Unlock a world of possibilities! Login now and discover the exclusive benefits awaiting you.
- Qlik Community
- :
- All Forums
- :
- QlikView App Dev
- :
- Dual dimensions: Performance curve with data?
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Dual dimensions: Performance curve with data?
Hi all, I am VERY new to Qlikview, and really struggling to understand how to use the expressions and really pull out the power for charting. My applications are very different from most of the sales data that is out there. I typically only have/need one dimension, i.e. Date, Power, Flow. My goal is to graph a performance curve (for which I have data of Power vs. Speed, or some similar correlation). I also have real operating data that I would like to plot on the same chart, so that I can see how the unit is performing with respect to its design. I have been able to create the performance curve, but I'm not able to successfully plot the data on the same curve. The data uses a different Power dimension than the Performance curve.
Any help would be greatly appreciated
- « Previous Replies
-
- 1
- 2
- Next Replies »
Accepted Solutions
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Kristan,
nice to meet a fellow engineer over here.
Here is one possible solution:
SET ThousandSep='.';
SET DecimalSep=',';
SET MoneyThousandSep='.';
SET MoneyDecimalSep=',';
SET MoneyFormat='#.##0,00 €;-#.##0,00 €';
SET TimeFormat='hh:mm:ss';
SET DateFormat='DD.MM.YYYY';
SET TimestampFormat='DD.MM.YYYY hh:mm:ss[.fff]';
SET MonthNames='Jan;Feb;Mrz;Apr;Mai;Jun;Jul;Aug;Sep;Okt;Nov;Dez';
SET DayNames='Mo;Di;Mi;Do;Fr;Sa;So';
RENAME Table Sheet1 to tabUMassSTG1Efficiency;
RENAME Table [Sheet1-1] to tabPerformanceData;
tabData:
LOAD
[Turbine Power (kW)] as [Power (kW)],
Avg([STG1_Inlet_Steam_Flow]) as [Flow (lbm/hr)],
'measured' as DataType
Resident tabPerformanceData
Group By [Turbine Power (kW)];
LOAD
Power as [Power (kW)],
[Flow rate] as [Flow (lbm/hr)],
'calculated' as DataType
Resident tabUMassSTG1Efficiency;
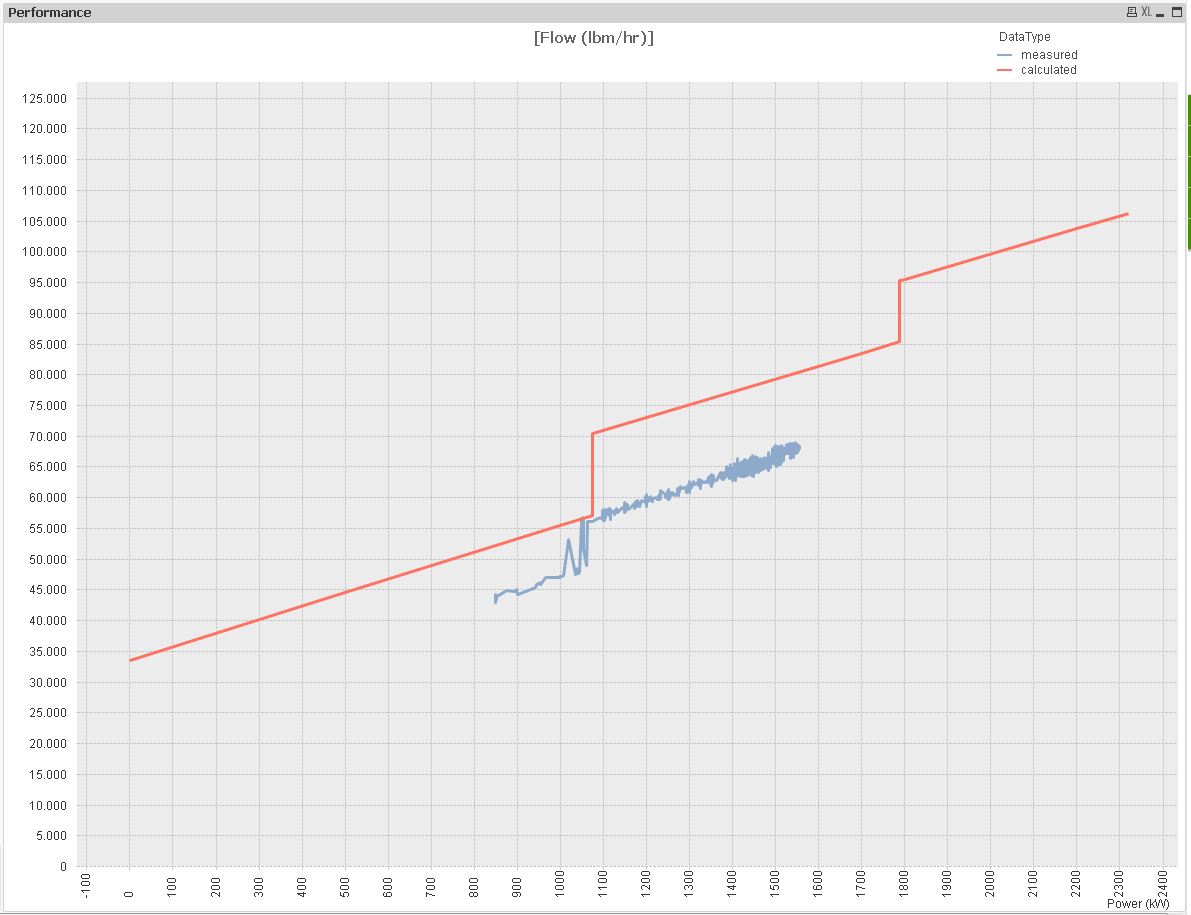
To create a scatter plot, you need to use e.g. the date field as the dimension and the flow and power as expressions.
