Unlock a world of possibilities! Login now and discover the exclusive benefits awaiting you.
- Qlik Community
- :
- All Forums
- :
- QlikView App Dev
- :
- Help for Customer Hierarchy count
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Help for Customer Hierarchy count
Hello,
There is what i would like to do:
- I have a table like this
| Article | Customer | Quantity |
|---|---|---|
| 1 | 9999 | 20 |
| 2 | 9998 | 9 |
and another table
| Customer | son customer |
|---|---|
| 9999 | 10000 |
| 9998 | 9997 |
| 10000 | 10001 |
| 9999 | 10002 |
| 9997 | 9996 |
| 9997 | 9995 |
| 9998 | 9994 |
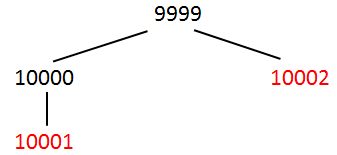

- I want to count the number of sons customers and divide the quantity with it.
There is what im looking for in this example:
| Article | Customer | Quantity |
|---|---|---|
| 1 | 10001 | 20/2 = 10 |
| 1 | 10002 | 20/2 = 10 |
| 2 | 9996 | 9/3 = 3 |
| 2 | 9995 | 9/3 = 3 |
| 2 | 9994 | 9/3 = 3 |
It should always take the lasts customers of the hierarchy
How could i do this? Maybe with the Hierarchy function or mapping?
Thanks for your help,
Regards,
Loïc
- Tags:
- qlikview_scripting
- « Previous Replies
-
- 1
- 2
- Next Replies »
Accepted Solutions
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hello Loic_dev,
I'm glad we worked on this because I've had this nagging feeling there is something about the hierarchy function that is off, but just couldn't put my finger on it. I've had inconsistent results in the past where that whole process of trying to loop through the values and chain them together and detect the depth, it wasn't necessary. Everything is clear now and all that needs to be done is engage the later parameters of this function, however...
If you don't use the EXACT CORRECT arguments for hierarchy, the true capabilities of the function remain concealed.
To exacerbate the problem, the documentation of the hierarchy function in the manual has 3 issues:
- It is incomplete
- It contains inaccuracies
- It cites no functional code examples that illustrate its fully intended form
All that looping of code that was happening in the prior version of the apps in this thread, where its trying to create a chain of concatenation of the hierarchy tiers and add a delimiter? That is basically trying to emulate what the hierarchy function would be doing if the later parameter arguments were applied, but with a lot more code, complexity, and convolution. Toss it out!
Attached is a newer and more brief version, that does the same thing as before, but the entire chain assembly happens in the hierarchy function. However I'm going to follow with a post that illustrates the disconnect from documentation and functionality, god only knows how many would-be adopters of QlikView this divergence of "reality" vs. "perception" has scared off or discouraged.
Revised copy attached:
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Any idea???
Thanks in advance
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
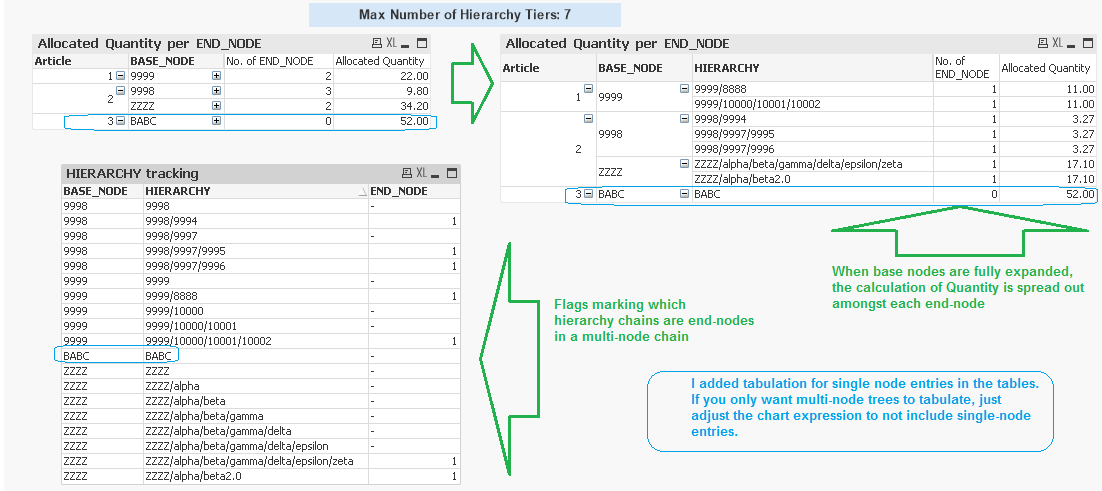 Hello Loic_dev,
Hello Loic_dev,
Attached is an app that will break out sub-allocations of quantity based only on the number of end nodes (omit any middle nodes, or entries that are both parent & child)
The routine should dynamically contract or expand based on a varying number of hierarchy layers embedded in the source data.
