Unlock a world of possibilities! Login now and discover the exclusive benefits awaiting you.
- Qlik Community
- :
- All Forums
- :
- QlikView App Dev
- :
- Should We Stop Worrying and Love the Synthetic Key...
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Should We Stop Worrying and Love the Synthetic Key?
Synthetic keys have a bad reputation. The consensus seems to be that they cause performance and memory problems, and should usually or even always be removed.
I believe that the consensus is wrong.
My understanding of a synthetic key is that it’s a pretty basic data structure. If you load tables like this:
TableA: FieldA, FieldB, FieldC
TableB: FieldA, FieldB, FieldD
What you’ll actually get is this:
TableA: SyntheticKey, FieldC
TableB: SyntheticKey, FieldD
SyntheticKeyTable: SyntheticKey, FieldA, FieldB
Where neither the synthetic key nor the synthetic key table can be directly referenced, only the original fields.
Well, that doesn’t sound like a bad thing. If I had two tables that I legitimately wanted to connect by two fields, that’s pretty much what I would do manually. As far as I can tell, QlikView is simply saving me the trouble.
Two tables can be connected by one field. That shows up as a connection. Two tables can be connected by two or more fields. That shows up as a synthetic key.
Now, maybe you should NOT connect two particular tables by one field. If so, that’s a data model problem that should be fixed. And while you could say that THAT connection is a problem, you should never say that CONNECTIONS are a problem.
Similarly, maybe you should NOT connect two particular tables by two or more fields. If so, that’s a data model problem that should be fixed. And while you could say that THAT synthetic key is a problem, perhaps you should never say that SYNTHETIC KEYS are a problem.
Synthetic keys should be no more a problem than automatic connections between tables are a problem. Either can cause problems when they result from a bad data model, when there are too many or the wrong connections. But neither should cause problems when they result from a good data model. You should not remove all synthetic keys any more than you should remove all connections between tables. If it is appropriate to connect two tables on two or more fields, I believe it is appropriate to use a synthetic key.
What does the reference manual have to say on the subject?
"When two or more input tables have two or more fields in common, this implies a composite key relationship. QlikView handles this through synthetic keys. These keys are anonymous fields that represent all occurring combinations of the composite key. When the number of composite keys increases, depending on data amounts, table structure and other factors, QlikView may or may not handle them gracefully. QlikView may end up using excessive amount of time and/or memory. Unfortunately the actual limitations are virtually impossible to predict, which leaves only trial and error as a practical method to determine them.
Therefore we recommend an overall analysis of the intended table structure by the application designer. Typical tricks include:
· Forming your own non-composite keys, typically using string concatenation inside an AutoNumber script function.
· Making sure only the necessary fields connect. If you for example use a date as a key, make sure you do not load e.g. year, month or day_of_month from more than one input table."
Yikes! Dire warnings like “may not handle them gracefully” and “may end up using excessive amount of time and/or memory” and “impossible to predict”. No WONDER everyone tries to remove them!
But I suspect that the reference manual is just poorly written. I don’t think these warnings are about having synthetic keys; I think they’re about having a LOT of synthetic keys. Like many of you, I’ve gotten that nasty virtual memory error at the end of a data load as QlikView builds large numbers of synthetic keys. But the only time I’ve ever seen this happen is when I’ve introduced a serious data model problem. I’ve never seen a good data model that resulted in a lot of synthetic keys. Doesn’t mean they don’t exist, of course, but I’ve never seen one.
I’d also like to focus on this particular part, “Typical tricks include: Forming your own non-composite keys”. While I agree that this is a typical trick, I also believe it is useless at best, and typically A BAD IDEA. And THAT is what I’m particularly interested in discussing.
My belief is that there is no or almost no GOOD data model where this trick will actually improve performance and memory usage. I’m suggesting that if you have a synthetic key, and you do a direct one to one replacement with your own composite key table, you will not improve performance or memory usage. In fact, I believe performance and memory usage will typically get marginally worse.
