Unlock a world of possibilities! Login now and discover the exclusive benefits awaiting you.
- Qlik Community
- :
- All Forums
- :
- QlikView App Dev
- :
- Incremental Loads are dead, long live the CSV
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Incremental Loads are dead, long live the CSV
Hi Qlikers
The days of incremental loads are gone, there is a new kid on the block and its name is CSV's, whoa hold on a minute "how so ?" you ask.
I hope that your sitting comfortably, if so then I shall begin.
Twas a rainy Monday morning and this particular 35M record QVD finally snapped and to rebuild it from scratch took just over three and a half hours, which is not too bad I suppose, but we were not happy with that and with the demand for the latest up to date data we had a problem to solve.
We tried building chunked 1M record QVD's which still took three hours to build, so next we tried converting those chunked QVD's into CSV's and this is where the magic happend, when we imported those CSV's into Qlikview it took six minutes, hmmmm that's quick.
So a quick brainstorming session to find a way of expanding on the CSV approach, we came up with the following
- Run a PHP script that pulls data from the Database in small 10K chunks then save it as a CSV.
- Pick ranges based on a primary key and append to filename
- users_0-10000.csv
- users_10001-20000.csv
- users_20001-30000.csv
- Run the script on multiple instances - this took six minutes to build all CSV's.
- RSYNC the CSV's up to the Qlikview server.
- Run QVS script to build QVD's from the CSV's - this takes less than a minute to complete.
So now we have made a process where we add the table's we wish to build into an XLS file, and with a few clever enhancements to the process we can now rebuild all of our QVD's in less than an hour.
We experimented with with (RSYNC, FTP, SCP) for transporting CSV files, but found that SCP offered compression so we used it.
The team wish for this procedure to be called Batch Load, and it will be called always be called so, from this day forth.
Thanks to the team - Dave, Oke and Rich. Your Awesome.
- « Previous Replies
-
- 1
- 2
- Next Replies »
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
sounds good, we will try !!!
good job
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Spread the word, its a truly simple but effective concept.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Great post dave,
I've seen other approaches to this where they partition large QVDs. That way you aren't always rebuilding or incrementally refreshing the full breadth of one enormous QVD, just the pertinent portions (and once you climb up above the 1GB mark, the file handling times start to get noticeable). But the UI applications are fed an array of QVD slice vs. one giant glob. If databases are going to partition, why can't we? *hi-five*
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Dave,
thanks for pointing that out.
We have used CSVs to extract data from SAP before. It was a lot faster than via the SAP-Connector.
Regards
Tobias
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
next week we will post more details on the process, it's more complicated than my summary, it's beautifully executed.
the CSV's are a mirror of the db and if an older record get updated than that csv chunk also gets updated, which then uploads to the QV server, QV then refreshes the corresponding qvd, job done.
there is still some clever gems hidden inside that we will share with the community, your going to really enjoy.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
This sounds like a big breakthrough dave,
Btw, how much faster is the transfer rate from RDMS to CSV than the throughput of the ODBC or OLE connection?
I can't tell exactly from your description, but it sounds like getting the full dataset into CSV is much faster than ODBC throughput and you can dump the full extent of your large table from database to flat-file in 6 minutes.
And then it seems you have the .CSV load into QlikView at a speed that rivals load times of an optimized QVD series, this process is getting 35M rows of .CSV data into QVDs in under a minute? (Is this a "normal" size table? It's not just one column, is it?)
I gotta admit, I'm somewhat tempted to start telling all your friends & coworkers behind your back that you've been taking crazy pills, without having either seen and/or understood your idea, because... even in the event this preposterous sorcery works, and let's say you really did create something radically innovative and awesome. All that means is that now I'm the "former" developer of the "world's fastest incremental process" and well... where's the upside in that?
But... you, you've got charisma and enthusiasm, and that is just irresistible. Incremental loads have been around for a long time, but... turn me from a skeptic to a believer. More details please!!
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Evan
i promise to post a very detailed understandable description of the whole process on Monday, this is so awesome when you read on how it work it will blow your mind, we will provide you with actual benchmarks.
To see these files updating and rebuilding on the fly is something beautiful, we all know how long it takes roughly to build a 35m row 40 column database table from an odbc connection directly into QV and how painfully slow it is, but chunking the contents of the db table into small 10k shards externally of QV and through a php script that we can run and scale is blazingly fast.
Our senior dev thought it would take at least half an hour to run through, but when it built our most difficult and problematic table in six minutes his jaw dropped, we've really been on a roller coaster ride on this project and we want to show and tell the community of the fruits of our labour.
I'm really excited about this and wanted to give you all a quick taster, and follow it up with the main course, yum yum.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi All
Sorry for the delay in my response, but we have all been very busy.
Any ways trying to get the team to document anything is a difficult task, but they are aware the process needs documenting and are currently working on it.
I wanted to keep my end of the bargain up, so I've created some basic flow diagrams for you all to ponder over.
