Unlock a world of possibilities! Login now and discover the exclusive benefits awaiting you.
- Qlik Community
- :
- All Forums
- :
- QlikView App Dev
- :
- Re: compare two columns text
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
compare two columns text
Hy guys.
I was wondering if there is any posibility to compare two columns text and when there is a word match , to mark it with ok.
Example
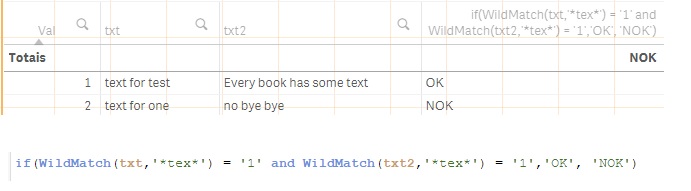
Col1Val : "text for test"
Col2Val: "Every book has some text".
And when comparing Col1Val with Col2Val I have a match on "text" word , and I will mark it with ok.
Thank you,
Razvan
Accepted Solutions
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Razvan,
I see the problema, the mapping table has value 1 and 0 for the same ID.
I've changed the script to filter the mapping table, now I take only the rows with index > 0:
[texts]:
Load
AutoNumber(Text1 &'-'& Text2) as ID,
*;
LOAD * INLINE
[
Text1,Text2
omniasig srl,assurance omniasig for house
text for test,Every book has some text
text, Any book has context,
text, context
](delimiter is ',');
//Split Text1 in words and check if a word of Text1 is in Text2
[map_text1_in_text2]:
Mapping LOAD ID,
1
Where index(Text2,Word) > 0;
LOAD ID,
//Add '-' to delimite each word. Without a delimiter if you compare 'text' with 'context' the result will be true
//instead of false
'-'&SubField(UPPER(Text1), ' ')&'-' as Word,
'-'&Replace(UPPER(Text2),' ', '-')&'-' as Text2
Resident texts;
//Apply the map
[text_final]:
LOAD *,
ApplyMap('map_text1_in_text2', ID,0) as [text1_in_text2]
Resident texts;
Drop table texts;
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Razvan,
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
This example is ok for one specific word. But I would like this to be dynamic. I would like to check in the second column if text from first column is found. I tryed with wildmatch but it didn`t work.
The example is this:
FirstColumn : omniasig srl
secondColumn : assurance omniasig for house.
If I compare this two columns like this wildmatch(FirstColumn,secondColumn,'ok','not ok') the result it`s NOT OK. But as you cand see the word from FirstColumn 'omniasig' is found in the secondColumn.
Thank you
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Razvan,
Try this:
//Load your data and add a ID field for each row
[texts]:
Load
AutoNumber(Text1 &'-'& Text2) as ID,
*;
LOAD * INLINE
[
Text1,Text2
omniasig srl,assurance omniasig for house
text for test,Every book has some text
text, Any book has context,
text, context
](delimiter is ',');
//Split Text1 in words and check if a word of Text1 is in Text2
[map_text1_in_text2]:
Mapping LOAD ID,
if(index(Text2,Word), 1, 0); //1 if a word of text1 is in text2
LOAD ID,
//Add '-' to delimite each word. Without a delimiter if you compare 'text' with 'context' the result will be true
//instead of false
'-'&SubField(UPPER(Text1), ' ')&'-' as Word,
'-'&Replace(UPPER(Text2),' ', '-')&'-' as Text2
Resident texts;
//Apply the map
[text_final]:
LOAD *,
ApplyMap('map_text1_in_text2', ID) as [text1_in_text2]
Resident texts;
Drop table texts;
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
In the form you exemplified it works , but I wonder why this code it doesn`t work?
T1:
Load * inline
[
Text1
omniasig srl
text for test
text
];
join(T1)
T2:
Load * Inline
[
Text2
Every book has some text
Any book has context
assurance omniasig for house
context
];
[texts]:
Load
AutoNumber(Text1 &'-'& Text2) as ID,*
Resident T1;
drop table T1;
//Split Text1 in words and check if a word of Text1 is in Text2
[map_text1_in_text2]:
Mapping LOAD ID,
if(index(Text2,Word), 1, 0); //1 if a word of text1 is in text2
LOAD ID,
//Add '-' to delimite each word. Without a delimiter if you compare 'text' with 'context' the result will be true
//instead of false
'-'&SubField(UPPER(Text1), ' ')&'-' as Word,
'-'&Replace(UPPER(Text2),' ', '-')&'-' as Text2
Resident texts;
//Apply the map
[text_final]:
LOAD *,
ApplyMap('map_text1_in_text2', ID) as [text1_in_text2]
Resident texts;
Drop table texts;
The apply map works fine , but in the page when I select the field "omniasig srl" from Text1 it doesn`t highlight all occurances from Text2.
