Unlock a world of possibilities! Login now and discover the exclusive benefits awaiting you.
- Qlik Community
- :
- All Forums
- :
- QlikView App Dev
- :
- Re: Stacked $Syn Keys with Null Values
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Stacked $Syn Keys with Null Values
Hi All,
Is there anyone has some ideas about $Syn keys' behavior of Null values?
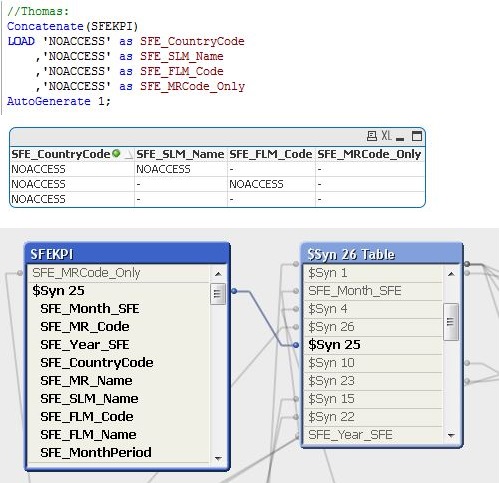
I have a fact table that contain several keys which are split into the $Syn table. Below a simple example, but it may not be accurate.
Fact:
LOAD * Inline [
KEY1, KEY2, KEY3, A, B, C
1,2,3,a,b,c
];
KEY1, KEY2, KEY3 are all split into the $Syn table. And the $Syn table has combined keys up to tens!
Then I insert a data that has a null value in KEY1.
Concatenate(Fact)
LOAD //Null() as KEY1,
'x' as KEY2,
'x' as KEY3,
'x' as A
AutoGenerate 1;
This incomplete datum just want to show that there is a corresponding relationship between KEY2, KEY3 and A when the three are "x".
Then I create a Table Box with KEY2, KEY3 and A on the front end, and select "KEY2 = x".
It showed that A is "-". Rather than "x" as I expected.
And when I select "A = x", KEY2 and KEY3 showed "-", too.
In fact, if you just build a very simple data structure like the one I built, it's not reproducible.
In my problem data structure, there are too many combined keys and columns in the $Syn table.
I would be grateful if anyone could explain this phenomenon!
- Tags:
- $syn
- « Previous Replies
-
- 1
- 2
- Next Replies »
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Your answer enlightens me. I find this unmatch may happen in synthehtic key relationships of nested synthehtic key table with NULL keys.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
To figure out how QlikView behaves you should know what is actually a synthetic key, what causes it and what it produces.
One of the products of a synthetic key is all possible combinations between the values of two fields which, although they share the same name (which is how QlikView associates tables between them) they do not share the same values.
One example could be the field "ID". It can be in my model within the Customer table and also within the Product table. Without further renaming the field, QlikView will understand that you want to associate the Customer and Product tables by the field "ID", which may or may not be intended. (One would guess that's not the association you want to perform).
Moving forward, let's say both tables have another field called "Name". Customer Name and Product Name. And finally, let's say that Customer has a third field named Address and Product has a third field named Category.
Without any changes to the names of the fields in the script, i.e.: using RENAME or AS, a script loading these two tables with two names named alike will result on a synthetic key -which in reality is table- that will contain all possible combinations (call it the Cartesian product) of the values of Customer.ID and Product.ID and Customer.Name and Product.Name.
As dummy as the example is, the above is wrong data modeling, unless you do want to associate two tables with two fields with the same names, by such fields. Else you will need to rename the fields in order to get meaningful data, in order, in turn, to be able to perform meaningful analysis.
Inevitably, since those fields are not meant to have the same values (they are not a subset of each others values, but completely different values) you can expect that there will be tuples of that Cartesian product with null values. A Customer.ID without a counterpart in Product.ID will create a row with Customer.ID and Product.Name in which one of them will be null.
For what it's worth, the difference between a real null (the complete absence of a value) and a blank is very important. For one, this is a good reference on how nulls work in QlikView and how to handle them.
Having 26 synthetic keys/tables means that in the data model there are 25 or more tables sharing 2 or more fields, and every synthetic key contains the Cartesian product of all the fields with the same name. If it's two fields, the table will contain the combination of those 2. If it's 20, the table will contain the combination of those 20 fields.
