Unlock a world of possibilities! Login now and discover the exclusive benefits awaiting you.
- Qlik Community
- :
- All Forums
- :
- QlikView App Dev
- :
- Re: Не правильно работает функция IF
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Не правильно работает функция IF
С помощью диаграммы (карта дерева или круговая диаграмма) хочу отобразить приезд автомобиля на торговую точку. Сформировал в 5 групп: не посещена, во время, до начала ВО, приезд в перерыв и после окончания ВО. Временное окно двух типов: 1) с 7 до 13 или 2) с 7 до 12 и с 13 до 17 (с учетом перерыва). В точности прописал эту же формулу в Эксель, все работает правильно. В Qlik Sense неправильно отображает приезд автомобиля. Пример: ВО с 7 до 12 + с 13 до 17, приезд авто в 12:44, считает, как "Во время", но должно быть "Приезд в перерыв". Подскажите, пожалуйста, где именно ошибка? Возможно я не правильно понимаю принцип работы данной функции. Скрипт ниже.
if(@38='-1', 'Не посещена',
if(@41='-1',
if (((@44>@39) and (@44<@40)),'Во время',
if (@44<@39,'До начала ВО','После окончания ВО')),
if (((@44>@39) and (@44<40)) or ((@44>41) and (@44<@42)), 'Во время',
if(((@44>@40) and (@44<@41)), 'Приезд в перерыв',
if((@44<@39), 'До начала ВО', 'После окончания ВО'))))) as [Приезд на ТТ],
@38 as [Точность объединения],
@39 as [Начало первого временного окна],
@40 as [Окончание первого временного окна],
@41 as [Начало второго временного окна],
@42 as [Окончание второго временного окна],
@44 as прибытие,
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Доброго времени суток, Юрий!
В приведенном коде не очень понятна проверка if(@41='-1'... (вторая строка), т.к. по определению далее @41 as [Начало второго временного окна].
Кроме того, раз есть два варианта окна (быстрее всего это связанно с анализом обычного рабочего дня и субботы), следовательно до проверок времени прибытия с параметрами начала и окончания окон, как представляется, должна быть проверка типа окна.
В целом я бы осуществлял следующую последовательность проверок:
1. Проверка факта посещения
2. Проверка типа окна
3. Проверка на прибытие до начала рабочего дня
4. Проверка на прибытие после окончания рабочего дня
5. Проверка на прибытие в перерыв (только для рабочих дней)
6. Все остальное - прибытие вовремя.
Извините, что от руки, но дерево проверок выглядит, как представлено на рисунке ниже
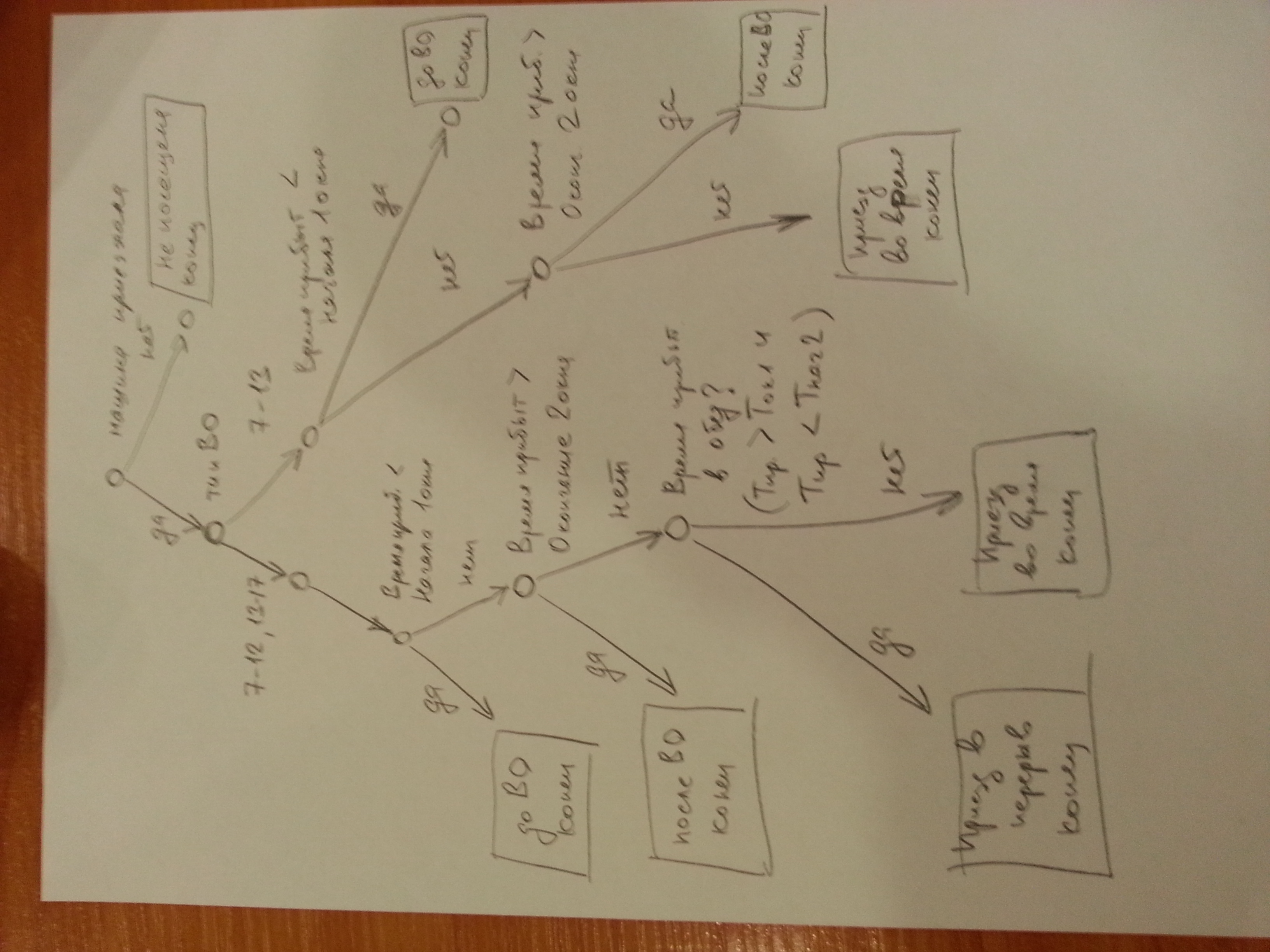
С уважением
Андрей
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
(В приведенном коде не очень понятна проверка if(@41='-1'... (вторая строка), т.к. по определению далее @41 as [Начало второго временного окна].)
У меня есть CSV файл, где по умолчанию в поле 41 выгружает значение "-1" есть нет данных.
