Unlock a world of possibilities! Login now and discover the exclusive benefits awaiting you.
- Qlik Community
- :
- Forums
- :
- Analytics
- :
- New to Qlik Analytics
- :
- Re: % of the column total in Pivot table
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
% of the column total in Pivot table
Hi All,
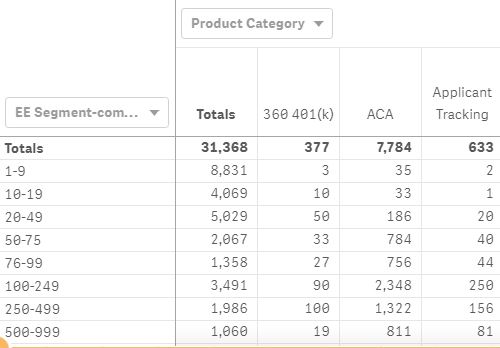
I have a pivot table with column called Product Category and row called EE Segment. I have created a measure that counts # of Clients by using: count(distinct([Client ID])). This measure gives me # of clients in each Product Category by EE Segment. I also have totals by EE Segment in Pivot table. Now I want to create a measure in the pivot table where I can get % for each Product. i.e #of clients in each Product Category by EE segment/total clients in each EE segment.
Please see attached picture of the pivot table.
I would appreciate if I can get ideas of how to create the measure
Thanks and Regards,
Monica
{kind=link}
- « Previous Replies
-
- 1
- 2
- Next Replies »
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
May be this:
Count(DISTINCT [Client ID])/Count(DISTINCT TOTAL <[EE Segment]> [Client ID])
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Awesome it worked, Thank you Sunny.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Or you might want to consider the "Qlik" way, which will give you some food for thought on the AGGR function:
Count(DISTINCT [Client ID]) / AGGR(NODISTINCT Count(DISTINCT [Client ID])), [EE Segment]).
If the "nodistinct" is not used, Qlik only returns one value at row level, at random, at the node level. The NODISTINCT ensures that the value is in all rows at the node level.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Curious to know what is so 'Qlik' about using Aggr() function  . Besides, I have never heard anyone vouch for Aggr() over TOTAL Qualifier . Here is a link which goes over the two options, may be useful for OP: Qlik Tips: No nodistinct
. Besides, I have never heard anyone vouch for Aggr() over TOTAL Qualifier . Here is a link which goes over the two options, may be useful for OP: Qlik Tips: No nodistinct
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
There is absolutely nothing wrong with your solution, it is entirely correct. In v8.5 and v9 your solution was the only way until Qlik introduced the AGGR() function. This is why the quotation marks around "Qlik" when mentioning the '"Qlik" way'. I didn't realised I was vouching for AGGR over TOTAL. I think you might have misread my comment. As noted, the mention of AGGR (and the NODISTINCT) is "food for thought", i.e. it has uses elsewhere. Perhaps you are right. Qlik introduced the AGGR function for no reason at all since TOTAL qualifier exists.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Apologize my response wasn't appropriate. I know you did not say that my expression was incorrect. But what I was trying to get at was the fact that, have you seen any performance benefits of Aggr() over TOTAL Qualifier? I have not done any testing, but from my little experience with QlikView, I have found that Aggr() slows down things. If that's true, why would we use Aggr(), if we can get the same thing using TOTAL.
With regards to bringing that option, I have no idea why they bring that option. May be because there has been other uses cases where TOTAL Qualifier won't work (like for instance with Rank function).
Best,
Sunny
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Sunny,
Actually you are right. Check this: Total vs AGGR()
Total quali is apparently more efficient than AGGR. When I used to teach Qlik on v8.5/9, we (Qlik trainers) taught the 'TOTAL' and when Qlik introduced AGGR, a number of us differentiated the two as "TOTAL" being the 'SQL equivalent of group by' and AGGR the new 'Qlik' way. My bad, I let my own training get in the way. The loss of transmission in written communication could perhaps lead to thinking that by putting quotes around "'Qlik' way" was an allusion to the 'right' way, as opposed to my own doubts as to whether there is a 'better' way for any of our coding - which was the reason for the quotes. I don't profess 'a better way' and I don't need to, as I don't sell Qlik anymore.  Whatever works, works. And in this case, you're entirely right. TOTAL seems like a more resource efficient method. So thank you for sparking up this discussion. Cheerio
Whatever works, works. And in this case, you're entirely right. TOTAL seems like a more resource efficient method. So thank you for sparking up this discussion. Cheerio
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Its an honor to speak/discuss and learn from someone who has been using and teaching Qlik for a while now.
Best,
Sunny
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Maybe Monica. you can now close this discussion by marking the answer right:-)
- « Previous Replies
-
- 1
- 2
- Next Replies »