Hence, you cannot fake synthetic keys by creating values in a data model on your own without actually replicating those 20+ tables with fields with the same name. In other words, you don't create synthetic keys, QlikView does as a result of fields with the same name.
In the QlikView script you can indeed use INLINE loads or FROM loads from a CSV or XLSX files, which will not have null values unless you are joining those tables to other tables.
And the script can also contain RESIDENT loads from those INLINEs or FROMs without real nulls. Then the key created to associate the table will have real nulls on some cases and blanks on others.
While the representation in the chart can be the same symbol "-" (missing value because either or both a lack of value whatsoever or a blank/empty value) the underlying values must be understood in order to address the issue.
Said in different words, synthetic keys are fine when you let the fields in the script as they are on purpose. For example, my Customer table has a field CustomerID and CustomerFamily which are also present in my OrderLine table. Yet, you will have to be careful if you are transforming those fields in the script for the reason mentioned above, e.g.: one is loading a CSV file without nulls and another is reading from a transactional database with real nulls. In this case, there will be instances where the combination CustomerID and CustomerFamily will have blanks on one case and nulls on the other, so, after all, some values will be associated, when they shouldn't.
This is the true complexity of using synthetic keys, which are the way QlikView has to solve an issue. Not that they are not performing or that they return wrong values, in themselves they actually don't. Rather, you cannot control what is being associated and how.
--
P.S.: If you want to grab attention to your threads, don't mark any questions as answered if they are not so. That will lead to people who filters unanswered questions to completely skip them.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Henric (@hic),
you and others made a good point that we need to understand how the synthetic keys are created and link the tables, including how NULL key values are handled.
But IMHO, Thomas made also a good point here.
Let's ignore for a moment that the nested synthetic keys should be avoided and can be replaced by a better model.
Still, the data model should replicate the content of a single data table correctly, right?
If we restrict our analysis to Table A, making a selection of 'x' in field A (which is only part of Table A), I need to see that the relation to KEY2 and KEY3 will also show value 'x' as possible value, as determined in the record loaded in the fourth script table load.
(That's basically what Thomas pointed to in the OP)
As far as I understand, the synthetic key table should not play any role in that relation (Though it does in QV11, QV12 and latest Sense).
To me, it looks like a bug in the creation of the syn key table.
(another hint, if I look at the syn key table, there is for example a record with all NULL, which I don't understand, also the results are depending on a forced concatenate of the fourth table or keeping it linked).
Maybe our expectation is wrong here, would be glad if you could shed some light on this.
Regards,
Stefan
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Stefan
The problem is complicated from a theoretical perspective. Three tables are loaded:
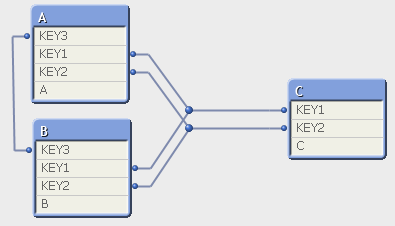
and now the question arises: How can you define a logical inference on this model? Well, the answer is "You can't". This model is ambiguous, just as a circular reference: If you select 'x' in field A, you can propagate the selection clockwise or counterclockwise, and the result when you "come back" to table A may contradict the initial selection.
With Synthetic keys, the Qlik engine changes the data model into:
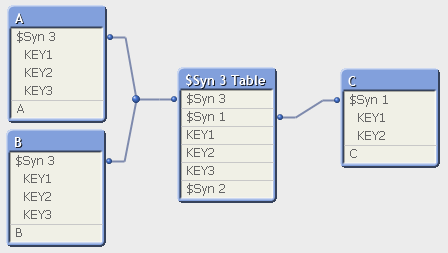
and now, the logical inference can be defined. But the cost of "flattening" the model is that the source tables now have been altered: A is no longer in the same table as KEY1, KEY2 and KEY3. And in addition, the link between A and the Keys (the $Syn 3) is affected by the content of the other tables, which is un-intuitive but necessary.
Hence, nested synthetic keys alter the data model: They have to alter the data model, otherwise it would sometimes be impossible to define what logical inference should mean. And without logical inference the Qlik engine is meaningless.
