Unlock a world of possibilities! Login now and discover the exclusive benefits awaiting you.
- Qlik Community
- :
- All Forums
- :
- QlikView App Dev
- :
- Problem with importing CSV file where CSV column m...
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Problem with importing CSV file where CSV column many 'internal' rows
I've run into a problem importing a rather large CSV file.
The problem I'm experiencing is that when importing the CSV file in the QlikView load script, QlikView seems to be unable to ensure that the value for each column maps to the appropriate column header. Instead the information gets garbled in much the same way as if an invalid/corrupt CSV file were being imported.
At first I thought that the problem was related to the number of rows in the CSV file, but after some investigation determined that the problem was caused by just two rows in the whole data set. Please see sample file attached.
These 2 CSV records, do contain embedded Line-Feed characters and this is normally not a problem. In point of fact once I removed the offending two records from the dataset the file imported without any problems.
It is worth noting that the 2 records do span 36,000 lines just by themselves.
My question is as follows:
- Does QlikView have an internal limit that prevents is from processing a record/s with so many lines that make up a single record?
- Is there any way to process such large records? I.e. some flag or setting that can be used to indicate an abnormally large record set.
Failing an in-app QlikView solution, I may have to write a Python program to truncate the individual problem 'cells'. This however is an overhead I'd like to avoid if possible.
Any feedback and/or suggestions would very much be appreciated.
Accepted Solutions
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hallo Grant,
QlikView has no limits for strings. In this way it should be normally not a problem to load such a csv file.
Your example file contains a bad line:

the line 17290 is the rest of a record for plugin "Recent files". But it belongs not to "Recycle Bin Files".
If it is so in the original file, I would say it is a bug in Nessus.
The example file is an utf8 file. If the original files are utf8 too, you better use "utf8" encoding in the load statement instead of "codepage is 1252".
After deleting the bad line the example file will be load by QlikView with out any problems.
NESSUS:
LOAD
*,
Len([Plugin Text]) as LenPluginText
FROM
(txt, utf8, embedded labels, delimiter is ',', msq, no eof);
PLUGINTEXT:
LOAD * Where Len(PluginText)>0;
LOAD
Plugin,
SubField([Plugin Text],chr(10)) as PluginText
Resident NESSUS;
DROP Field [Plugin Text];
Christian
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Your csv looked like a log-file from a security-tool and contained NOT a table-structure else a mix from a table with header and a data-stream. Therefore you need to tell Qlik what it should do with which part respectively record.
I think I would load it as it is and would with interrecord-functions like Peek() or Previous() ? identify and flag which records are the header, normal records and those special records and splitting with them the special records within an extra table.
What I would NOT do is to keep thousands of lines within a single field-value. In my opinion this makes no sense and I would probably also within further steps split the file-paths ... but it will depend on the goals with your data.
- Marcus
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thanks Marcus.
You are correct that the redacted sample provided is from a security vulnerability scanning tool called Nessus. The specific "problem" column is called "Plugin Text" and contains the literal output from the scanner probe for each and every IP Address and Port scanned. The content of the field therefore varies from row to row and is critically important to helping technical staff to remediate vulnerabilities found.
The problem is that the content of this field is 'dumped' by the scanning tool as a blob of text, and can be a few lines (+/- 5) of text all the way to many thousand lines of text. It is not consistent, and I will not be able to tell upfront which fields are small and manageable and which are huge and unmanageable by the load script.
If I understand your advice correctly, I should be able to use Peek() or Previous() to isolate the "Plugin Text" field and move it into a seperate table? Do you have an illustration on how specifically this would be done?
- Grant
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Can you post the LOAD statement you are using?