Кроме того, раз есть два варианта окна (быстрее всего это связанно с анализом обычного рабочего дня и субботы), следовательно до проверок времени прибытия с параметрами начала и окончания окон, как представляется, должна быть проверка типа окна.
Не совсем так, два варианта окна за счет того, что у некоторых клиентов может быть перерыв в работе. Это может быть любой день недели с пн по вс (доставка 7 дней)
В целом я бы осуществлял следующую последовательность проверок:
1. Проверка факта посещения
2. Проверка типа окна
3. Проверка на прибытие до начала рабочего дня
4. Проверка на прибытие после окончания рабочего дня
5. Проверка на прибытие в перерыв (только для рабочих дней)
6. Все остальное - прибытие вовремя.
Извините, что от руки, но дерево проверок выглядит, как представлено на рисунке ниже
Спасибо большое за оперативную обратную связь. Очень полезно.
Получается, вот тот алгоритм, что я написал изначально, работает правильно, но я не понимаю, почему он не работает в скрипте загрузки, а в редакторе выражений все работает. Ниже точно такой же пример, только адаптирован под редактор выражений + с комментарием. Можете, пожалуйста, объяснить этот момент?
//Был ли визит?
if([Точность объединения]='-1', 'Не посещена',
//Есть ли второе ВО?
if([Начало второго временного окна]='-1',
//ИСТИНА!!!!
//Попал ли в ВО?
if ((([прибытие]>[Начало первого временного окна]) and ([прибытие]<[Окончание первого временного окна])),'Во время',
//Приезд до начала ВО был?
if ([прибытие]<[Начало первого временного окна],'До начала ВО','После окончания ВО')),
//ЛОЖЬ!!!!
//Попал ли во ВО с до и с до?
if ((([прибытие]>[Начало первого временного окна]) and ([прибытие]<[Окончание первого временного окна])) or (([прибытие]>[Начало второго временного окна]) and ([прибытие]<[Окончание второго временного окна])), 'Во время',
//Приезд в перерыв был?
if((([прибытие]>[Окончание первого временного окна]) and ([прибытие]<[Начало второго временного окна])), 'Приезд в перерыв',
//Приезд до начала ВО1 был?
if(([прибытие]<[Начало первого временного окна]), 'До начала ВО', 'После окончания ВО')))))
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Юрий, доброе утро!
Вроде логика данных теперь понятна. Как я понимаю, @39 as [Начало первого временного окна] - это время начала любого типа окна, т.к. их значения совпадают, а @41 as [Начало второго временного окна] - это признак, первое или второе окно анализируется, раз его значение по существу логическое (название поля чуть вводит в заблуждение).
Нарисовал дерево решений по Вашему коду, аналогично приведенному мною ранее. На мой взгляд, судя по полученному результату, Ваша логика должна работать. Значит, по идее, теперь надо искать ошибки в синтаксисе или в данных.
Есть пару соображений (исходя из того, что вижу, о том пишу, т.к. другой информации просто нет).