Diagram 1:
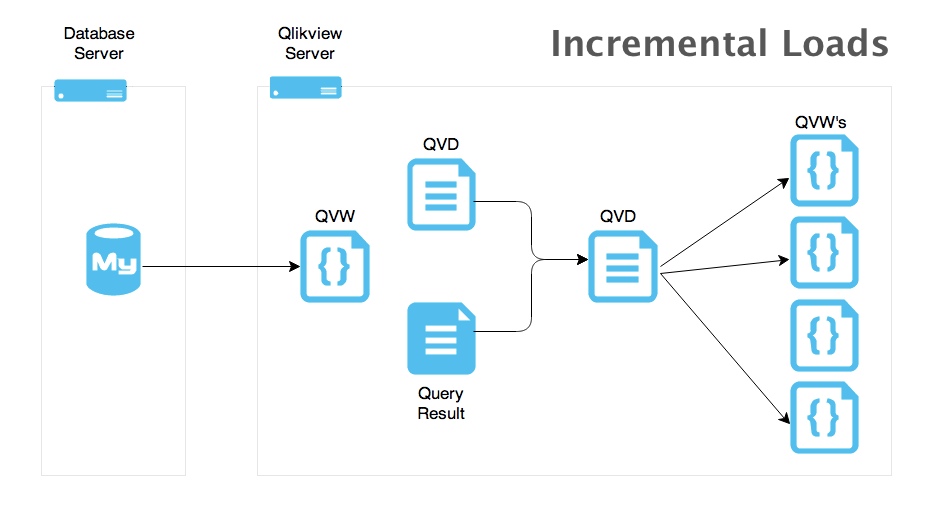
A standard incremental load diagram
- Import current QVD and get maxID.
- Qlikview QVW connects to ODBC which in turn connects to MySQL.
- Extract latest data and append to loaded QVD.
- Store as updated QVD.
- QVD ready to be used in multiple reports.
This process can start to get laggy as the QVD grows in size, and its a resource hog.
If we have to add a new column or rebuild the complete QVD the whole process for a particular QVD we had took 3.5 hours.
Diagram 2:
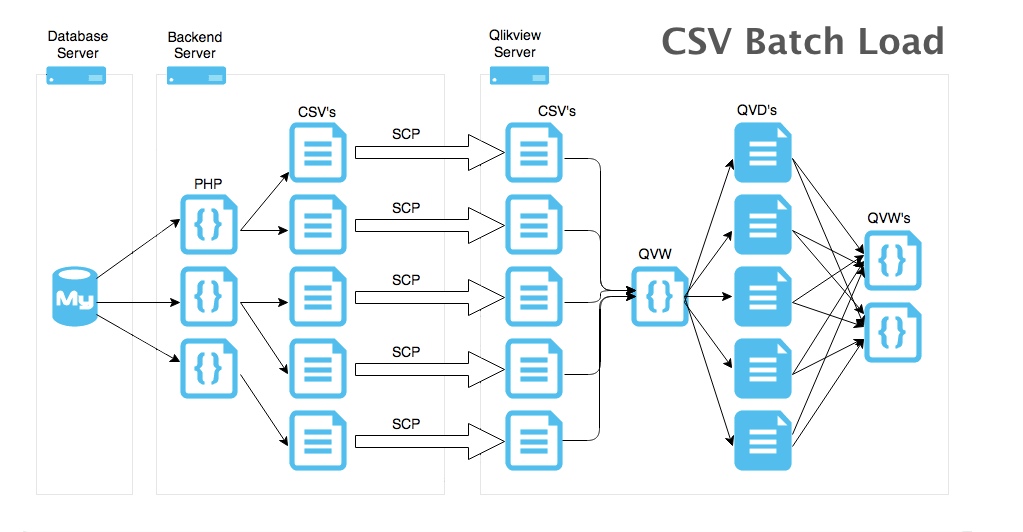
CSV Batch Load method diagram:
- Server side script connects to database and extracts small chunk of records from DB.
- Save small chunk of data as a CSV file.
- This is the great part, we can scale up the server side script and run more instances of it on multiple servers, currently we're running 6 scripts on 3 servers giving us 18 server side scripts to extract chunks from the DB, this is blazingly fast.
- SCP copies data to the Qlikview Server.
- QVW file loads all the CSV's with a wildcard.
- We process the CSV's and make any changes to the chunk of data.
- Store data as QVD's.
The process to extract 35 Million rows from the DB and save as CSV's took 4 minutes, then it takes 6.5 minutes for Qlikview to build all of the QVD's.
We have noticed that pulling in over 1,500 QVD's into a report is slow, so we still extract small chunks from DB, but now our Server Side Script builds larger CSV's, so now we have reduced the total CSV's to 69, which is much quicker to pull into our reports.
Also, where we process the data in step 6 it enables us to pull the optimised data into reports.
Yay, no more incremental loads.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Very nice, but why post as a question?
M.
- « Previous Replies
-
- 1
- 2
- Next Replies »