-Rob
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
The Load Script is as follows:
//Nessus Data
//scan the data folder for raw vulnerability CSV files to convert to QVD files
for each vFile in FileList('$(vExternalDataPath)InfoSec\Internal Vulnerabilities\Nessus\*.csv')
//create a QVD file name from the CSV file name
let vQVD = replace(vFile, '.csv', '.qvd');
//replace the external data path with the local data path
//this is because we don't want external users tampering with the QVD files generated
let vQVD = replace(vQVD, '$(vExternalDataPath)', '$(vDataPath)');
//if the file size of the QVD is 0 (i.e. it does not exist) or the
//file date time of the QVD is smaller than the file date time of the
//CSF file, then proceed to convert the CSV file to a QVD file
if alt(FileSize('$(vQVD)'), 0) = 0 or FileTime('$(vQVD)') < FileTime('$(vFile)') then
//trace which files are being read in and processed
TRACE $(vFile);
//newer Nessus scan result files include an additional field that is not in
//earlier versions of the file, this conditional code detects which fields
//are present and adjusts accordingly
Tmp:
NoConcatenate First 1
LOAD *
FROM $(vFile)
(txt, codepage is 1252, embedded labels, delimiter is ',', msq);
IF FieldNumber('Plugin Text','Tmp') > 0 then
TRACE 'Plugin Text found';
let vPluginTextField = '[Plugin Text]';
ELSE
TRACE 'Plugin Text NOT found';
let vPluginTextField = 'Null() as [Plugin Text]';
ENDIF;
DROP Table Tmp;
Temp_Nessus_File:
LOAD Plugin,
[Plugin Name],
Family,
Severity,
[IP Address],
Protocol,
Port,
Exploit?,
Repository,
[MAC Address],
[DNS Name],
[NetBIOS Name],
$(vPluginTextField),
Date(Date#(Replace([First Discovered],'SAST',''),'MMM DD, YYYY hh:mm:ss'),'DD-MMM-YYYY') as [First Discovered],
Date(Date#(Replace([Last Observed],'SAST',''),'MMM DD, YYYY hh:mm:ss'),'DD-MMM-YYYY') as [Last Observed],
[Exploit Frameworks],
Synopsis,
Description,
Solution,
[See Also],
[Risk Factor],
[STIG Severity],
[CVSS Base Score],
[CVSS Temporal Score],
[CVSS Vector],
CPE,
CVE,
BID,
[Cross References],
Date(Date#(Replace([Vuln Publication Date],'SAST',''),'MMM DD, YYYY hh:mm:ss'),'DD-MMM-YYYY') as [Vuln Publication Date],
Date(Date#(Replace([Patch Publication Date],'SAST',''),'MMM DD, YYYY hh:mm:ss'),'DD-MMM-YYYY') as [Patch Publication Date],
Date(Date#(Replace([Plugin Publication Date],'SAST',''),'MMM DD, YYYY hh:mm:ss'),'DD-MMM-YYYY') as [Plugin Publication Date],
Date(Date#(Replace([Plugin Modification Date],'SAST',''),'MMM DD, YYYY hh:mm:ss'),'DD-MMM-YYYY') as [Plugin Modification Date],
[Exploit Ease],
[Check Type],
Version,
//remapped fields
[Plugin Name] as Vulnerability,
Severity as [Nessus Severity],
[IP Address] as [Nessus IP],
//derived and custom fields
'Nessus' as Scanner,
FileDir('$(vFile)') as FileDir,
FileName('$(vFile)') as FileName,
FileBasename() as FileBasename,
Date(Date#(Left(FileBasename(),8),'YYYYMMDD')) as [Scan Date],
Year(Date(Date#(Left(FileBasename(),8),'YYYYMMDD'))) as [Scan Year],
Month(Date(Date#(Left(FileBasename(),8),'YYYYMMDD'))) as [Scan Month],
AddMonths(Date(Date#(Left(FileBasename(),8),'YYYYMMDD')),-1) as [ITISS Report Date],
Year(AddMonths(Date(Date#(Left(FileBasename(),8),'YYYYMMDD')),-1)) as [ITISS Report Year],
Month(AddMonths(Date(Date#(Left(FileBasename(),8),'YYYYMMDD')),-1)) as [ITISS Report Month],
//Qualys and Nessus report unsupported/eol vulnerabilities differently,
//this acts to normalise that and make reporting easier
if(wildMatch([Plugin Name], '*Unsupported*')>0,'Yes','No') as Unsupported,
if(wildMatch([Plugin Name], '*Unsupported Installation*')>0,'Yes','No') as [Unsupported OS],
