Unlock a world of possibilities! Login now and discover the exclusive benefits awaiting you.
- Qlik Community
- :
- All Forums
- :
- QlikView App Dev
- :
- Re: Incremental loading and merging of data from m...
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Incremental loading and merging of data from multiple connections
Hi,
I'm looking for some data handling strategy feedback.
Scenario:
I have regional data (same format) sitting on 5 separate servers. Each region has 1 month of log data, made available in Hive. The data volume is huge, so I need to:
(1) transform/aggregate it during load and
(2) store the aggregated content for up to a year.
Current Status:
I have a working incremental load script (using a qvd file) for one region (one ODBC connection).
Challenge:
Because loads from each region can fail independently, I would like to keep the regional data in separate qvd files, so that each can be corrected/updated on the subsequent incremental load execution. This means that for EACH connection/region I have to track start/end dates for both qvd file and the current hive load.
...I'm assuming I would have to edit [date] variable names so they're different for each connection e.g. vHiveLoadStartDateRegionA, vHiveLoadEndDateRegionA, vHiveLoadStartDateRegionB, vHiveLoadEndDateRegionB, etc. (I understand QV does not have a method of restricting variable scope).
Question:
What's the best way to handle this?
Should I have 5 copies of the same connection script but each with different connection, file, and variable names?
Should I apply some sort of a loop, where the connection, file, and variable names are auto-generated on each iteration?
Regardless of the strategy, what's the best way to merge the regional data for QV visualization, once incremental loads are done?
Thanks,
J.
- « Previous Replies
-
- 1
- 2
- Next Replies »
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
One, unique connection per region:
ODBC CONNECT TO RegionA;
ODBC CONNECT TO RegionB;
ODBC CONNECT TO RegionC;
etc.
Each region is a different ODBC data source (different: host name / IP).
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
How about :
- Input parameter of Region to a single qvw
- Spreadsheet with 1 row per Region
- 1st column is Region
- 2nd column is the ODBC connection string for the region
- .. any other required columns
- In qvw read in spreadsheet row where Region = parameter region
- This will produce just one row
- Put the ODBC connection string into a variable
- Dollar expand this variable to execute it to do the connection
- Create a Publisher Task for each Region
- Passing in the Region as a parameter
- Run all these Publisher Tasks in parallel
- Have your dashboard reload Task dependent on all the Region Tasks having run successfully
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
overcome the sequential nature of ODBC connect statements
on your desktop open qlikview twice
makes 2 different .qvw doc, one with an odbc conn to the server regionA, the other regionB
you can reload the 2 .qvw doc in parallel because they are in different qv.exe
I would first try in this way; also I would add the final .qvw to merge the data from regional .qvw and prepare the data for the UI. Then, test in publisher (task dependency, etc....).
Will it works? I think yes.
Example,
I renamed your doc in JW_Sample-QV-Script B.qvw
I make an include connB.txt with just a line (replace with a conn to a server region) in the same folder
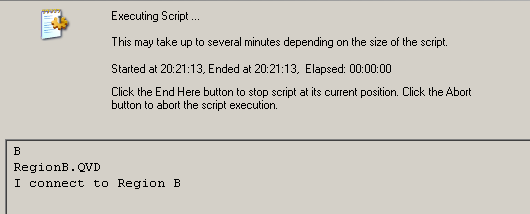
trace I connect to Region B;
when I reload the .qvw with just these lines (no reference to region A B C...)
LET region=right(subfield(DocumentName(), '.'), 1); // region from .qvw name
LET vQvdFile = 'Region$(region).QVD';
TRACE $(region);
TRACE $(vQvdFile);
$(Must_Include=Conn$(region).txt);
I get B region , B qvd, B connection. The only difference is in the name of the .qvw.
5 .qvw, 5 include, 5 regions
If I understand Bill's suggestion, it's one step better; he suggests (hope to understand, Bill correct me if I'm wrong) to use one .qvw and pass the parameter with the publisher (instead of 5 different .qvw).
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thanks Bill!
I haven't implemented it yet, but I now understand what to do.
Also a big thank you to maxgro for introducing me to the insanely useful 'trace' command, providing an example of parameter handling, and rephrasing Bill's strategy (yes, it did help!).
- « Previous Replies
-
- 1
- 2
- Next Replies »