Unlock a world of possibilities! Login now and discover the exclusive benefits awaiting you.
- Qlik Community
- :
- All Forums
- :
- QlikView App Dev
- :
- Re: Sorting similar names for display
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Sorting similar names for display
Hello,
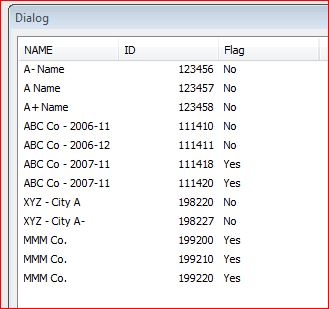
I have instances of IDs and Names where the name values are very similar - in some cases, they match exactly with one or more other instance (it may be 1 other, 2 other, unlimited other instances) - the IDs are unique. A sample of the data is below:
| ID | NAME |
| 123456 | A- Name |
| 123457 | A Name |
| 123458 | A+ Name |
| 111410 | ABC Co - 2006-11 |
| 111411 | ABC Co - 2006-12 |
| 111418 | ABC Co - 2007-11 |
| 111420 | ABC Co - 2007-11 |
| 198220 | XYZ - City A |
| 198227 | XYZ - City A- |
| 199200 | MMM Co. |
| 199210 | MMM Co. |
| 199220 | MMM Co. |
How can I extract these IDs and Names, group the Names together by their other instances and display them in a way that clearly shows the grouped instances together (perhaps in a pivot table)? For example, I would like to display the 3 instances of 'MMM Co.' grouped together so the user knows all 3 instances are together.
Many thanks
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
May be like this?
T1:
LOAD * INLINE [
ID, NAME
123456, A- Name
123457, A Name
123458, A+ Name
111410, ABC Co - 2006-11
111411, ABC Co - 2006-12
111418, ABC Co - 2007-11
111420, ABC Co - 2007-11
198220, XYZ - City A
198227, XYZ - City A-
199200, MMM Co.
199210, MMM Co.
199220, MMM Co.
];
T2:
Left Join(T1)
LOAD NAME,if(Count(NAME)>1,'Yes','No') as Flag Resident T1 Group by NAME;
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
MMM Co. was straight forward because it was an exact match? Are you also looking to combine XYZ - City A and XYZ - City A- Since they are almost very close?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi,
one solution could be to calculate a group number field (e.g. using the Levenshtein algorithm as described here: Levenshtein Algorithm) and to use this field to group and/or colour code NAME values using a straight or pivot table:
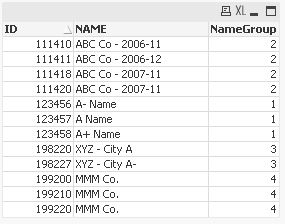
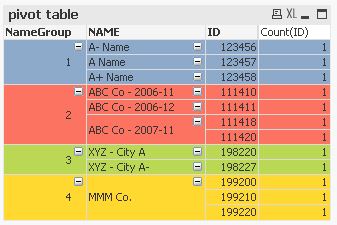
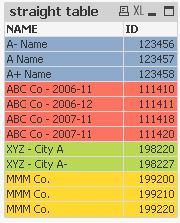
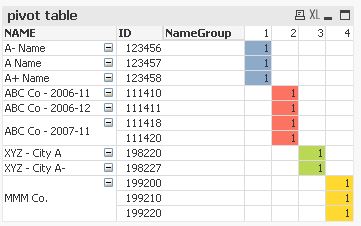
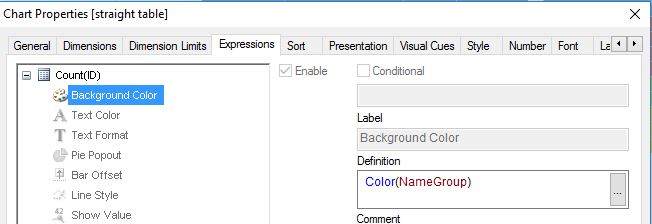
table1:
LOAD * INLINE [
ID, NAME
123456, A- Name
123457, A Name
123458, A+ Name
111410, ABC Co - 2006-11
111411, ABC Co - 2006-12
111418, ABC Co - 2007-11
111420, ABC Co - 2007-11
198220, XYZ - City A
198227, XYZ - City A-
199200, MMM Co.
199210, MMM Co.
199220, MMM Co.
];
table2:
LOAD Distinct NAME Resident table1;
Join
LOAD Distinct NAME as NAME2 Resident table1;
Join
LOAD NAME, NAME2, levenshtein(NAME, NAME2) as LevDistNAME Resident table2;
Right Join
LOAD Distinct LevDistNAME Resident table2 Where LevDistNAME<=2;
Join (table1)
LOAD NAME,
AutoNumber(Concat(NAME2,'/')) as NameGroup
Resident table2
Group By NAME;
DROP Table table2;
hope this helps
regards
Marco
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Marco,
I am VERY interested in your solution - never heard of the Levenshtein algorithm before - but before I try implementing your suggestion, the Name fields I provided are just examples - in reality, the Names won't be hardcoded in an Inline Load, they'll be retrieved from a QVD, so I'll have no idea of the actual names nor how many there are - will your suggestion still work in this case?
Thanks so much.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Yes Sunny, I am looking to combine names that are identical and I am looking to combine names that are similar. All the matching logic has already been done in the underlying SQL code - the SQL resultset is exported to a QVD, and my QVW will retrieve the data from the QVD, and I now need to find a way to group these names together in a graphical way.
Thanks.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi,
I used the inline load only to get some test data. You can replace it with a QVD load in a real application.
An issue might rather be the performance for large tables / many distinct Names.
You could try to replace the cartesian product (Join of tables without common fields) with a loop. The following example reduced rather the memory footprint of the load instead of the runtime though (again loading/generating some sample data / to replace with QVD load):
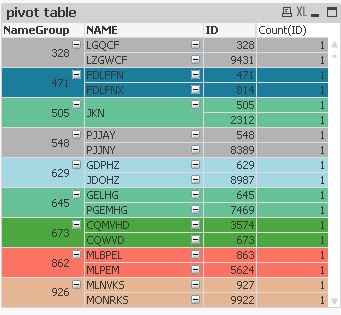
table1:
LOAD RecNo() as ID,
KeepChar(Hash128(RecNo()),'ABCDEFGHIJKLMNOPQRSTUVWXYZ') as NAME
AutoGenerate 10000;
tabNames:
LOAD Distinct NAME as NAME2 Resident table1;
FOR vCnt = 1 to FieldValueCount('NAME2')
LET vName = FieldValue('NAME2',vCnt);
table2:
LOAD *
Where LevDistNAME<=2;
LOAD NAME2,
'$(vName)' as NAME,
levenshtein('$(vName)', NAME2) as LevDistNAME
Resident tabNames;
NEXT vCnt
DROP Table tabNames;
Join (table1)
LOAD NAME,
AutoNumber(Concat(NAME2,'/')) as NameGroup
Resident table2
Group By NAME;
DROP Table table2;
hope this helps
regards
Marco