Unlock a world of possibilities! Login now and discover the exclusive benefits awaiting you.
- Qlik Community
- :
- All Forums
- :
- QlikView App Dev
- :
- setanalysis , avg and AGGR in a single expression
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
setanalysis , avg and AGGR in a single expression
Hello guys I want to solve the following Problem, can someone please help me out.
AGGR(Max(Date(Date#(ENDDATE,'YYYYMMDD'),'DD/MM/YYYY') ) - Min(Date(Date#(STARTDATE,'YYYYMMDD'),'DD/MM/YYYY') ), PROGRAM))/count(DISTINCT PROGRAM)
how to solve this :
First I am calculating the Max of ENDDATE
Then Min of STARTDATE
and Then i Need to find the AVG(MAX(ENDDATE)-MIN(STARTDATE))
and then I Need to Calculate this avg per program : this is something like static values AVG(MAX(ENDDATE)-MIN(STARTDATE)) for PROGRAM A, AVG(MAX(ENDDATE)-MIN(STARTDATE)) for PROGRAM B etc.,
My calculation is getting me 90% of result when i compare with original data.
Can i use Setanalysis, AVG and AGGR in a single Expression.
The challenging thing is the dimension iam using in AGGR and SETANALYSIS would be the same.
Thanks
Mark
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Provide sample data please..
or instead of
count(DISTINCT PROGRAM)
use
Aggr(count(PROGRAM),PROGRAM)
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
datasets are complex and confidential, so its a bit difficult to share.
But just let me know how to resolve the above Expression.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Interval(Max(Date(Date#(ENDDATE,'YYYYMMDD'),'DD/MM/YYYY') ) - Min(Date(Date#(STARTDATE,'YYYYMMDD'),'DD/MM/YYYY'),'dd')/count(DISTINCT PROGRAM)
or
Interval(Max(Date(Date#(ENDDATE,'YYYYMMDD'),'DD/MM/YYYY') ) - Min(Date(Date#(STARTDATE,'YYYYMMDD'),'DD/MM/YYYY'),'dd')/count(PROGRAM)
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hello marks,
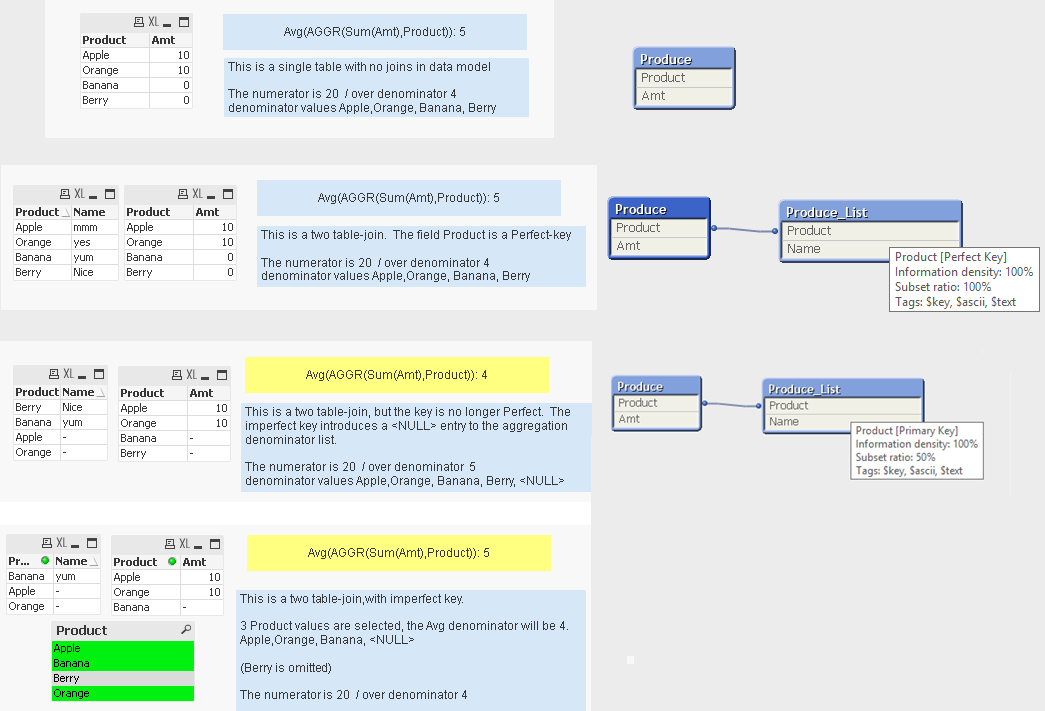
Not sure if this will apply to your situation exactly, but here's an illustration of what can happen with the Avg(Aggr()) combination that can cause unexpected results (and how the impacts may come from the data model).
If you set up Avg(Aggr()) expressions against a single table or a table with perfect keys, the calculations should yield expected results. And sometimes initial testing is done against a single table or a table with a perfect key, and it seems everything is working right. Then perhaps only later, if the perfect key of that table somehow changes to an imperfect key, calculations may be impacted in ways that might not be expected.
Once the fields involved in the Avg(Aggr()) calculation are joined to other tables with a non-Perfect key, the introduction of an entry for <NULL> potentially joins the denominator value list. It also depends on whether the actual field in the calculation is the keyfield and whether selections are applied or not.
- Perfect key - <NULL> NOT introduced in denominator
- Imperfect key - no selections applied - <NULL> introduced in denominator
- Imperfect key - selections in filtering field applied (key or non-key)
- all selections have entry in calculation field - <NULL> NOT introduced in denominator
- any selection has a null value in calculation field - <NULL> introduced in denominator
I know these scenarios may seem complicated, but identifying them has helped me manage the Avg(Aggr()) combinations, and maybe this will help you.