//keys
[IP Address] as [IP Key],
Plugin&'-'&[IP Address]&'-'&Protocol&'-'&Port as [Nessus Key]
FROM $(vFile)
(txt, codepage is 1252, embedded labels, delimiter is ',', msq);
STORE Temp_Nessus_File INTO $(vQVD) (qvd);
DROP TABLE Temp_Nessus_File;
end if
next
//scan the data folder for raw vulnerability CSV files and then
//for each CSV file found, load the corresponding
//converted QVD file
for each vFile in FileList('$(vExternalDataPath)InfoSec\Internal Vulnerabilities\Nessus\*.csv')
//create a QVD file name from the CSV file name
let vQVD = replace(vFile, '.csv', '.qvd');
//replace the external data path with the local data path
//this is because we don't want external users tampering with the QVD files generated
let vQVD = replace(vQVD, '$(vExternalDataPath)', '$(vDataPath)');
//trace which files are being read in and processed
TRACE $(vFile);
Nessus_Data:
LOAD
*
FROM $(vQVD) (qvd);
next
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hallo Grant,
QlikView has no limits for strings. In this way it should be normally not a problem to load such a csv file.
Your example file contains a bad line:
the line 17290 is the rest of a record for plugin "Recent files". But it belongs not to "Recycle Bin Files".
If it is so in the original file, I would say it is a bug in Nessus.
The example file is an utf8 file. If the original files are utf8 too, you better use "utf8" encoding in the load statement instead of "codepage is 1252".
After deleting the bad line the example file will be load by QlikView with out any problems.
NESSUS:
LOAD
*,
Len([Plugin Text]) as LenPluginText
FROM
(txt, utf8, embedded labels, delimiter is ',', msq, no eof);
PLUGINTEXT:
LOAD * Where Len(PluginText)>0;
LOAD
Plugin,
SubField([Plugin Text],chr(10)) as PluginText
Resident NESSUS;
DROP Field [Plugin Text];
Christian
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thanks for your detailed response Christian.
I failed to realise that when I edited the larger file to isolate the problem rows that I had caused some corruption.
Thanks to for your novel solution to dealing with the overly large contents of the "Plugin Text" column and it's variable information.
I've taken your feedback, and removed the problem row in the original uploaded file (i.e. row 17290) and reloaded the file using your load script and suggestions regarding encoding.
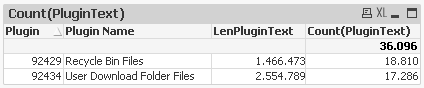
My dilemma is that having done this, the information in just these two rows is not being parsed correctly as per your example using my redacted data. E.g.

The above chart should only show two rows. It appears as if the parsing of Plugin Text has somehow caused a problem. If I emulate what you've done, I also only get 1 row, but interestingly with a different length and count.

Could the problem be with my version of QlikView (12.0.20400.0 SR5 64-bit edition) or the Operating System (Windows 10 Enterprise) that I'm using?
Perhaps there is a document or user setting that alters behaviour?
Thanks Grant
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Grant,
I will try it tomorrow on Windows 10 with QV 12.0 SR5.
Regards
Christian
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Grant,
with version QV 12.0 SR5 I get the same error as you. No chance to load this csv correctly.
Against that there are no problems with version 12.10 SR9 and 12.20 SR5.
- Christian
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thanks very much.
It seems that QV 12.0 SR5 had a bug that has been resolved since.
I downloaded and installed QV 12.20 SR5 and it worked like a charm.
Thanks again for the help.