Unlock a world of possibilities! Login now and discover the exclusive benefits awaiting you.
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
In a well visited post on the community forum, John Witherspoon some time ago asked “Should We Stop Worrying and Love the Synthetic Key?” John’s post begins: “Synthetic keys have a bad reputation. The consensus seems to be that they cause performance and memory problems, and should usually or even always be removed. I believe that the consensus is wrong.” Here’s my view on this topic.
The creation of synthetic keys is simply QlikView’s way of managing composite keys. There is nothing strange or magic around it.
A single key is easy to manage: Just list all unique values in a symbol table (see Symbol Tables and Bit-Stuffed Pointers), and then link the data tables using a natural join.
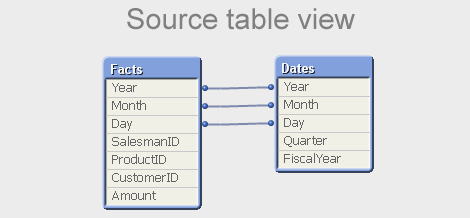
But a composite key is slightly different – there is no single symbol table that contains the relevant combinations of the multiple key fields. So QlikView needs to create such a table for all combinations: the $Syn table. In a way, you can say that the $Syn table is a symbol table for composite keys. In the data tables, the multiple keys are replaced by an identifier that uniquely identifies the combination of the values of the original keys: the $Syn key.
Hence, if you have the same set of multiple keys in two or more tables, the QlikView synthetic keys create a general, correct, compact and efficient solution. Synthetic keys do not per se cause performance and memory problems. They do not use a lot more memory than if you autonumber your own concatenated key. And they treat NULLs correctly, as opposed to an explicit concatenated key.
Hence: The synthetic key is in itself good and we should all love it.
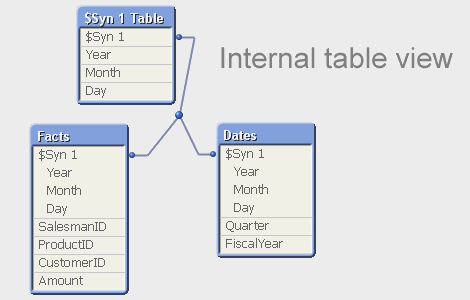
However… still, also I avoid synthetic keys. Why?
- A synthetic key is in my experience often a sign of a poorly designed data model. I say that, given the number of times I have found a synthetic key in the table viewer only to realize that I made a mistake in the script. If you get a synthetic key and didn’t expect it, I can only say: Back to the drawing board! You should most likely change your data model.
- QlikView creates an additional table (the $Syn table) that in many cases is superfluous: An additional table is the best solution if none of the data tables by itself completely spans the set of composite keys. But in real life, there is usually one table that contains all relevant combinations of the keys, and then this table can be used to store the clear text of the individual keys.
- For clarity, I like to create my own concatenated keys. It forces me to think and create a data model that I believe in. Removing the synthetic keys becomes a method to ensure a good data model, rather than a goal in itself.
But in principle, I totally agree with John’s initial conclusion: Any problem around synthetic keys is really a data modeling problem and not a problem with the synthetic key itself.
The short answer to John’s question is Yes and No. Yes, we should love the synthetic key. But, No, we should not stop worrying. We should always be alert and ask ourselves: “Do I want this synthetic key? Is the data model OK?”
And so, because of the automated and irrevocable data-modeling process which rules out human meddling, the Synthetic Keys are scaring. But they are simple to understand. And completely credible and convincing.
Dr HIC
Further reading on Qlik data modelling:
- « Previous
- Next »
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.