Unlock a world of possibilities! Login now and discover the exclusive benefits awaiting you.
- Qlik Community
- :
- All Forums
- :
- QlikView App Dev
- :
- Comparing two Datasources for differences
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Comparing two Datasources for differences
I have two data sources, one from Teradata and the other from Excel. All column names are aligned across these two data sets. I am loading both sources into my Dashboard and as expected QV is Joining them together.
If I was working in one database I could execute a Union All on these data sources and Group By every column with a Count to determine which records don't exist in both sources, i.e. count = 1, rather than 2. Wondering if there is a simple solution to this use case utilizing Qlikview?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
you can use Qualify for the data loading.
And use Unqualify for the common dimension (attributes) to compare figures
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I think you can do the same thing (or get the same result) in Qlik,see attachment
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
In ur load script for each table, have an extra column which can identify the table from which u r loading the data,
something like
TableA:
Load
'TableA' as Tablename,
A,
B,
C
From xyz
TableB:
Load
'TableB' as Tablename,
A,
B,
C
From xyz
Now in ur dashboard have all the columns in a pivot table with count of , you can easily identify in which table what data is missing
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Massimo, Thanks for the response; that looks like what I am trying to accomplish!. Unfortunatly I'm using the free desktop client and can't open your .qvw. We are still evaluting purchase of QV license. Can you please supply a screen shot of your object expression.
Many Thanks,
Lew
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
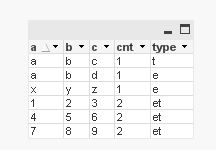
this is the script; I did all in the script, trying to replicate your sql in database
the object is a table box, just fields, no dims or expressions
teradata:
load * inline [
a,b,c
1,2,3
4,5,6
7,8,9
a,b,c
];
excel:
NoConcatenate load * inline [
a,b,c
1,2,3
4,5,6
7,8,9
x,y,z
a,b,d
];
t:
load *, 't' as type resident teradata;
Concatenate (t) load *, 'e' as type resident excel;
DROP table teradata, excel;
g:
load
a,b,c, count(type) as cnt, concat(type) as type
Resident t
group by a,b,c;
DROP Table t;
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Mahesh, My load is just as you have described, just not sure what the expression would be that would group by all columns to get the count of duplicates.