Also, not sure if you wanted to ignore or include a single node, single layer entry from the calculations. I included them in the app, but if you want to remove them just edit the expression.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hello Evan and thank you very much!
Your app seems great but i got an error just by refreshing it...
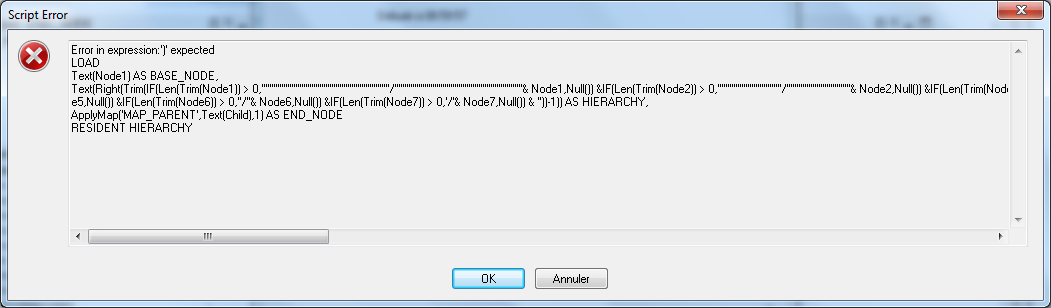
There is a problem with the variable vString i think
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hello loic_dev,
I downloaded the posted application from this thread and reloaded. Everything works fine for me, with an error free execution.
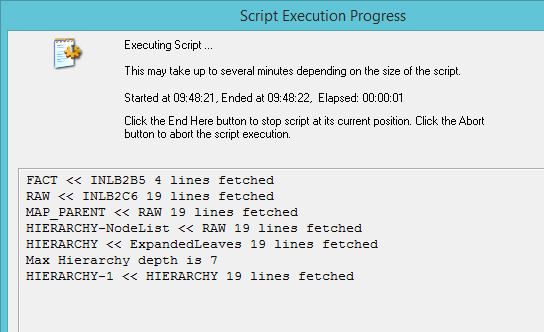
So can you test a few things? Download an unmodified copy of the application from this thread, reload, and make note of any errors in a freshly downloaded copy. Also, if you could activate a log script, that would start producing a debugging trail.
If you made any changes, no matter how minor, mention those. Obviously you would want to start replacing the sample data from this thread with the real thing, but without seeing all your details maybe additional information is missing.
The formation of vString is delicate and complicated. If I edit a small segment in the vString formula, the reload can produce an error message similar to the one you have posted.
Replacing a single quote syntax "chr(39)" with something like "Repeat(chr(39),20*$(vMaxNodes)-$(i))"
produces the following error message (which looks very similar to the one you generated)
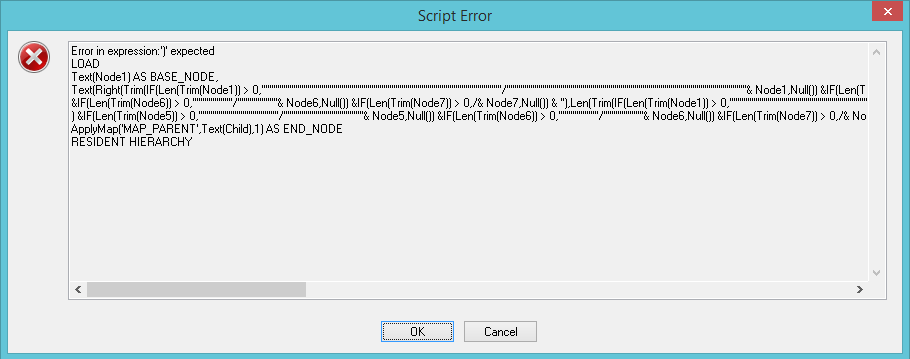
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I didn't modify anything and i still got this error...
