]>=active_date
group by ID;
drop table TEMP;
exit script;
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Not a solution, but with qlik, you might not want to pre-aggregate/cube data like this in your script. Generally, such things are done in the UI.
BUT, if I had to do it, I would do something like this. It appears that with the test data, that I'm getting the expected values.
Chughes:
LOAD ID,
Date(Date#(start_date_text,'M/DD/YYYY')) AS 'start_date',
Date(Date#(active_date_text,'M/DD/YYYY')) AS 'active_date',
Date(Date#(contact_date_text,'M/DD/YYYY')) AS 'contact_date'
;
LOAD * Inline
[
'ID', 'start_date_text', 'active_date_text', 'contact_date_text'
'4e1205d9-439a-48d2-bf86-49c9d413652f', '6/20/2013', '5/24/2018', '2/10/2018'
'4e1205d9-439a-48d2-bf86-49c9d413652f', '6/20/2013', '5/24/2018', '3/17/2018'
'4e1205d9-439a-48d2-bf86-49c9d413652f', '6/20/2013', '5/24/2018', '3/31/2018'
]
;
Final:
NoConcatenate
LOAD ID,
SUM( If( contact_date < start_date, 1 , 0 )) AS 'calls_before',
SUM( If( contact_date > start_date and contact_date < active_date, 1 , 0 )) AS 'calls_after',
SUM( If( contact_date > active_date, 1 , 0 )) AS 'calls_after_discharge',
Count(contact_date) AS 'total_calls'
Resident Chughes
GROUP BY ID
;
DROP TABLE Chughes
;
EXIT Script
;
Are you absolutely positive that your quotes and so forth are acting correctly?
Hope this helps.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi -
This is currently what I'm doing actually. The pre-aggregation in the script.
I'm baffled how you are getting a different value... Just for giggles I copied your exact code into my app and I still get 9.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi,
Perhaps your raw data are duplicated ?
Add a Rowno() as ID in your table to check you source table
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
This is what is confusing me. Shouldn't the group by ID resolve that? Or does Qlik do some kind of joining or processing that I'm not understanding
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
The table "final_contacts" is where I'm getting the duplicate values. What seems to be happening is the detail records in program_data seem to be causing duplicates.
I'm about to just import these CSV files into SQL and write the query I know will work. But I'm stubborn and want to learn how the joins in QLIK work.
There are no tables loaded in the GUI/Data manager. Everything is loaded via the script
Here is my code:
Person_Header:
LOAD
DISTINCT
"Full Name - First Name First",
"First Name",
"Last Name",
"Unique ID"
FROM program_data.csv;
Program_Data:
LOAD
"Program Name",
"Program Timeline Date",
"Program Timeline Active Status",
"Program Current Status",
"Program Timeline Status Description",
"Unique ID"
FROM program_data.csv
Person_Contacts:
LOAD
"Contact Date",
"Unique ID"
FROM cpm_contacts.csv
Person_Aggregate:
LOAD
date(min("Program Timeline Date")) as [Start Date],
if(WildMatch(Firstsortedvalue(DISTINCT [Program Timeline Status Description],[Program Timeline Date]),'Pending Enrollment','Inactive')
and WildMatch(Firstsortedvalue(DISTINCT [Program Timeline Status Description],-[Program Timeline Date]),'Pending Enrollment','Inactive'),'Never Active','Was Active') as CPM_Involved,
date(if(wildmatch(Firstsortedvalue(DISTINCT [Program Timeline Status Description],-[Program Timeline Date]),'Active'),date(now()),date(max([Program Timeline Date])))) as active_date,
"Unique ID"
resident Program_Data
group by "Unique ID";
res_contacts:
NoConcatenate
LOAD
"Unique ID",
date#(min("Program Timeline Date")) as [Start Date],
if(WildMatch(Firstsortedvalue(DISTINCT [Program Timeline Status Description],[Program Timeline Date]),'Pending Enrollment','Inactive')
and WildMatch(Firstsortedvalue(DISTINCT [Program Timeline Status Description],-[Program Timeline Date]),'Pending Enrollment','Inactive'),'Never Active','Was Active') as CPM_Involved,
date#(if(wildmatch(Firstsortedvalue(DISTINCT [Program Timeline Status Description],-[Program Timeline Date]),'Active'),date(now()),date(max([Program Timeline Date])))) as active_date
Resident Program_Data
group by "Unique ID";
left join(res_contacts)
LOAD "Unique ID",
"Contact Date"
Resident Person_Contacts;
Final_Contacts:
load
"Unique ID",
sum(if("Contact Date" <= [Start Date],1,0)) as calls_before,
sum(if("Contact Date" > [Start Date] and "Contact Date" < "active_date",1,0)) as calls_after,
sum(if("Contact Date" > date("active_date"),1,0)) as calls_after_discharge,
count("Contact Date") as total_calls
resident res_contacts
group by "Unique ID";
Drop Table res_contacts;
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Chris, Person_Contacts or Program_Data has more than one row for a UniqueId it wil cause duplicates in the left join of rec_contacts.
Possible solutions can be:
- Create a concatenated key to have an unique id per person-program (it it's any data that needs to keep the differences)
- Use applymap instead of join
- Do a group by or load distinct before Final_Contacts to remove duplicates
- ... Knowing what you want to do and the data behind more solutions are possible
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thank you very much for your response. I thought that's what I was doing with the group by. So how can I compare contact_date for a person as I'm trying to do in final contacts without having duplicates? Seems the grouping I have already in final contacts would accomplish this
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
The last grouping doesn't removes duplicates because you are doing a count of a field that has a value, so all rows will be counted, duplicated or not...
Before group by:
UniqueID, Contact Date
1, 01/01/0217
1, 01/01/0217
1, 01/01/0217
After group by:
UniqueID, Total_calls
1, 3
There are 3 rows to counts, doesn't matter if they have the same values, if you do a count the result is '3', maybe counting different UniqueId with:
Count(Distinct UniqueID&[Contact Date]) as total_calls
- « Previous Replies
-
- 1
- 2
- Next Replies »