I only have one test of my own to provide, from this thread:
http://community.qlik.com/forums/t/23510.aspx
In the thread, a synthetic key was blamed for some performance and memory problems, and it was stated that when the synthetic key was removed, these problems were solved. I explained that the problem was actually a data modeling problem, where the new version had actually corrected the data model itself in addition to removing the synthetic key. I then demonstrated that if the synthetic key was reintroduced to the corrected data model, script performance was significantly improved, while application performance and memory usage were marginally improved.
load time file KB RAM KB CalcTime
synthetic key removed 14:01 49,507 77,248 46,000 ms
synthetic key left in place 3:27 49,401 77,160 44,797 ms
What I would love to see are COUNTEREXAMPLES to what I’m suggesting. I’m happy to learn something here. I’ve seen plenty of vague suggestions that the synthetic keys have hurt performance and wasted memory, but actual examples seem to be lacking. The few I ran across all looked like they were caused by data model problems rather than by the synthetic keys themselves. Maybe I just have a bad memory, and failed to find good examples when I searched. But I just don’t remember seeing them.
So who has a script that produces a good data model with a composite key table, where removing the composite key table and allowing QlikView to build a synthetic key instead decreases performance or increases memory usage? Who has an actual problem CAUSED by synthetic keys, rather than by an underlying data model problem?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Marcus
What you describe is a correct thing, but not everyone knows. Many people who are new to QlikView™ do not know these things, because QlikView™ does NOT give a reminder to users (Different from circular loops). Professionals (as good as you) know how to do it when building a data model. but in the face of a mess like mine, the only thing you can do is reconstruct it. I'd like to hear a better way from you.
Thanks!
- T&W
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
If you are surprised how we passed the test...
Unfortunately, there may not be such null values in our test data. I think this might be the negligence of the testers, but it is not unforgivable. After all, these null values were fabricated by me for Section Access. I tried to fill up a whole row of data, but this does not make the code elegant. So I spent two days to reconstruct it.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I am sorry that I replied to a 8-year-old post. But I still thought it's necessary to have a little discussion here.
About I called it “defect”, I have a reason, and I think it is quite sufficient. Fact tables are used to record facts - iron facts. You can't distort it, use any way. The fact table indicates that when A is ‘x’, KEY1 is ‘x’. But this relationship was destroyed by QlikView, without any reminder. This is an incredible thing for a relational database which is as a data provider.
Another thing, I wonder if this phenomenon is different on QlikView12. I did all these things on QlikView11 (11.20.12235.0 SR5 64-bit Edition).
Thanks!
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
It is worth mentioning that QlikView is not a relational database, actually it's not a database at all. The fact that QlikView stores data does not mean the product is intended for data storage, which is not. Perhaps I should have started by with that.
With that in mind, QlikView does not care about "fact tables", "relations", "keys" or "dimensional tables". QlikView reads from whatever source and creates "tables" made up of "rows" and "columns". That's it.
If those tables where somehow related in the data source is irrelevant for QlikView. It is not irrelevant, though, for the application developer.
It is the developer who understands the input, that is, the source data whatever it storage and format is: plain text fields, database tables, JSON requests, SAP queries or etc., and who understands the output required for the analysis and front-end, that is, the user interface in QlikView with which the user will interact, for example, of all the available attributes in the database, which ones are required to perform analysis and therefore must be loaded into QlikView and which others are not.
With this understanding, the developer is the one who associates tables by using the same field name in two tables and can perform an ETL of sorts via the QlikView loading script, like JOINing tables, using ApplyMap() or formatting date and numeric values.
The developer must understand that QlikView is intended for analytics, not for storage, and it will likely not behave as the traditional relational database you might be accustomed to. It has its own syntax and its own rules.
One of this rules is that to make QlikView associate two tables, they must share at least one field with the same name, case sensitive. And if they do in the source but they were not intended to be associated, like my example about Customer ID and Product ID, is the developer who must rename those fields or not load them altogether to avoid such association.
QlikView will record an error if there is an error. This is not an error. QlikView does not know if you do want to have two tables with two fields named alike, therefore it cannot break a load when there is nothing broken. It is not a syntactic error and it may not even be a data modelling error if you know what you are doing and you are doing it on purpose. That's why this is not a defect.
