Unlock a world of possibilities! Login now and discover the exclusive benefits awaiting you.
- Qlik Community
- :
- All Forums
- :
- QlikView App Dev
- :
- User defined expressions - Variables with paramete...
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
User defined expressions - Variables with parameters
Hello all,
I have a document with almost 300 text objects, charts, tables, etc, all with calculated expressions. Recently I changed its structure to use variables as user defined function with parameters instead of direct expressions. This way I could reduce almost all the different expressions to basically 6 like these:
vGetResultLevel1('04')
vGetResultLevel2('04.03')
...
vGetResultLevel6('04.03.05.01.01.02')
For each data I want to show on the document I have an ID and since the information I have has an hierarchical structure, data from lower levels inherit the IDs of the upper levels. To be more clear, here is an example:
Project XPTO (level 1) - ID='01'
Task XPTO.1 (level 2) - ID='01.01'
SubTask XPTO.1.4 (level 3) - ID='01.01.04', and so on.
So, if I want to show an information about the SubTask, I use the variable vGetResultLevel3('01.01.04'). If I want to show an information aggregated by the Project XPTO I use the variable vGetResultLevel1('01').
The definition of the variable is one set analysis that sums a value field based the ID (parameter) provided, like this:
sum({<%id_level_01={$1}>}#value) // the parameter would be '01' or '02', etc.
sum({<%id_level_02={$1}>}#value) // the parameter would be '01.01' or '02.05', etc.
sum({<%id_level_03={$1}>}#value) // the parameter would be '01.01.09' or '02.05.05', etc.
I have 6 levels of aggregation of information and the new structure allows me to just sum a #value field based on the ID (and therefore its level)
Well, my question is if there is much difference in terms of performance if I use as a parameter of the variable something like '04.03.05.01.01.01' instead of a shorter number. I'm afraid these long parameters get too long to calculate because the search of a long number is slower then a search of a short one.
I could implement both ways but the document became very big and it would take me to much time to do it.
What you guys think?
Thanks in advance.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
That's an interesting question, but the answer may depend on your data, so don't take anything following for granted.
If you are talking about difference in performance, I think you are interested in a notable relative difference.
There are different parts that need to be considered with your approach:
a) dollar sign expansion
This happens before your expression gets actually parsed and evaluated, like a text replacement
The Magic of Dollar Expansions
I don't think there is a big difference in performance using a literal of 2 or 17 characters when using dollar sign expansions with parameter.
b) Set Analysis {<%id_level_01={$1}>}#value)
Here, your parameter is matched against the distinct field values in the symbol table.
There might be different aspects involved that impact the performance, notable the number of distinct values / cardinality of your field and the way the search is done (search algorithm)
But let's assume the higher the cardinality and the longer the text values to match, the longer it takes.
c) The aggregation Sum(#value) across the resulting record set
This last step should be independent from the two approaches in the DSE / set analysis
Logical Inference and Aggregations
To estimate if there is a notable (relative) difference in performace, we need to know
1) the cardinality of your field values
2) the actual aggregation calculation time
If this calculation time is magnitudes higher than the time needed for step b), I believe you won't see a big relative difference
With regard to the cardinality, it seems you might need to cope with thousands of distinct values (Project - SubProject - Tasks - Subtasks, big projects - many subtasks).
Maybe it would be an idea to reduce the distinct values you need to search by being able to break the higher Levels down into making selections in several fields instead of a single.
Similar to not using a Timestamp field, but to use fields for Date, Hour, Minute , Second.
Not sure if you can reuse the existing lower (not so granular) level fields for this, or you might need to create new ones.
Just an idea, I think if you are only using a couple of distinct values, you shouldn't bother.
Hope this helps,
Stefan
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Stefan,
Thanks a lot! You pointed out some aspects that I've never paid too much attention.
I'll try to explain my scenario more precisely and maybe would be easer to figure out a solution.
I used the Project/Task/Subtask structure but, although similar, is not my real scenario.
I'm dealing with a document to present information concerning results of the Brazilian Government programs (social, infrastructure, finances, etc.). My data are basically spreadsheets from different Offices (each one with its particularities and structures) and most of then provide data aggregated by city and date. However, most of the provided data are not on the format I need to present on the document, forcing me to create specific expressions that are calculated on running time.
Recently I changed the structure of my model in order to make all the specific calculation on the script. This way, the only calculation I need to make to a specific program result is a sum. Here is the structure:
Level 01 - Area (ex: Health, Education, Infrastructure, etc)
Level 02 - Program (Specific program such as Construction of Hospitals)
Level 03 - KPI (Specific indicator of the program such as a) Amount of hospitals approved to be constructed, b) Amount of hospitals that finished the constructions, etc)
Level 04 - SubKPI (ex: a.1)Amount of budget provided by the Federal Government to construct Hospitals and a.2) Amount of budget provided by the local government to construct Hospitals)
The IDs definition is based on this structure. Consider the Area Health has ID = '01'. One project that is categorized by this Area gets the ID '01.02', for example. One KPI that is under this project gets the ID '01.02.05', and so on.
