Unlock a world of possibilities! Login now and discover the exclusive benefits awaiting you.
- Qlik Community
- :
- All Forums
- :
- QlikView Integrations
- :
- Is unstructured data BI's next frontier?
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Is unstructured data BI's next frontier?
What is unstructured data and why is it so relevant?
Today unstructured data represents between 70 and 80% of all data in organisations. Yet it still remains largely un-exploited as a resource, while structured data has been the focus of the industry for the past several years. Why is this the case and how can unstructured data be integrated in analytics to make it useable?
First let’s understand what unstructured data is. Unstructured data is information that does not have a pre-defined data model or is not organised in a pre-defined manner according to Wikipedia.
Unstructured data basically has no identifiable structure and is divided in two main categories (1):
- Textual objects: based on written language, which includes word documents, reports, e-mails, blogs, web-pages…
- Bitmap objects: non-language based documents including images, video, audio files…
By opposition structured data is data that is identifiable because it is organised in a structure such as a relational database or a spreadsheet for example.
The advent of unstructured data in analytics is relatively recent, as it requires tools with a capacity to capture, curate, manage and process data that are extremely high, it is therefore not surprising that unstructured data has become more and more of a focal point with the accelerated development of cloud computing since the mid-2000 with products such as Amazon’s AWS.
What are the main challenges in working with unstructured data?
The largest challenge with unstructured data is that it requires context to be understandable and usable. Searching and parsing through unstructured data is akin to finding a needle in a haystack.
The importance of context can be explained with homonyms. Homonyms are ambiguous by definition and cannot be differentiated outside of a sentence and without any context applied to them.
For example the word caterpillar can reference an insect, the earth moving equipment manufacturer, a fashion brand or even a rock band.
Context becomes therefore an absolute necessity to understand unstructured textual objects.
How can unstructured data be managed and used?
There are variety of enterprise systems, which manage and analyse structured data. Such systems include CRM’s or Business Intelligence suits for example.
These systems provide an architecture that delivers the basic context with which to match unstructured data.
Let’s take for example a financial stock analysis fever chart. Such a dashboard provides information like the company name and the share price at specific times.
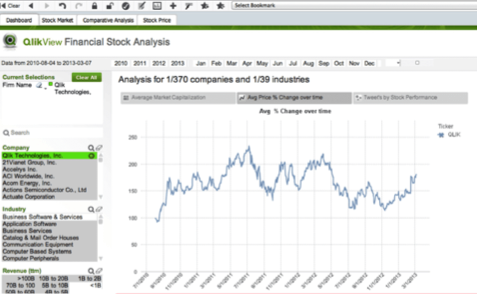
Figure 1: Financial stock analysis fever chart
Figure 1 shows what has happened to the stock price over a period of time, but it does not explain why the price has gone up or down.
In order to understand why the information in the fever chart evolved the way it did one needs to correlate that information to unstructured data such as news articles and financial reports for example.
The name of the company and the period of analysis provide the initial context. With these signals one can start building a digital fingerprint (Squirro’s patent pending technology) that is applied to various pieces of unstructured data and determine if they match the current selections in the dashboard. If they do then one can correlate these pieces of unstructured information to the original structured information.
This first step in working with unstructured data is unidirectional where the original selection signals are generated by the enterprise solution analysing structured data and then interpreted to retrieve corresponding structured data.
It is evident that the more signals can be drawn from the original system, the more precise will the selection of unstructured data be.
Analysing unstructured data to develop new analytical dimensions.
Once unstructured data can be related with accuracy to structured data, the next step is to understand the content of those pieces of information to create new analytical dimensions that can be examined in con-junction with structured data.
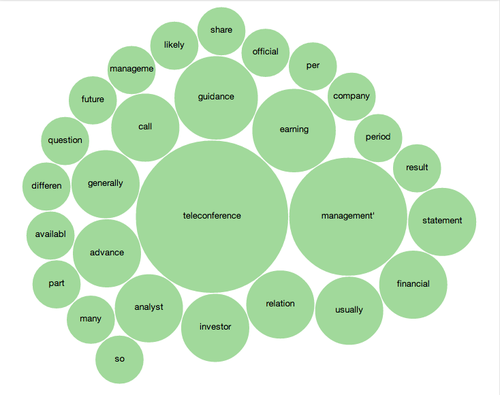
Figure 2: Graphical representation of Digital Fingerprint where key elements are weighted differently
The only way to understand the content of different disparate unstructured data is again through context. This time though context is created by the analysis of a sample set of contributing documents to understand the essence that links them to one another or through the definition of topics that best describe the essence of a piece of data.
Both these approaches allow the matching of documents to these definitions or links at a level that is much more precise than a simple semantic analysis. In fact the algorithm that enables the creation of these fingerprint weighs (Figure 2) the different elements of a definition or of a sample of contributing documents against one another therefore refining the precision of the fingerprint.
The use of this fingerprint technology now enables the creation of new analytical dimensions whereby a user can see via graphical representation how many records would match a specific fingerprint and how for example the quantity of these records evolves over time and this in conjunction with the original structured dimensions that the user had previously access to.
Unstructured data for better decision-making.
In conclusion the Digital Fingerprint Technology (DFT) enable the analysis and the use of unstructured data like never before.
By seamlessly integrating in already existing enterprise platforms (BI, CRM,…) the DFT uses the strength of the hosting platform and the DFT’s proprietary algorithm to parse and analyse unstructured data, making it usable for business analytics and therefore facilitating and improving data-driven decision making.
(1): Two Worlds of Data – Unstructured and Structured, Geoffrey Weglarz, Information Management