Unlock a world of possibilities! Login now and discover the exclusive benefits awaiting you.
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
As one creates QlikView applications one sometimes encounters a data modeling problem where a dimensional attribute varies over time. It could be that a salesperson changes department or a product is reclassified to belong to another class of products.
This problem is called Slowly Changing Dimensions and is a challenge for any Business Intelligence tool. Creating an application with static dimensions is simple enough, but when a salesperson is transferred from one department to another, you will have to ask yourself how you want this change to be reflected in your application. Should you use the current department for all transactions? Or should you try to attribute each transaction to the proper department?
First of all, a changed attribute must be recorded in a way that the historical information is preserved. If the old value is overwritten by the new attribute value, there is of course nothing QlikView can do to save the situation:

In such a case, the new attribute value will be used also for the old transactions and sales numbers will in some cases be attributed to the wrong department.
However, if the changes have been recorded in a way so that historical data persists, then QlikView can show the changes very well. Normally, historical data are stored by adding a new record in the database for each new situation, with a change date that defines the beginning of the validity period.
In the salesperson example, you may in such a case have four tables that need to be linked correctly: A transaction table, a dynamic salesperson dimension with the intervals and the corresponding departments, a static salesperson dimension and a department dimension. To link these tables, you need to match the transaction date against the intervals defined in the dynamic salesperson dimension.
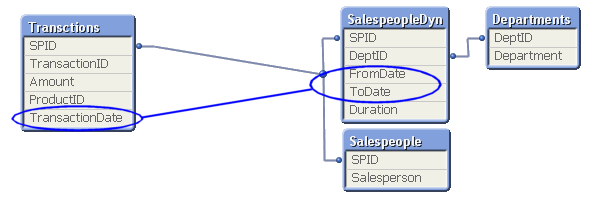
This is an intervalmatch. The solution is to create a bridge table between the transaction table and the dimension tables. And it should be the only link between them. This means that the link from the transaction table to the bridge table should be a composite key consisting of the salesperson ID (in the picture called SPID) and the transaction date.
It also means that the next link, the one from the bridge table to the dimension tables, should be a key that points to a specific salesperson interval, e.g. a composite key consisting of the salesperson ID and the beginning and end of the interval. Finally, the salesperson ID should only exist in the dimension tables and must hence be removed from the transaction table.
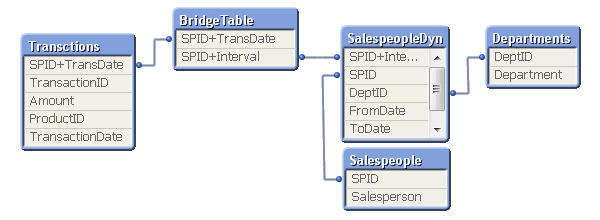
In most cases of slowly changing dimensions, a salesperson (or product, customer, etc.) can only belong to one department (or product group, region, etc.) at a time. In other words, the relationship between salesperson and interval is a many-to-one relationship. If so, you can store the interval key directly in the transaction table to simplify the data model, e.g. by joining the bridge table onto the transaction table.
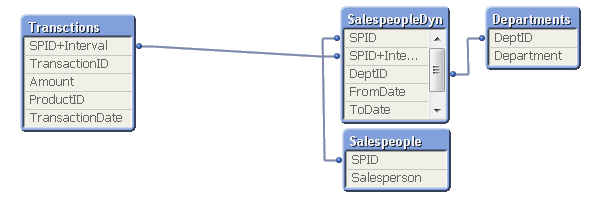
A word of caution: If a salesperson belongs to several departments at the same time, such a join may cause QlikView to make incorrect calculations. Bottom line: Double-check before you join.
For a more elaborate description of Slowly Changing Dimensions and some script examples, see the technical brief IntervalMatch and Slowly Changing Dimensions.
- « Previous
- Next »
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.