Unlock a world of possibilities! Login now and discover the exclusive benefits awaiting you.
- Qlik Community
- :
- All Forums
- :
- QlikView
- :
- Can anyone help me understand consistent single qu...
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Can anyone help me understand consistent single quote handling?
Hello Qlik Community,
It seems having an incomplete understanding of single quoting mechanics has been a nagging problem for me, and impacted routines and logic based around file system based iterations, set analysis syntax, variable interpretation syntax, and output file storage formats.
Single quotes seem to have a variety of interpretation formats and I would like to know how to control their settings, but having searched for documentation on this for a while, and haven't found anything. Is there a way to control the handling of single quotes within scripting/set-analysis/output text formatting?
I have an application that takes the standard recursive file iteration For..each.. next loop from the QlikView help manual. On my personal machine, this iteration loop has no problems consuming directory trees that are embedded with single quotes.
However, when I run this at client or job sites (both on local desktops and remote connected servers), I get a variety of behaviors. Sometimes the STORE to .txt output does or does not include wrapping the entire outside of the full output row with double quotes. Sometimes it places a single quote in front of an existing single quote in an "escape character" sense.
This results in some likely bizarre syntax where each variable is then being checked for single quotes and replacing the problematic characters with "innocuous" ones.. (i.e. Let myGoodVar = Replace(myWorrisomeVar,chr(39),chr(5000)); )
Making matters more difficult, I cannot use quotes around the variable as Replace('$(myWorrisomeVar)',chr(39),chr(5000)) because in the event the variable string contained 1 quote, the output has performed 3 replacements.
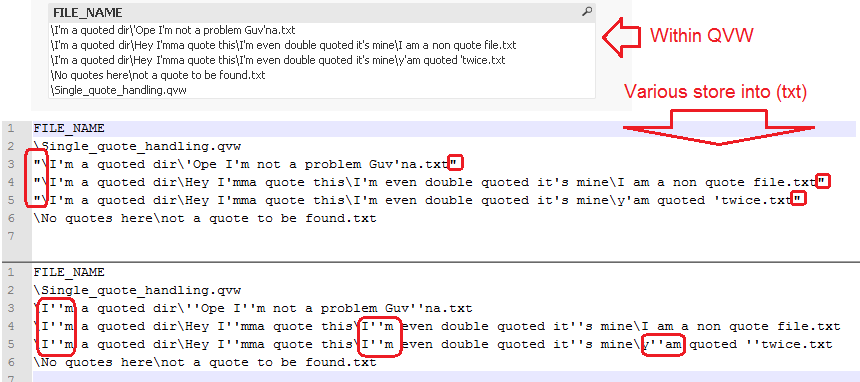
Within the .QVW itself, in my example you can see the application has parsed the directories and filenames correctly, single quotes don't seem to have "derailed" the process, but I am finding when I use this iterator in various environments, sometimes the single quotes "activate" and present some sort of interpretation issue within the script iterations, and at other times the disruptive behavior lies "dormant". This often applies to script variable interpretation, where a string like (James's) will load into QlikView as (James''s).
I know when we import a file via the Text file wizard we are asked for quoting options like "Standard | MSQ | None" but I haven't seen how to apply any type of quoting instructions for script interpretation or file output. Does anyone know what settings can adjust these? Is this a QV versioning thing? A server/os setting? A QV setting? Appreciate your assistance on this.
- Tags:
- qlikview_scripting
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
For example, in this illustration you can see elements that are the same interpreted differently across machines:
The script and the inline data haven't changed, the machines are different. Therefore, something outside of the script settings is affecting interpretation.

- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Maybe this Blog from Henric Cronström is helpful: http://community.qlik.com/blogs/qlikviewdesignblog/2013/04/09/quoteology.
- Marcus
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hey Marcus, I appreciate the reply. The post from Henric is thorough, but doesn't cover the scenario described.
You can see the script from the first reload is working, so that proves acceptable syntax. It is on transfer to another machine that the identical syntax starts behaving differently (which could mean a change in operating system, hardware, QV versions?).
So what I mean when I refer to this as a nagging problem, is that it isn't an issue to work out an initial set of syntax that works fine on a development machine, but what I would like to be able to anticipate is what other external settings beyond just scripting syntax could impact the scripting if it were migrated to other devices (or if settings outside of QV scripting on the same machine were altered). How do we anticipate for this?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I assume that qv used some local settings / libraries especially region-settings and char-sets to parse input and output but which one and could it be ignored / overwritten? Maybe Henric Cronström could give a deeper view on how its worked.
A (tedious trial and error) workaround (worst case) could be to store and read again a few sample-data to check how it will be interpreted on the local machine and then do some preparing / masking the data. Alternatively is to change the output externally with replacing wrong chars or convert the output like in these example: How store txt in ANSI ?