1. Нет ли просто случайных ошибок в приведенном Вами коде - например, нет знака @ перед номером поля (если Вы его просто скопировали сюда из редактора скрипта, выделено красным цветом ниже)?
if(@38='-1', 'Не посещена',
if(@41='-1',
if (((@44>@39) and (@44<@40)),'Во время',
if (@44<@39,'До начала ВО','После окончания ВО')),
if (((@44>@39) and (@44<40)) or ((@44>41) and (@44<@42)), 'Во время',
if(((@44>@40) and (@44<@41)), 'Приезд в перерыв',
if((@44<@39), 'До начала ВО', 'После окончания ВО'))))) as [Приезд на ТТ],
@38 as [Точность объединения],
@39 as [Начало первого временного окна],
@40 as [Окончание первого временного окна],
@41 as [Начало второго временного окна],
@42 as [Окончание второго временного окна],
@44 as прибытие,
2. На первый взгляд, возможно проверяются на соответствие разные типы данных, например время и логическое значение 0 или -1 (ниже выделено красным)
if(@38='-1', 'Не посещена',
if(@41='-1',
if (((@44>@39) and (@44<@40)),'Во время',
if (@44<@39,'До начала ВО','После окончания ВО')),
if (((@44>@39) and (@44<40)) or ((@44>41) and (@44<@42)), 'Во время',
if(((@44>@40) and (@44<@41)), 'Приезд в перерыв',
if((@44<@39), 'До начала ВО', 'После окончания ВО'))))) as [Приезд на ТТ],
@38 as [Точность объединения],
@39 as [Начало первого временного окна],
@40 as [Окончание первого временного окна],
@41 as [Начало второго временного окна],
@42 as [Окончание второго временного окна],
@44 as прибытие,
Исходя из того, что @39 - это время начала и первого, и второго ВО, а @41 просто логический признак вида ВО, надо в коде везде в сравнениях @41 заменить на @39.
С уважением
Андрей
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Спасибо большое! Действительно была ошибка в скрипте. Исправил и теперь все работает.
Скажите, пожалуйста, если у меня этот алгоритм прописан в скрипте загрузки, это ускоряет вычисления в модели или не имеет значения, где он прописан в скрипте загрузки или редакторе выражений?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
При небольшом объеме данных (сотни тысяч строк) разницу Вы быстрее всего на практике не заметите. Но в целом надо, на мой взгляд, руководствоваться следующим.
Как известно, программы Qlik работают как бы в два этапа: сначала из внешних источников данные посредством скрипта загружаются в хранилище Qlik, а затем на основании этих данных хранилища строятся диаграммы. При изменении данных хранилища в процессе очередной загрузки автоматически пересчитываются все диаграммы.
Диаграммы Qlik можно в самом общем случае использовать в двух режимах:
1. Изменение (или возможность изменения) диаграмм - данные в хранилище Qlik регулярно обновляются в процессе работы скрипта загрузки, впоследствии пользователь работая с диаграммами использует отборы, сценарии анализа и т.п. - классический анализ данных.
2. Диаграммы играют роль неизменных панелей индикаторов, на которые в результате периодического обновления данных в процессе работы скрипта загрузки выводятся значения определенных показателей (по аналогии, датчик уровня топлива в автомобиле). Представляется, что пользователь не работает с диаграммами Qlik, только наблюдает за ними и их не изменяет.
Первый режим основной и собственно на его использование направлено совершенствование программ Qlik разработчиком. Второй режим несколько искусственный и может использоваться для предоставления высшему руководству компании определенных данных, обновляемых с заданной периодичностью (ну не будет генеральный директор или президент корпорации на практике изучать Qlik, а вот посмотреть показатели на ноутбуке, планшетнике или смартфоне вполне может).
Если интервал между загрузками достаточно большой (десятки минут, часы, дни), что характерно практически всегда для первого (основного) варианта режима работы и в большинстве случаев для второго, то конечно предпочтительно все вычисления поместить в скрипт загрузки. По крайней мере при изменении диаграмм вычислений будет меньше и сами вычисления/изменения диаграммы пройдут быстрее.
Если же используется второй режим, причем с небольшим интервалом времени обновлений (десятки секунд, минуты), то здесь я бы все определял экспериментальным путем (сильное влияние оказывают каналы связи, характеристики вычислительной техники и т.п.), заранее понимая, что вычисления в диаграммах будут производиться быстрее, чем при загрузки скрипта.
Учитывая, что второй режим с небольшими интервалами загрузки на практике представляется некоторой экзотикой и используется не часто, по крайней мере в случае решения задачи Вашего класса, я бы рекомендовал обсуждаемые нами вычисления вынести в скрипт. Пересчет диаграмм в последующем будет происходить быстрее, что особенно будет заметно на больших объемах данных (десятки и сотни миллионов строк).