There is the log script, it seems to be an error due to the quotes char yes...
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hello loic_dev,
This is interesting.. you can see when you compare between your log file and mine that one difference between our environments is the processing of quote characters, they seems to incur additional wrapping on your end. (In my log file it is not showing growing chains of single quotes)
I've experienced applications that seem to require logic changes as the underlying nature of quote handling seems to "move around", but would definitely like more specifics on how to control these settings.
For now, I just removed the dynamic resizing of the hierarchy depth and hardcoded it to a fixed range of 7 (which has to match the depth of the data set). The automatic detection of the hierarchy depth seemed to work on your end, so maybe run the app once and exit after the hierarchy depth is determined, then edit your final hierarchy load statement upward or downward and then reload the full script.
The dynamic resizing is working fine on my machine but without understanding all the differences between our platforms, maybe you'll at least have the long method for now.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hello Evan,
Thank you for all the time you spend on my problem.
The other difference i see between our log files is on the table HIERARCHY.
[HIERARCHY]:
Hierarchy(Child,Parent, Node)
LOAD * RESIDENT [RAW]
3 fields found: Parent, Child, Node, 19 lines fetched
10 fields found: Node1, Node2, Node3, Node4, Node5, Node6, Node7, Child, Parent, Node, 19 lines fetched
[HIERARCHY]:
Hierarchy(Child,Parent, Node)
LOAD * RESIDENT [RAW]
3 champs trouvés: Parent, Child, Node, 38 lignes récupérées
10 champs trouvés: Node1, Node2, Node3, Node4, Node5, Node6, Node7, Child, Parent, Node, 38 lignes récupérées
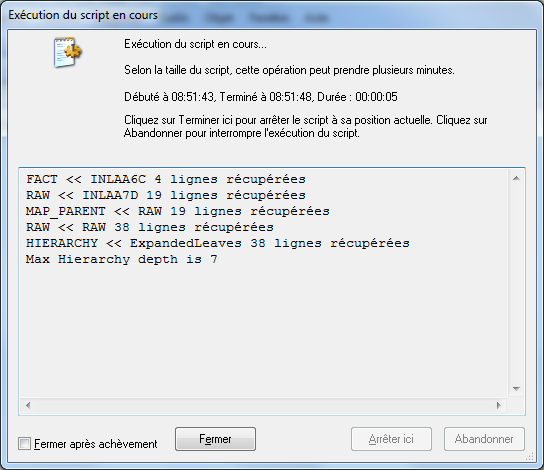
In my app, i got all the lines in double:

This is another strange point...
Also, it may be a problem due the parameters which do not appears in your log file:
14-08-2014 09:00:47: QlikView Version:11.00.11154.0
14-08-2014 09:00:47: CPU Target x86
14-08-2014 09:00:47: Operating System Windows 7 Professional (32 bit edition)
14-08-2014 09:00:47: Wow64 mode Not using Wow64
14-08-2014 09:00:47: MDAC Version 6.1.7600.16385
14-08-2014 09:00:47: MDAC Full Install Version 6.1.7600.16385
14-08-2014 09:00:47: PreferredCompression 2
14-08-2014 09:00:47: EnableParallelReload 1
14-08-2014 09:00:47: ParallelizeQvdLoads 1
14-08-2014 09:00:47: AutoSaveAfterReload 0
14-08-2014 09:00:47: BackupBeforeReload 0
14-08-2014 09:00:47: EnableFlushLog 0
14-08-2014 09:00:47: SaveInfoWhenSavingFile 0
14-08-2014 09:00:47: UserLogfileCharset 0
14-08-2014 09:00:47: OdbcLoginTimeout -1
14-08-2014 09:00:47: OdbcConnectionTimeout -1
14-08-2014 09:00:47: ScriptWantsDbWrite false
14-08-2014 09:00:47: ScriptWantsExe false
14-08-2014 09:00:47: LogFile CodePage Used: 1252
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hello Loic,
It does look like your rows are doubling. It doesn't seem apparent to me what turns that on or off because we're running the same syntax. What you can do is try the DISTINCT keyword in front of the hierarchy and see what that produces.
HIERARCHY (Child, Parent, Node)
LOAD DISTINCT * RESIDENT [RAW]
See if that brings your row counts back in line.
The logfile I posted was reduced to only the pertinent areas, the original does have those parameters.
- « Previous Replies
-
- 1
- 2
- Next Replies »