That's why you get this missing expression message.
I included an example for this chart also:
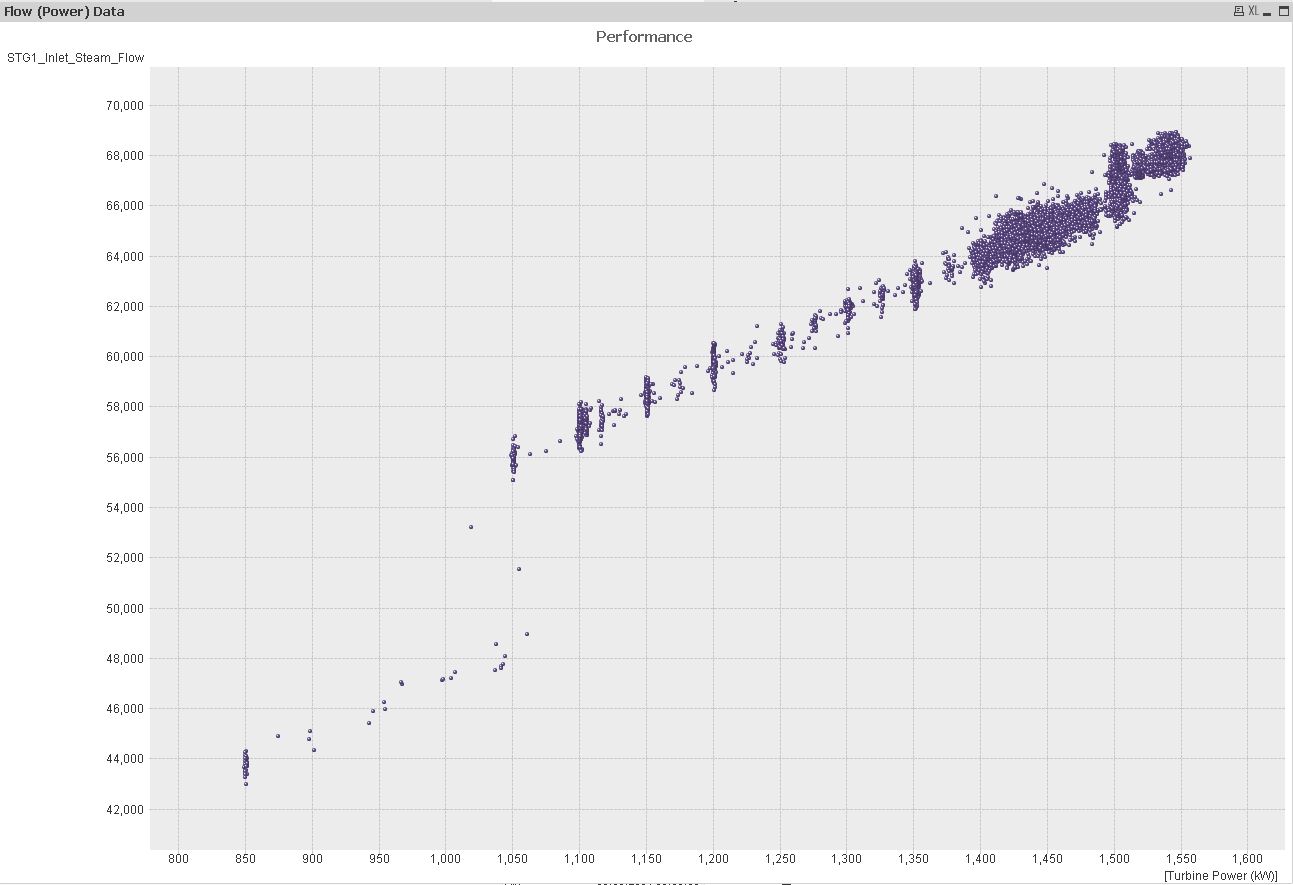
hope this might help
regards
Marco
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Would it be possible for you to provide a sample QVW file with some example data? This would make it easier to suggest a solution or way forward.
