Unlock a world of possibilities! Login now and discover the exclusive benefits awaiting you.
- Qlik Community
- :
- Discover
- :
- Blogs
- :
- Product
- :
- Design
- :
- Follow the money: visualizing what the politicians...
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
Sometimes the secret sauce of a successful data visualization project lies in the correct choice of the visual object(s) that represents the data. Factors like picking the right chart, placing it in the right spot, and user interaction are key to make a data piece memorable, insightful, and truthful. However, on other occasions, the key to success is to “simply” make data available, this is particularly true for data that was previously inaccessible to most of us.
An example of this is our latest project. We partnered with Canadian National Post to, for the first time, make available over 6 million donations made on a national scale during the last 25 years.

In the last decade, open data has been a hot topic for governments all over the world, but open or public data isn't necessarily easy to access. That’s especially true when it's data that can help citizens to understand and track how our politicians’ campaigns are funded.
There are no consistent rules — or penalties — for political financing across Canada. Spending limits, out-of-province and foreign gifts, money from unions and corporations, donations from numbered companies: in some places anything goes, in other regulations are rarely enforced.
For Qlik one of the project main challenges was the data cleaning and normalization process. The project contains more than 25 different data sources. We fixed some of the most obvious issues with data, please read the methodology page (http://special.nationalpost.com/follow-the-money/methodology), but we also wanted the data to show how it was originally recorded without any makeover. It’s common to find small variations in names across the app, for example chances are that the donor names ‘Justin Trudeau’ and ‘Justin P.J. Trudeau’ belong to the same person also known as Justin Pierre James Trudeau.
We ended up having a large app holding around 6.5 million rows of data (at the time of writing) and a clear goal, make the data searchable. Anyone should be able to find individual donations and get some information about the shape of the data.
We used enigma.js to interface our Qlik Engine API and React to build the user interface. We created a powerful piece that displays millions of rows of data in the blink of an eye. React.js is designed to work with simply reacting to changes in data, and its super-efficient diffing algorithm makes DOM updates super-fast resulting in a blasting fast experience.
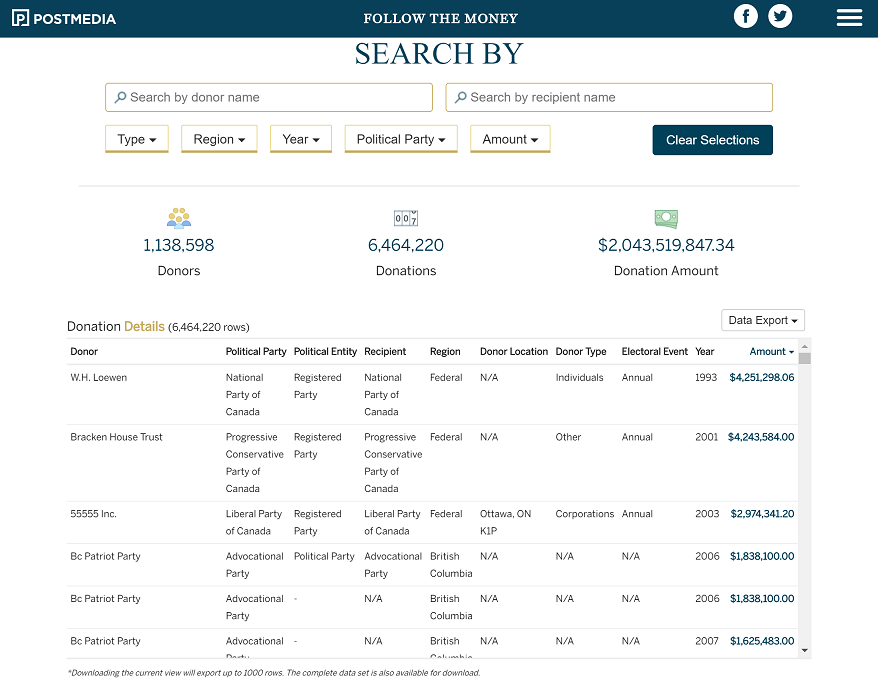
The main table displays the more granular level of data including individual donations and all the relevant details. To show the complete 6.5 millions of rows we use virtual scrolling and paging. The table is getting new data from the server as users scrolls the table.
We also included two bar charts to ease the data profiling task, compressing down millions of rows to a few bars. Lastly we use two small tables to illustrate the top donors and donations so the readers who are interested only in the super donors have a quick way of finding the information in the table.
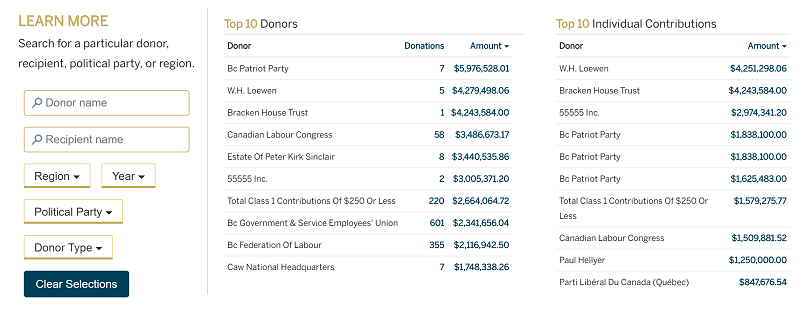
Check the online version here Follow the Money - Political Donations Database | National Post
AMZ
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.