Unlock a world of possibilities! Login now and discover the exclusive benefits awaiting you.
- Qlik Community
- :
- All Forums
- :
- QlikView
- :
- QVD Compression Technique
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
QVD Compression Technique
HI All,
Can anybody please explain the technique behind QVD compression,
How it is fast when fetching the data from QVD than database?
Thanks
- Tags:
- qlikview_scripting
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
First of all, QlikView will remove any duplicates of each field creating a symbol table.
Then numeric values are stored into binary form.
The answer to your second question is depends how fast your database can be.
I´ve seen 100x qvd x database ratio
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
If u create a qvd the original data size will be compressed upto 10 times...
This is done by associative property.
The data is actually saved only once in all othyer places where it should be present is denoted by a pointer...
-Sundar
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
hi sundar
Can you please explain me how that is done by Associative property?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
PFA,
Please see page 8 and 9, they have explaine hoe data is compressed in qlikview.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Please go thro the below link for more info
http://www.quickintelligence.co.uk/qlikview-qvd-files/
Qvd file stores data in the format how data is handled in qlikview, so it is the best way to store and to be used.
hope this helps..
-Sundar
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Please go thro the below blog also
http://community.qlik.com/blogs/qlikviewdesignblog/2012/11/20/symbol-tables-and-bit-stuffed-pointers
-Sundar
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Sasikanth,
The way QlikView stores the data internally that makes difference,fetching data from QVD than Database.
Below example gives accurate picture of how it is done:
If I load a very simple dataset:
Fruit:
LOAD *
INLINE [
Fruit, Color
Banana, Yellow
Blueberry, Blue
Tomato, Red
Tomato, Green
];
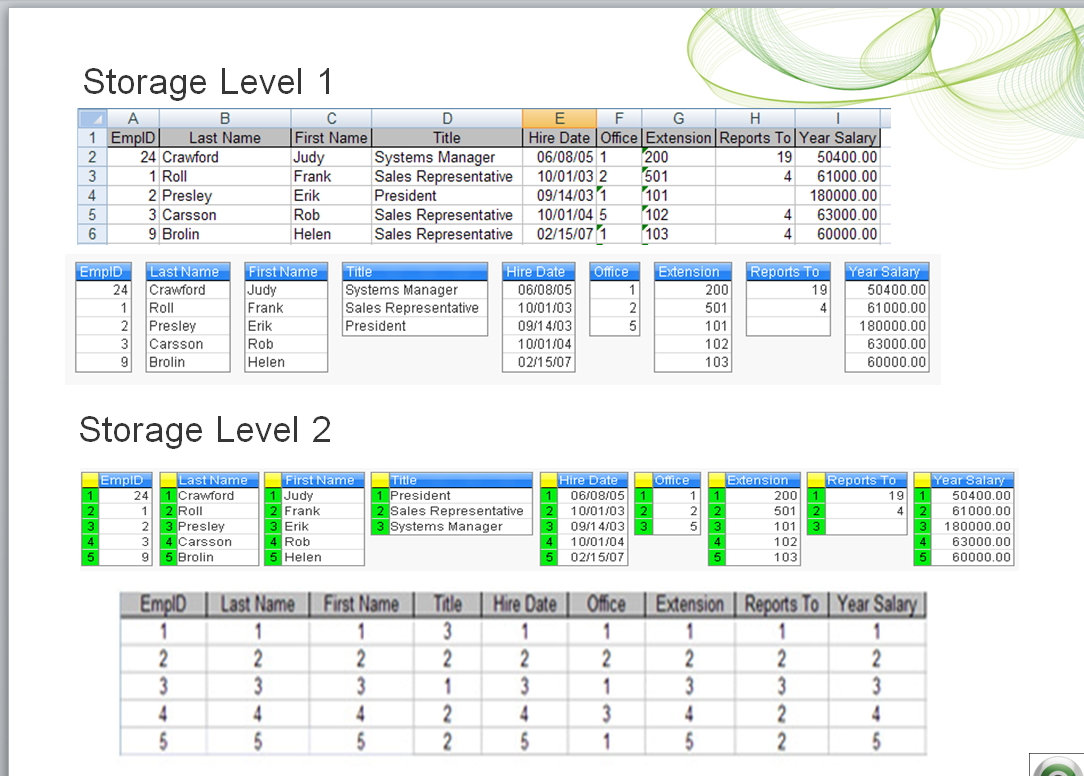
And then add both fields as list boxes, I see that there are only 3 fruit listed - even though I have loaded 4 entries. "Tomato" is only stored once by QlikView. Internally, there are binary keys keeping track of the association between "Tomato" along with "Red" and "Green".
In a large data set with a lot of repeating values (especially text values) the fact that each field value is only stored once means that there is a huge saving in the amount of memory needed to store the information. This is why QlikView can store so much data in memory.
Let's add another table of data:Colors:
LOAD * INLINE [
Color, Red, Green, Blue
Yellow, 255, 255, 0
Blue, 0, 0, 255
Red, 255, 0, 0
Green, 0, 255, 0
Amber, 255, 121, 0
];
I now might think that I have 2 tables of data - both of which have a field called "Color". But I don't! There is only one field called "Color" in our dataset and this field will have 5 values. Internally, the association between each of them and their associated values are maintained with binary keys. It just so happens that one of the values - "Amber" - is not associated with any of the values in the "Fruit" field.
Note that there is probably no direct association between "Fruit" and "Red". The association is indirect. However, because of the smaller data set in memory and the binary keys, the association is very fast.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi,
(1) Attached PPT will clearly explain how data is stored in QVD
(2) It fast because QVD is in Qlikview native format unlike database table
Thanks,
Chiru
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Sasikanth,
Please check below link for document compression:
http://qlikviewnotes.blogspot.co.uk/2011/03/qlikview-compression.html