Unlock a world of possibilities! Login now and discover the exclusive benefits awaiting you.
- Qlik Community
- :
- All Forums
- :
- QlikView App Dev
- :
- Re: Background color performance on million rows
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Background color performance on million rows
Dear Community!
I use a straight table or pivot with approx. 400 million rows and 8 columns, where each is a dimension and get a backgorund color in case of an complex expression. As one of you might expect, if there is no filter it will be terrible slow and consuming a lot of ram.
It would be enough, if the expression will be active, if one important filter is active, so that the perfomance will be better.
I tried for this following expression :
If(GetSelectedCount(FILTER_FIELD)>=1,if(COMPLEX EXPRESSION),RGB(255,255,204))
But still the perfomance is terrible, as i think he still analyses every row.
Any idea how can i tell him to start the expression if an filter is active, or the result row number will be smaller than a specific nr.
Or have someone another ideas for a better perfomance, with such a amount of data and coloring filter results?
Accepted Solutions
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
In the chart properties, tab general, find Calculation condition. Write your condition there. I can't guess how to calculate number of rows in your case. Typically there is a field that identifies the row, e.g. some ID. In this case:
count(distinct ID)<10000
Next, you can add some flexibility. Create a variable vMaxRows, and add an input box with this variable. Use it in calculated conditions:
count(distinct ID)<vMaxRows
Besides, to help your users, modify the message "calculation condition unfulfilled" to a something more helpful, e.g.:
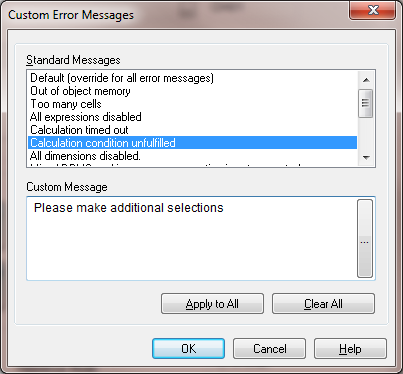
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi,
Maybe your 'Complex Expression' can be simplified.
Can you show us?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Fernando, see below:
if(match(mid(FIELD_VALUE,1,6),$(=(CONCAT(DISTINCT(chr(39)&FIELDSVALUE&chr(39)),', ')))
for more info about this expression see following discussion: https://community.qlik.com/message/761137
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I don't believe that there is a practical use of a table with 400 M rows. Or even with 10 thousand rows. My recommendation - conditionally enable calculations only if the number of rows < than some reasonable number, e.g. 10,000.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Michael,
i share your opinion, but how can i "conditionally enable calculations only if the number of rows < x" ??
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
In the chart properties, tab general, find Calculation condition. Write your condition there. I can't guess how to calculate number of rows in your case. Typically there is a field that identifies the row, e.g. some ID. In this case:
count(distinct ID)<10000
Next, you can add some flexibility. Create a variable vMaxRows, and add an input box with this variable. Use it in calculated conditions:
count(distinct ID)<vMaxRows
Besides, to help your users, modify the message "calculation condition unfulfilled" to a something more helpful, e.g.:
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Great Michael,
that helped me a lot!
Actually i have 8 Dimensions inside a pivot, and count the rows to display results that are equal or smaller than 100
count(aggr(DIM1,DIM2,DIM3,DIM4,DIM5,DIM6,DIM7,DIM8))<=100
Is there a better way to achive this? (tried already RowNo & NoofRows but they are not working and slower)
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Your condition looks fine. Just to keep in mind that it count also the rows where all expressions are 0, and if you hide them (by "suppress zero-values"), the count will be off. If you don suppress zero-values, you count is good.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Maybe for any one else interesting : For a better perfomance than counting
set that one or more meaningfull filter(s) need to be choosen, before the calculation starts.
I achieved that using : GetSelectedCount(NEEDED_FILTER_FIELD)>=1
Inside the error message we set the names of the fields that are necessary for the object!
Works really perfomant now on a huge data set.