So, your assumption that "the data model should replicate the content of a single data table correctly" is wrong.
Bottom line: Synthetic keys has flaws, but I don't see how we could create them differently. And a data model with nested synthetic keys is ambiguous (from the perspective of logical inference), and will remain ambiguous no matter what we do in the Qlik engine.
HIC
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I understand that we need synthetic keys for the logical inference.
Still, I expected to see an entry in the records of the $Syn3 key table that replicates the original Key combination of the record in table A, just because - if I remember correctly another post of you in another thread,but same topic - the syn key table is based on all the available combinations of the keys.
edit:
The $Syn3 key table if fact does hold the combination of the keys, it seems that the internal syn key field value is just not properly used for the TableA linkage.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
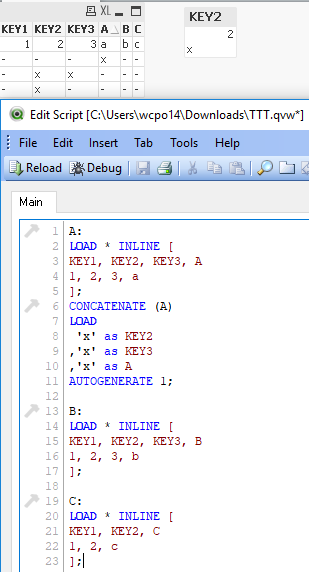
I'm summarizing a related conversation from another thread to try to get us all talking in one place.
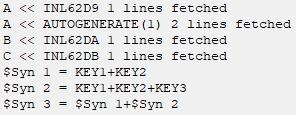
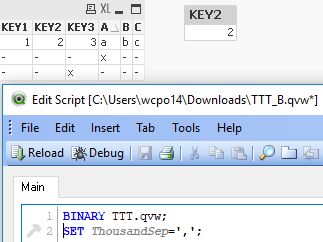
TTT.qvw: Get rid of the 'y' row - it's not needed to demonstrate the problem. Do the load. Get the results.
TTT_B.qvw: Now do a binary load from TTT.qvw, followed by a single unrelated SET. Having any additional script after the binary appears to force the rebuilding of synthetic keys, which is logical to me. The keys appear to be rebuilt exactly as before, which is also logical to me. But the table box looks different and 'x' is no longer in the list box for KEY2. The binary loaded data appears to be different from the original, to have lost some of the original data.
How is that possible?

- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Maybe I have a rough outline of how our A = 'x' value gets orphaned from its key in the first file, and then dropped completely after a binary load and synthetic key rebuild in the second load.
As we run the script, QlikView is keeping an internal list of all values of all fields. The list for A has a value 'x' in it since we've reached the end of the script without removing that value. But then maybe something funny happens while building synthetic keys involving null values, since nulls don't match to nulls, and the resulting data model no longer has any tables or keys with A = 'x' in them. But the field value list is still sitting around, and still has A = 'x' in it, and so it shows in our table box and list box.
If we binary load with no other script, we just bring everything back into memory, including the field value lists. But if there's any script after the binary load, I believe QlikView will back out the synthetic key creation to get back to what it thinks were our raw tables. But those tables no longer contain any data where A = 'x'. It also redoes the field value lists, and so the 'x' value disappears from the field value list for A. Finally, once it finishes the script, it builds synthetic keys from scratch, and rebuilds them exactly as before. The net result is only the A = 'x' value being dropped from the field value list.
I don't think this is entirely right. It might be entirely wrong. I can't seem to figure out the details in a way that would make what I said make sense. But it feels to me like something like that is happening - something gets orphaned in the first file, and then the orphan disappears in the second file.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
If there is a cycle hidden in the model which containing nested key, it is really interesting.
First, QlikView should find it out and remind users like an obvious cycle, rather than let it go.
Then, QlikView should allow users to define loose combinations arbitrarily. At least I haven't found how to make a part of a key table loose.
In addition, is it all nested keys mean that there are some hidden loops?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
The description you just described may contain another phenomenon -- BINARY's function ambiguity (or defect). But all this is due to the previous synthetic keys.
I've separately summarized and asked HIC about matching null values, and if you're interested, you can go ahead and check it out:
- « Previous Replies
-
- 1
- 2
- Next Replies »