Am I doing something wrong?
Thanks,
Razvan
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
If I change the order in Load Inline in your example , wont work too :
omniasig srl,Every book has some text
text for test,assurance omniasig for house
text, Any book has context,
text, context
instead of
omniasig srl,assurance omniasig for house
text for test,Every book has some text
text, Any book has context,
text, context

- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Razvan,
I see the problema, the mapping table has value 1 and 0 for the same ID.
I've changed the script to filter the mapping table, now I take only the rows with index > 0:
[texts]:
Load
AutoNumber(Text1 &'-'& Text2) as ID,
*;
LOAD * INLINE
[
Text1,Text2
omniasig srl,assurance omniasig for house
text for test,Every book has some text
text, Any book has context,
text, context
](delimiter is ',');
//Split Text1 in words and check if a word of Text1 is in Text2
[map_text1_in_text2]:
Mapping LOAD ID,
1
Where index(Text2,Word) > 0;
LOAD ID,
//Add '-' to delimite each word. Without a delimiter if you compare 'text' with 'context' the result will be true
//instead of false
'-'&SubField(UPPER(Text1), ' ')&'-' as Word,
'-'&Replace(UPPER(Text2),' ', '-')&'-' as Text2
Resident texts;
//Apply the map
[text_final]:
LOAD *,
ApplyMap('map_text1_in_text2', ID,0) as [text1_in_text2]
Resident texts;
Drop table texts;
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Can you please try with this script and tell me why when I select "omniasig srl" from text1 field , doesn`t highlights the text from Text2?
T1:
Load * inline
[
Text1
omniasig srl
text for test
text
];
JOIN(T1)
T2:
Load * Inline
[
Text2
Every book has some text
Any book has context
assurance omniasig for house
context
];
NoConcatenate
[texts]:
Load
AutoNumber(Text1 &'-'& Text2) as ID,
*
Resident T1;
drop table T1;
//Split Text1 in words and check if a word of Text1 is in Text2
[map_text1_in_text2]:
Mapping LOAD ID,
1 where Index(Text2,Word) >0;
LOAD ID,
//Add '-' to delimite each word. Without a delimiter if you compare 'text' with 'context' the result will be true
//instead of false
'-'&SubField(UPPER(Text1), ' ')&'-' as Word,
'-'&Replace(UPPER(Text2),' ', '-')&'-' as Text2
Resident texts;
//Apply the map
[text_final]:
LOAD *,
ApplyMap('map_text1_in_text2', ID,0) as [text1_in_text2]
Resident texts;
Drop table texts;
Picture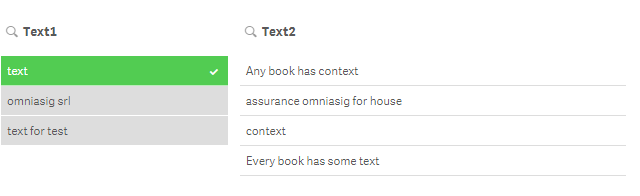
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
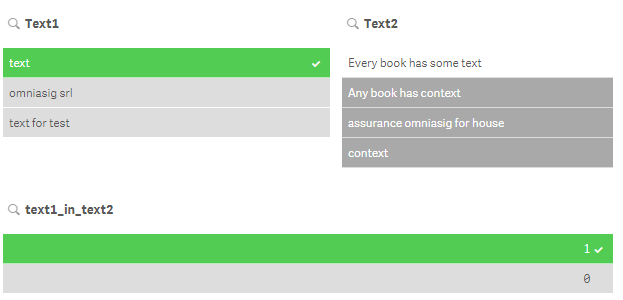
In the data model you made a cartesian product then all rows of text1 are related to rows of text2, you have to filter field [text1_in_text2] to indicate that you want only the texts that contains a common words.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Yap , your right. Anyway , Thank you for your help 