Unlock a world of possibilities! Login now and discover the exclusive benefits awaiting you.
- Qlik Community
- :
- All Forums
- :
- QlikView App Dev
- :
- P() Function will ignore the chart dimension, how ...
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
P() Function will ignore the chart dimension, how to fix that? (calculate intersection and union)
Hi all,
I met a problem when I use the P() function, I want to calculate the intersection and union of 2 columns in front-end, then I thought up using P(). But I found the P() will ignore the dimension then makes the result wrong :
My data :
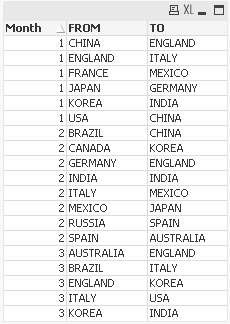
My Table:

My Intersection expression : Count(DISTINCT {<FROM = P(TO)>}FROM)
But you can see my data, in month = 1, only ENGLAND and CHINA are intersection between FROM and TO.
So I think that P() ignore the dimension, but I don't know how to fix that, do you have any ideas?
And also if you have any other method to calculate the intersection or union between 2 columns in front-end, that's would be great.
Thanks advance.
Aiolos Zhao
Accepted Solutions
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
For front-end solution, you may try like:
Count(if(Index(Aggr(NODISTINCT Concat(Distinct FROM&'@'),Month),TO&'@'),TO))

- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
It's not the p() function that will ignore your dimension, set analysis itself is only evaluated once, before the calculation engine even starts (hence set analysis will not consider chart dimensions).
You could transform your table using CROSSTABLE LOAD prefix:
Table2:
CROSSTABLE( Source, Country)
LOAD Month, FROM, TO
RESIDENT YourTable;
Then create a Chart with Month as Dimension and expressions like
=Count({<Source = {FROM}>} Country)
=Count({<Source = {TO}>} Country)
=Count(DISTINCT Aggr(If(Count(DISTINCT Source)=2,Country), Month, Country))
=Count(DISTINCT Country)
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
For front-end solution, you may try like:
Count(if(Index(Aggr(NODISTINCT Concat(Distinct FROM&'@'),Month),TO&'@'),TO))
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Aiolos,
From Back-end this can be done easily. By using concatenation.
A:
LOAD * INLINE [
Month, FROM, TO
1, USA, CHINA
1, CHINA, ENGLAND
1, JAPAN, GERMANY
1, KOREA, INDIA
1, ENGLAND, ITALY
1, FRANCE, MEXICO
2, GERMANY, ENGLAND
2, INDIA, INDIA
2, ITALY, MEXICO
2, BRAZIL, CHINA
2, MEXICO, JAPAN
2, CANADA, KOREA
2, RUSSIA, SPAIN
2, SPAIN, AUSTRALIA
3, AUSTRALIA, ENGLAND
3, ITALY, USA
3, BRAZIL, ITALY
3, KOREA, INDIA
3, ENGLAND, KOREA
];
C:
LOad
Month,
FROM as UnionFrom
Resident A;
Concatenate
LOad Month,
TO as UnionFrom
Resident A;
Use expression for intersection : =count(DISTINCT FROM) + Count(DISTINCT TO) - count(DISTINCT UnionFrom)
for Union : =count(DISTINCT UnionFrom)
Regards
Rachit Gaur
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Stefan,
Thanks for reply, crosstable is a good idea, but actually my data is too large, and there are many from/to every day and also have other data, so I want to do it in front-end and don't change the data model.
I didn't get the point of "set analysis itself is only evaluated once, before the calculation engine even starts", could you please help to explain?
Thanks.
Aiolos Zhao
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Rachit,
Cool, but because of my real data, I can only do it in front-end I think.
My back-end method is using left join, but I think yours is better than me. Because I want to choose every period date to calculate the intersection and union, and I think your way can do this.
Thanks
Aiolos Zhao
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Tresesco,
That's what I want,awesome. thanks a lot!
I think I can add a "distinct" in count :
Count(distinct if(Index(Aggr(NODISTINCT Concat(Distinct FROM&'@'),Month),TO&'@'),TO)).
Actually I also use aggr a lot, but I think I didn't get the true meaning of aggr, I think aggr is just a group by in
front-end.
And I also sometimes will use aggr(nodistinct ...), but could you help to explain the differece when using nodistinct?
Just using this example :
Count(if(Index(Aggr(NODISTINCT Concat(Distinct FROM&'@'),Month),TO&'@'),TO))
Count(if(Index(Aggr(Concat(Distinct FROM&'@'),Month),TO&'@'),TO))
When using nodistinct, is that meaning for every FROM, TO in every month, it will do the concat?
and using distinct means?
Thanks.
Aiolos Zhao
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
NODISTINCT - helps generate multiple values against same combination of dimension even if the output is same. But without NODISTINCT or with DISTINCT or default - the aggr() generates single output for same combination of dimension if they are same.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
thanks, so about the multiple values, what do the "multiple" depends on? The number of this combination in data?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Here is one good explanation : What NODISTINCT parameter does in AGGR function? and also look at the thread provided and explained by Stefan swuehl there.