This "phenomenon" is exactly the same in QlikView 12, because QlikView 12 is not a database either. What it does change is performance, what causes an app to perform better and what it makes it perform worse, there are changes between QlikView 11 and QlikView 12.
For all things performance, the Qlik Scalability has a lot of good documentation.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Alright, you could say QlikView is something, and is not something else. You said developer who use QlikView must understand something, that is alright, too. But I think the more demanding QlikView is, the more unfriendly it is. Especially when it is out of line with similar products around.
I might say a little more, you can ignore the above paragraph if you like. Let's cut to the chase. If a phenomenon can not be explained, it can not be used, and then it has no value. Moreover, this phenomenon is easy to cause confusion. I hope it is not a "defect", but someone must give a rigorous explanation on it.
I did an additional experiment. When the TTT.qvw file is quoted by binary, and do anything else in the script then. data will change. I do not think this is a reasonable phenomenon, and it will cause confusion.
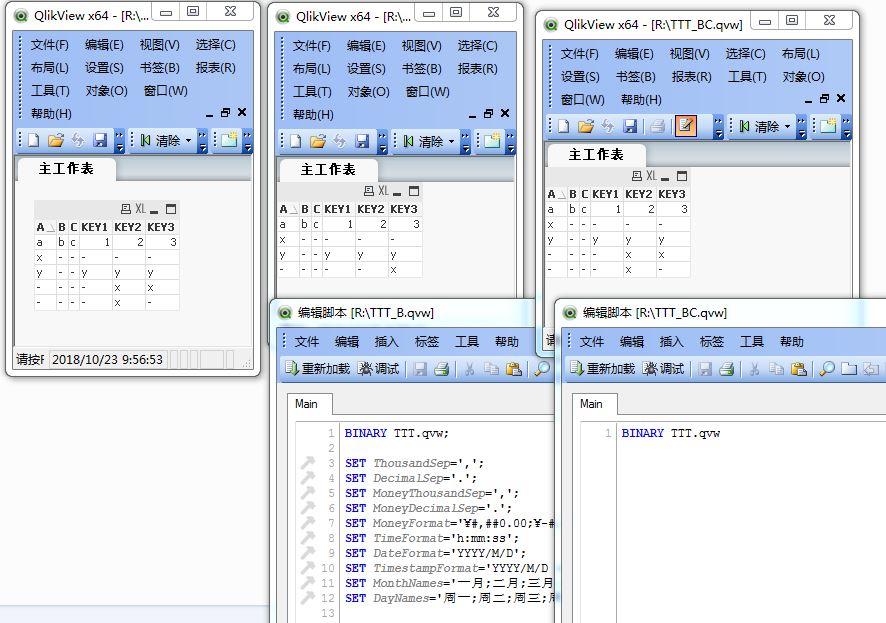
I very much hope that you or others can rationalize these two phenomena.
Thanks!
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Please see my simple example above.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Very disturbing. The part I find logical is that if there is any script other than the binary, QlikView would rebuild the synthetic keys, because the script could have changed the data, even though here it did not. What I don't find logical is that the results would be different when the underlying data forcing the creation of the synthetic keys should be exactly the same. Like you, I hope someone can explain.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Good to read from you John!
I'd file a bug with Qlik Support if you can provide them with steps so they can reproduce the issue.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I don't want to say that the behaviour of Qlik isn't explainable even if nobody here want to struggle with your application. Usually the development of an application (and not only within Qlik) should take the opposite approach as your application - using the recommended best practices and starting simply instead of loading a whole bunch of not validated data and trying to fix all the issues within a complex datamodel. Probably it will be possible in this way but it's much harder and more time consuming as the "common" simple way.
- Marcus
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Marcus
It is usually more convincing to test the friendliness of a product against people who have never touched it. They will start from the human instinct of thinking and do something that they think is "simple". As a new user of QV, I want to be helped when I fall into a trap similar to that of the ignorant. When the functionality of a product has reached a near perfect level, its friendliness will become an important area for improvement. Talking about these things may deviate from the original theme of this discussion, but we can continue if you like.
My humble opinion.