If possible please clarify what the expected chart result should look like, as I am not sure I completely got the intention or problem in your screenshot.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
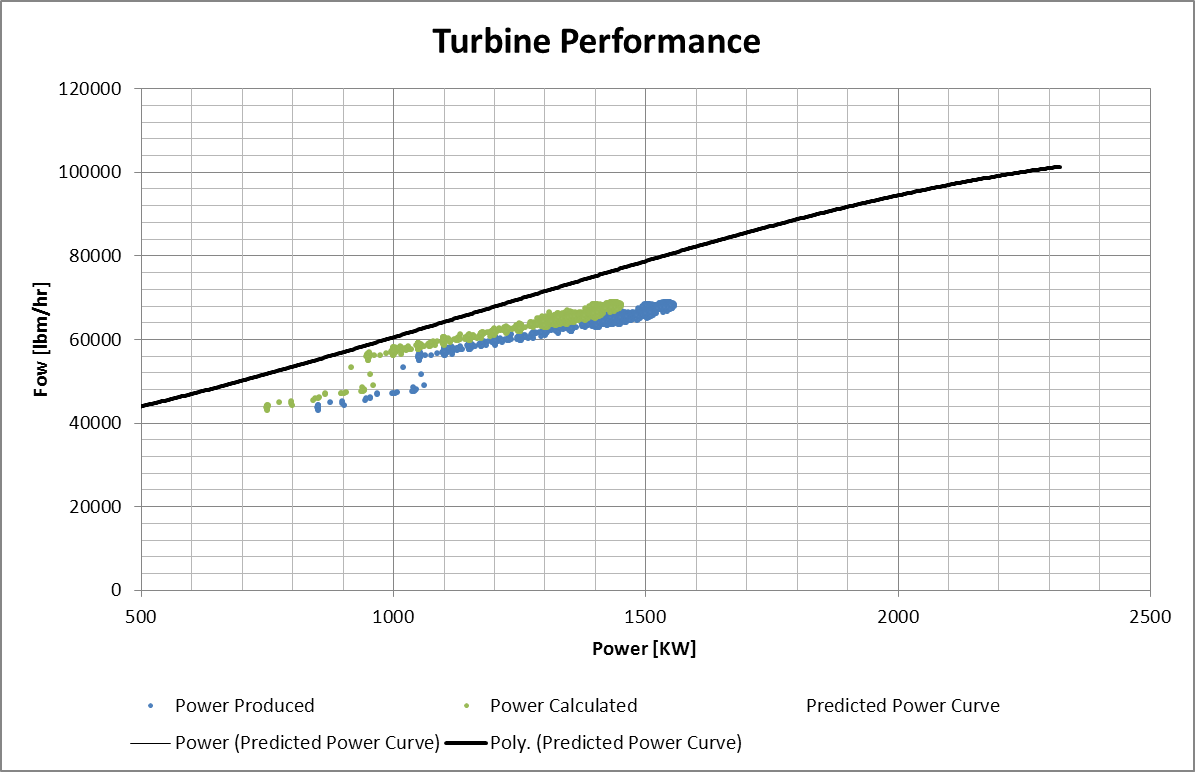
On the one hand, I see a lot of power and value in what Qlikview can do. On the other hand, the learning curve is SO steep that there are things that make me want to tear my hair out. Simple things like this are one of them.
In the attached .qvw file, I have plotted the performance curve "Flow (Power) Curve". This is the OEM predicted performance. Edit: One other note: to get the curve to show as provided from the OEM, I had to "cheat" the data by adding 0.01 to the repeated values on the power list box. The chart functions don't like to handle duplicate dimensions values well.
"Power (Date)" is the actual power output that was captured based on the date it was recorded.
"Flow (Power) Data" is the flow, plotted as a function of power, but comes from the same date-recorded data set as the Power data. I don't understand why I can't do a scatter plot with this data - "Too Few Expressions." Huh?
I want to combine (overlay) the charts in the top left and bottom right corners.
Thanks in advance for any help.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Any thoughts on how to do this?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Kristan,
nice to meet a fellow engineer over here.