On the old structure, if I wanted to show the value of the SubKPI a.1 (above), I'd need an expression like this "=sum(if(Hospital.status='Construction' and Hospital.budget_source='Fed',Hospital.budget_value))".
Now, with the new structure I just need to sum the field #value providing as parameter the ID of the SubKPI a.1.
Therefore, if I want to show the sum of total budget to construct Hospital, no matter the source (KPI a), I just need to sum the #value providing the parameter of the KPI hierarchical above a.1, which is 'a'.
The other fundamental reason to change this structure is to get a better organization of data. Thus I could transform the data model from snowflake to star.
Well, that being said, my concern remains on if there is a better way to access my results considering that today I basically use variables with parameters an these variables follow this format: "sum({<%id_level_01={$1}>}#value)"
Thanks once more!
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
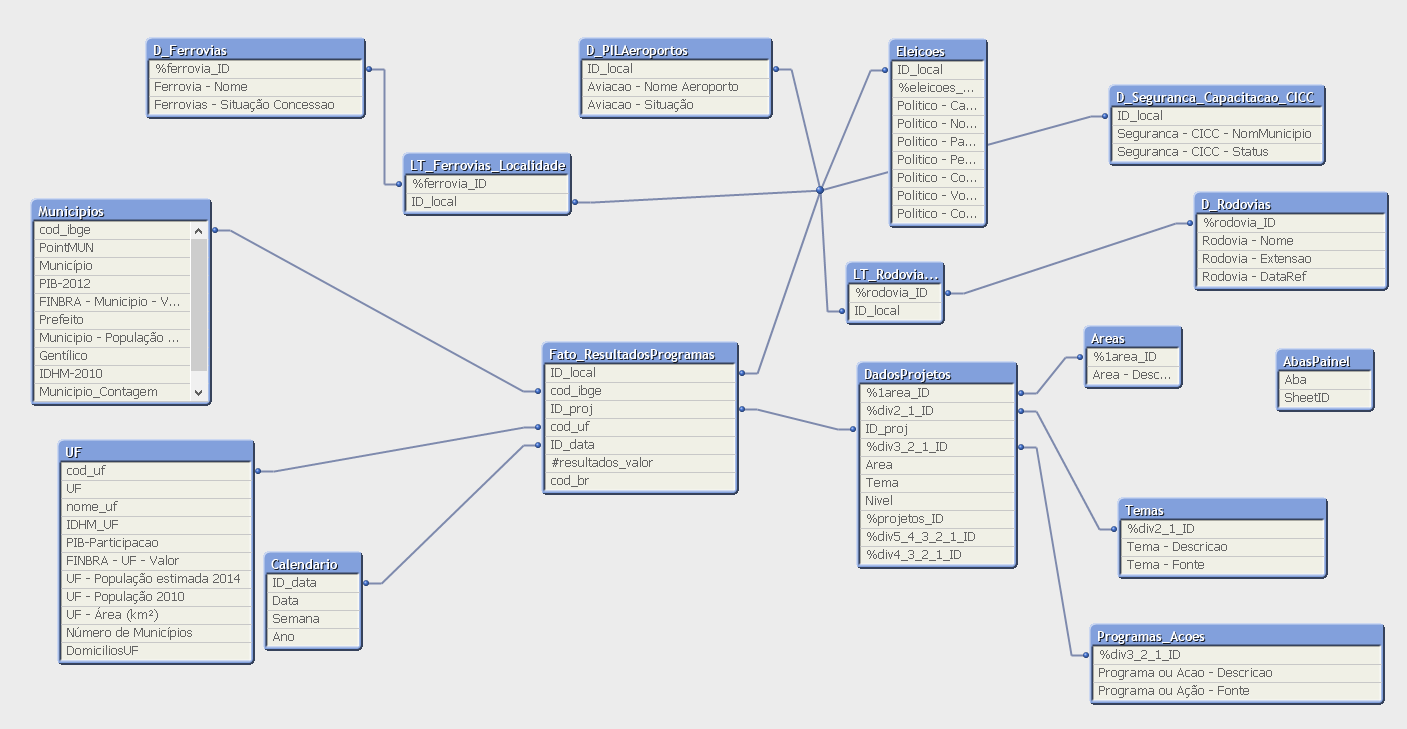
Could you outline how your current data model looks like? For example, could you post a screenshot of your table view?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Sure! Sorry for my portuguese model.
Fact Table: Fato_ResultadoProgramas (aprox 25 milion lines)
Table with the hierarchy of Areas, Programs, KPIs, etc: DadosProjetos (aprox 600 lines)