Unlock a world of possibilities! Login now and discover the exclusive benefits awaiting you.
- Qlik Community
- :
- All Forums
- :
- QlikView App Dev
- :
- Fact table not changed, Dimension table got new va...
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Fact table not changed, Dimension table got new values but how it is creating variance in my result ???
i Have a Qvd called Flat_agg and am restoring that in an another path by adding a new column called Type
and the new column is with a default value like this 'UNKNOWN' as TYPE.
ex:
flat_agg:
Load
A,
B,
C,
'UNKNOWN' as TYPE
from C:/Old_Qvd/Flat_agg.Qvd
Store flat_agg into C:/Old_Qvd/STP/Flat_agg_new.Qvd
now we have to change the Qvd path for my Main Qlik app and have to use the new Qvd which generated above.
(i have a backup of my main Qlik app inroder to compare with new Qlik app)
when i use the above Qvd in Qlik app and compare it with the backup Qlik app, its giving slight variance.
(below >1% only) but still they have to match right ?? as they are using the same fact Qvds
but different dimension table (dimension table have some updates like few new dimensions are added).
Was bit shocked from where that variance is coming.. please help me with your thoughts. if a dimenstion qvd is
changed is it create that variance even though the fact qvd is same.
and how the new values added in dimension table will effect the existing combinations between fact and dim...???
Note : we did the same kind of above process to another apps which use the same dimension tables.
we are perfectly matching with backup Qvws in those cases..
Some Experts can look into this please some one like petter-s or stalwar1 please look into above... Thanks much.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
What exactly do you mean when you say Variance? Can you elaborate on the differences you saw?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
If the dimension contains non-unique keys, then an object using the unchanged facts table and that dimension could land up double counting the associated items.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thanks for the reply sunny,
Below same expression used in both apps:
count(distinct {<$(vSelectCohortM0), SnapshotDate=>} SUB_ID) -- volumeMO Exp
count(distinct {<$(vSelectCohortM0)>} SUB_ID) -- volume Exp
vSelectcohortMO variable value is below :
SUB_ID=P({1<First_Connection_Month={"$(=concat([CohortDateKey],'","'))"}
,BASE_CATEGORY_NAME={"$(=concat([BaseCategoryHad.BASE_CATEGORY_NAME],'","'))"}
,TARIFF_KEY={"$(=concat([TariffHad.TARIFF_KEY],'","'))"}
>}),MONTH_KEY={">=$(=vFirstCohortDate)"}
please find the below image for the diff.
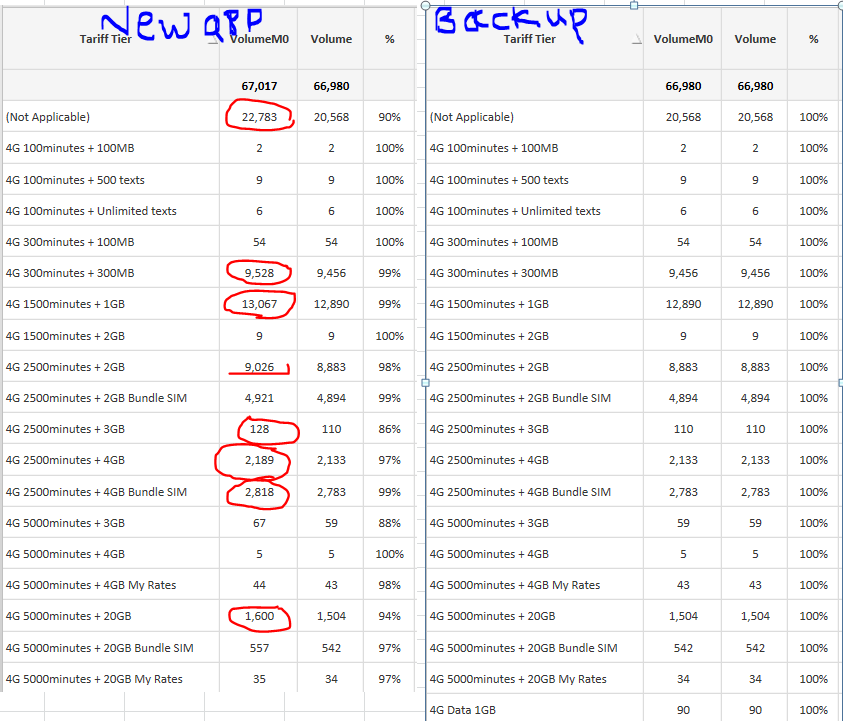
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Sunny Talwar,
please find the attached images below for the variance. new app and back up..
New app uses the Latest dimension table and new Fact Qvd(after adding a new column to the old fact qvd).
where as the backup qvd uses the old fact and old dimension tables..
my other doubt is that :
how a new value which is added in a dimension will change the matching values of the old dimension and fact table...
ex:
| Dim | Fact | ||||
| Emp Id | Category | Emp ID | Sal | ||
| 101 | A | 101 | 10000 | ||
| 105 | B | 105 | 12000 | ||
| 110 | C | 110 | 15000 | ||
| 120 | C | 120 | 1400 | ||
in above example how adding a new dim (Emp Id 120) is effecting the counts in the resultant table.. my understanding is that they should not make any diff to the existing records only the new records will get new values as per the addition of them in dim table.. please correct me if my understanding is not correct...
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
In this above example.... what exactly are you counting?