Here is one possible solution:
SET ThousandSep='.';
SET DecimalSep=',';
SET MoneyThousandSep='.';
SET MoneyDecimalSep=',';
SET MoneyFormat='#.##0,00 €;-#.##0,00 €';
SET TimeFormat='hh:mm:ss';
SET DateFormat='DD.MM.YYYY';
SET TimestampFormat='DD.MM.YYYY hh:mm:ss[.fff]';
SET MonthNames='Jan;Feb;Mrz;Apr;Mai;Jun;Jul;Aug;Sep;Okt;Nov;Dez';
SET DayNames='Mo;Di;Mi;Do;Fr;Sa;So';
RENAME Table Sheet1 to tabUMassSTG1Efficiency;
RENAME Table [Sheet1-1] to tabPerformanceData;
tabData:
LOAD
[Turbine Power (kW)] as [Power (kW)],
Avg([STG1_Inlet_Steam_Flow]) as [Flow (lbm/hr)],
'measured' as DataType
Resident tabPerformanceData
Group By [Turbine Power (kW)];
LOAD
Power as [Power (kW)],
[Flow rate] as [Flow (lbm/hr)],
'calculated' as DataType
Resident tabUMassSTG1Efficiency;
To create a scatter plot, you need to use e.g. the date field as the dimension and the flow and power as expressions.
That's why you get this missing expression message.
I included an example for this chart also:
hope this might help
regards
Marco
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
How to calculate the Power produced and power calculated?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
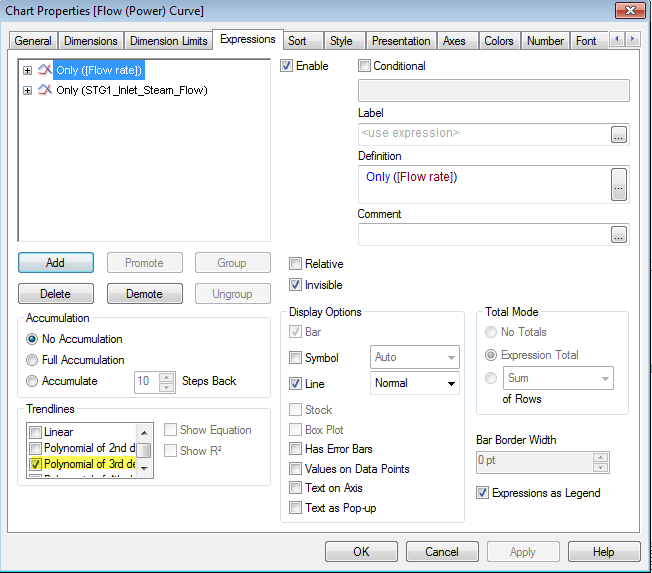
To get rid of the steep graph and get a curved shape. Try selecting Polynomial of 3rd degree.
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Marco, thanks so much. This helps a lot. I was hoping I would bump into a fellow engineer who could point me in the right direction.
I am still trying to learn the scripting language, so I hope you'll bear with me as I ask a couple of questions
- Why the binary header? what function does that serve? I have seen references to "binary" in others posts.
- Why rename the sheets? Is it confusing Qlikview to have data from two sources called "Sheet1"?
- Why do you take the Avg([STG1_Inlet_Steam_Flow])?
- Can you explain the Resident and Group By functions? I looked them up, but I don't fully understand how those are being used here.
Thanks again,
-Kristan
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Marco,
Another question. I have 1-year of data, loaded from a CSV file for each day, now stored in a .QVD file. The file is too large for me to post. For the portion of the script that handles the actual turbine data,
- tabData:
- LOAD
- [Turbine Power (kW)] as [Power (kW)],
- Avg([STG1_Inlet_Steam_Flow]) as [Flow (lbm/hr)],
- 'measured' as DataType
- Resident tabPerformanceData
- Group By [Turbine Power (kW)];
If this is coming from the QVD, how would I modify this to handle that?
Thanks again for all your help.
-Kristan
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Kristan,
1. I used the binary load for convenience purposes only. It was the easiest way to load the data into my application, because I didn't have your Excel sources. You wouldn't use this load in your application though.
2. renaming the sheets was just done for a better readability of the code. QlikView doesn't matter, what names the tables have.
3. I created an additional table that did not include the date field, so I had to combine the power and flow fields. There are a few cases with more than one flow value per power value, so I used the average flow.
4. the resident load simply loads data from already loaded tables. Using the binary load I had all the data in the application. To create a combined table for measured and calculated values, I used the resident load.
The "group by" bit is needed because of the aggregation (avg flow) in this load statement.
This load says "create a table, that contains all distinct power values and the average flow values for each of them"
hope this clarifies a bit.
regards
Marco
- « Previous Replies
-
- 1
- 2
- Next Replies »