Unlock a world of possibilities! Login now and discover the exclusive benefits awaiting you.
- Qlik Community
- :
- Forums
- :
- Analytics
- :
- New to Qlik Analytics
- :
- versioning and automated documentation
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
versioning and automated documentation
Hello,
I need to implement version control and possibly automated documentation for qlikview and sense in a small coworking environment.
I would like to:
- have a procedure that can allow multiple people to work on a project with no fear of saving over each other's work, (development -> staging -> production )
- avoiding scattered "archives" folders
- a tool for genereting documentation
So far I found only old postsin the community (2014 or before) while I think there are several new tools we can choose from. Sadly I have no idea what to choose between them so if anyone want to share his experience in this matter is welcome 
thanks
- « Previous Replies
- Next Replies »
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Qlik Sense apps are stored in a GUID encrypted form filenames and the names of applications are stored in qlik sense repository database. Some other metadata are also stored in the repos. Sense use a hybrid file / database system
Qlik Sense it not anymore like Qlik View file based and deploying / Publishing need to call the Rest API
It's why we have developed WIP (and before Version Manager) and that we have a growing number of customers because it's very difficult or quite impossible to do source control and deployment in Sense without such tools.
Contact us once you need something for Qlik Sense we can help for sure
JP
With WIP, Control everything!
Qlik Sense, QlikView and NPrinting Source control, Versioning and Deployment, Agile Lifecycle Management
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thanks, Richard,
When you put the reduced qvw file in Clear Case, can you then see the specific changes between versions?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Erik,
no we can't see the differences.
We discussed it several times but have heterogenic developer styles and not a full .qvs modular (include) approach within the .qvw files.
I trained in the way that inline code documentation and comment in Clear Case with labeling have to fit together to identify the right version. You have to proof that in your quality gateway too.
As long as the vendor does not split script code, data and layout into separate files / database it will be difficult to diff versions.
Thanks,
Richard
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
We use different branches, and labels of course, to know what resides on each server. That gives us full control. Also being able to diff the apps in different versions is great help when searching for.. abnormal behaviour. 🙂
It also helps when we do peer reviews. Then we can see exactly what is new and what is changed.
When it comes to Sense, we're still a bit in the dark. We want to work in the same way but we have not quite been able to bend it to our will yet.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
May I ask how you were able to extract and restore images?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
We don't use prj files only qvw files that we reduce data fully or keeping possible values in certain conditions.
Like this we keep the document integrity not loosing anything you will loose using .prj method.
The we scan the document to see differences and can even visual compare the graphs images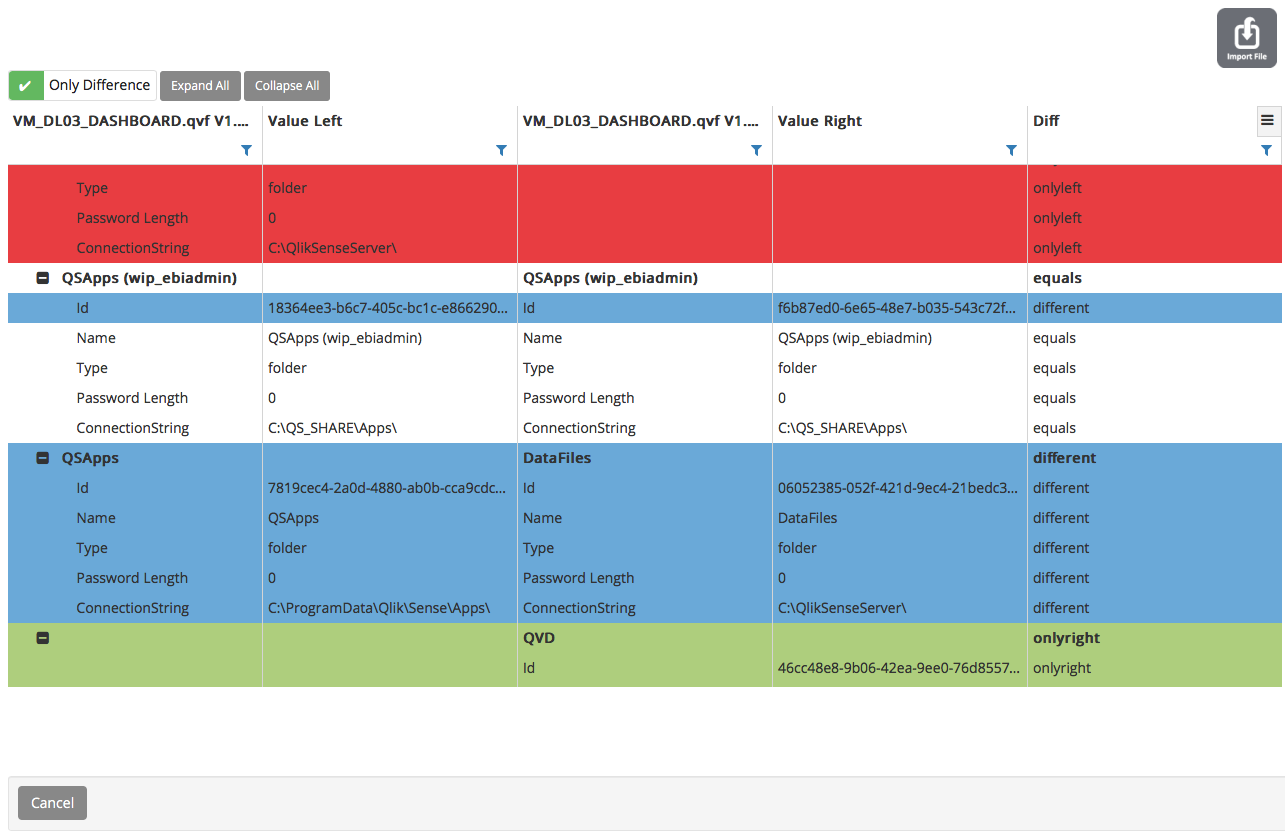
With WIP, Control everything!
Qlik Sense, QlikView and NPrinting Source control, Versioning and Deployment, Agile Lifecycle Management
- « Previous Replies
- Next Replies »