- Marcus
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hello Marcus,
Marcus Sommer wrote:
I assume that qv used some local settings / libraries especially region-settings and char-sets to parse input and output but which one and could it be ignored / overwritten? Maybe Henric Cronström could give a deeper view on how its worked.
- Marcus
Thank you for your replies, you are right-on in describing areas I'd like better understanding. This inquiry covers two prongs:
1. What settings external to QlikView (and any documented/non-documented internal QlikView settings. Easter eggs? etc?) can impact the interpretation of "special" characters, and data type formats used in conjunction with scripting/expressions/set-analysis.
This goes beyond scripting interpretation, and into field attributes. I'm not sure if I'm alone in experiencing this, but the scenario where a document that is left in a 'static' state will somehow produce variations on results in future reloads, even though none of the sourcing components of the .QVW have been modified, hasn't been as rare as I'd prefer. Logically this implies a change to the application has been made, but one that has not been observed.
For example, maybe some have had the experience of formatting a date field and working out expressions based around that formatting. Then something "upstream" suddenly causes the date field interpretation to revert to a non-compatible format. When extracting from a database, I could see explanations that maybe DB field semantics were altered, but if you are talking about flat-files from local file system, switches in field interpretation need more explanation.
I'm aware of a few areas where field data-type formatting, interpretation, sorting, etc.. are applied in QlikView applications, but I'm getting evidence that my catalog of these areas is incomplete, because something beyond these areas I can identify seems to have an impact as well.
You can format the field's actual contents (both the display side and the numeric value side) during scripting.
Then you can customize the display formats further at a variety of user-interface levels:
- During scripting
- In the expression
- In the object settings
- In the document properties (on the Variables, Sort, and Numbers tabs)
Then I understand there is the possibility of edits via modifications of project related components. You can't perform these changes interacting with the QV Desktop interface, but chages made via this manner can still alter the application:
- Direct edit or modification of application XML components, or other settings files that are absorbed into any particular .QVW
These represent a lot of areas to cover to search for impacts, but even still, my list is likely incomplete. What are the settings "upstream" of the .QVW that can impact this process? Settings that decide =chr(39) produces ' on box A, and =chr(39) produces ''' on box B.
Programming requires an absolute adherence to rules, I can't recall a single instance in which improper syntax was ever-forgiven. Auto-complete can attempt to help you finish a valid syntax phrase, but if the result is still improper, it is denied 100% of the time.
Anyone without a complete understanding of the full-breadth of the rules is at best:
- getting lucky, guessing, forming solutions that are potentially fragile
And at the worst, those forming solutions with an only partial visibility to the full breadth of rules:
- would likely have their development susceptible to seized control of those who retain a full understanding of the rules
Would you purchase a car from a manufacturer who told you "This car is yours, you completely own it. As the manufacturer we retain the ability to seize remote control of your car at any time through wireless signals. We can lock it, unlock it, turn it on/off, control the steering wheel. We will never use this ability though, the car is completely yours."
Let's say I purchased the car in California and I wanted to drive to Colorado, and in some strange series of coincidences, on three straight attempts the car kept breaking down at the state line. I took the vehicle to a manufacturer mechanic and left the car there for servicing. Upon return to the garage I was expecting some sort of explanation as to what was causing the mechanical failure, but to my disbelief the mechanic was like "What do you want to go to Colorado for anyway? Why don't you just drive up to Fresno? I hear things are very nice there this time of year." I started to get a cold-feeling in the pit of my stomach.
I posed this scenario to Benjamin the Donkey of George Orwell's 'Animal Farm' fame, and what he confided in me was: "What they always really means is 'we will never use this ability... unless we find some really urgent or expedient reason for doing so.' " Benjamin is super wise and he cracks me up.
Maybe this is the concept of ultimate trust, but.. personally I'd skip the above car. I'm fine with taking my chances with a car that doesn't have potential of external influences, as we have done for decades to this point. If I crash it, it's on me, fine. If you surrender autonomy, the inverse opens the door to the risk of abuse of oversight. Same goes for my phone, my operating system, etc.. In the event they had these "back doors" and kept them secret, that doesn't seem like an "ignorance is bliss" scenario, rather just that much creepier.
Marcus Sommer wrote:
A (tedious trial and error) workaround (worst case) could be to store and read again a few sample-data to check how it will be interpreted on the local machine and then do some preparing / masking the data. Alternatively is to change the output externally with replacing wrong chars or convert the output like in these example: How store txt in ANSI ?
- Marcus
2. When this issue is taken to the formats of STORE to (TXT) outputs, I see there isn't a variety of options for storage output. I'm guessing I'd like to split this problem and work on one area at a time. Thanks for your input on this, much appreciated.