Unlock a world of possibilities! Login now and discover the exclusive benefits awaiting you.
- Qlik Community
- :
- All Forums
- :
- QlikView App Dev
- :
- Should I use one ID or multiple IDs?
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Should I use one ID or multiple IDs?
I have multiple Tables and I want to join them all. All tables shares a common ID at the moment but I am not sure if I should model for each relation a separate ID even if the ID is always the same for all tables.
For example I have T1, T2 and T3 all have the field ID. T2 and T3 can have multiple values for the same ID.
T1:
Load * inline [
ID, T1_VALUE
1, 1234567
2, 2345678
];
T2:
Load * inline [
ID, T2_VALUE
1, 100
1, 200
];
T3:
Load * inline [
ID, T3_VALUE
1, 20
2, 10
2, 40
];
This would produce the following table structure.
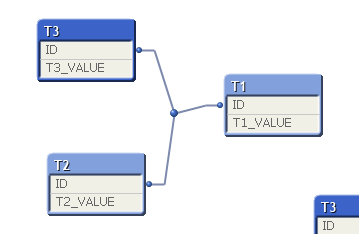
The other approach would be to have single id for each relation. T2 and T3 can have multiple values for the same ID.
T1:
Load * inline [
T2_ID, T3_ID, T1_VALUE
1, 1, 1234567
2, 2, 2345678
];
T2:
Load * inline [
T2_ID, T2_VALUE
1, 10
1, 40
];
T3:
Load * inline [
T3_ID, T3_VALUE
1, 20
2, 10
2, 50
];
This would leads to
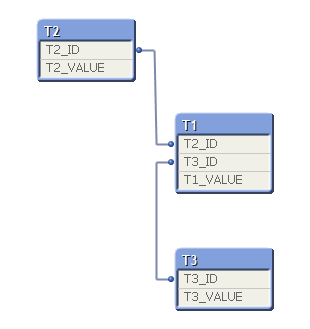
As far what I have seen this produces the same results (besides the new fields for the new IDs). So, what is the difference?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Two are okay to fix the Perfect data model. While you have generating same Data model that case you need to use as per there allignment for Schema.
This case, I would use the second case instead of first one
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Personally I would merge them all into one single table by exploiting the ApplyMap() function.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Please note that this is not a star shema and T2 and T3 are no Dimension tables. Wouldn't ApplyMap() return only one value? T2 and T3 can have multiple values which are related to one value in T1 (n:1 relation).