Unlock a world of possibilities! Login now and discover the exclusive benefits awaiting you.
- Qlik Community
- :
- Forums
- :
- Groups
- :
- Location and Language
- :
- Россия и СНГ
- :
- Расчет прироста от Акций
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Feature this Topic
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Расчет прироста от Акций
Добрый день Коллеги! Возник вопрос. Нужно посчитать прирост от проведения акций. Но я все никак не пойму как это сделать.
Вот пример.
Надо реализовать на подобии такой таблицы:
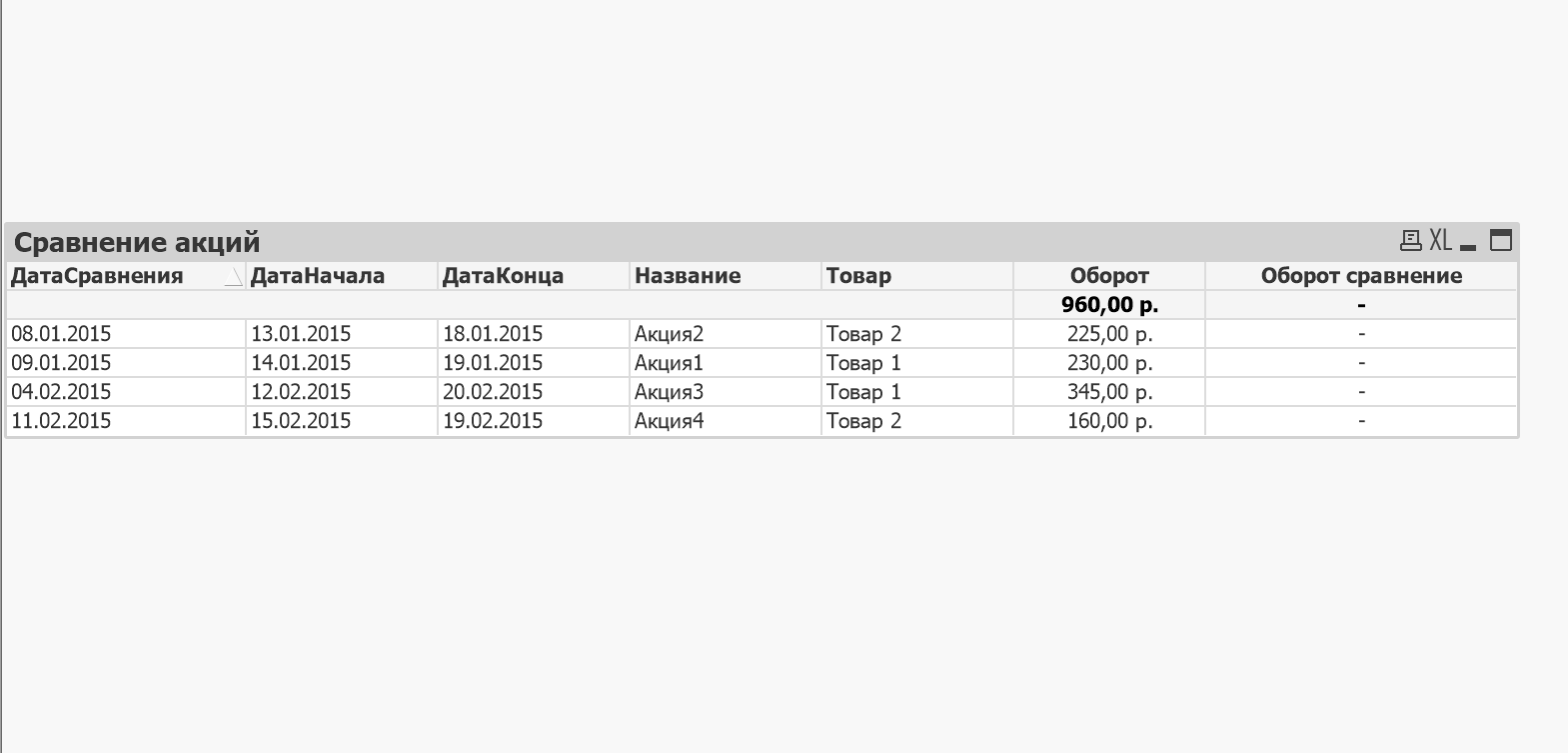
Дата начала и дата конца это время проведения Акции. Дата сравнения это Дата начала акции минус ее длительность. Соответственно нужно подсчитать оборот за промежуток Дата сравнение и Дата начала.
Как это можно реализовать?
Пример с данными во вложении.
- Tags:
- Group_Discussions
Accepted Solutions
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Ваша идея использования функции IntervalMatch в данном случае абсолютно верна, т.к. по сути необходимо выполнять сопоставление объемов продаж за различные периоды времени.
Т.е. фактически нам необходимо последовательно "разметить" имеющиеся даты продаж для каждой из акций, сохранив атрибут разметки в одном или нескольких полях. Разметка должна проводиться по правилам:
- Даты относящиеся к периоду проведения акции [ДатаНачала <= x <= ДатаКонца]
- Даты относящиеся к периоду за который вы проводите сравнение, т.е.
[ДатаНачала - (ДатаКонца - ДатаНачала) - 1 <= x <= ДатаНачала - 1]. Обращаю внимание на то, что при расчете дат периода сравнения нужно не забыть отнять единицу, чтобы периоды сравнения и периоды проведения акций не пересекались. Также при использовании функции IntervalMatch всегда будьте внимательны, т.к. она выполняет сопоставление периодов включая граничные значения интервала.
После разметки расчет в объекте визуализации делается стандартным отбором значений по ранее рассчитанному признаку (выражение set-анализа).
В присоединенном примере я привел два варианта формирования таблицы данных в модели:
- В первом варианте для хранения признака используется одно и то же поле, в котором хранятся два варианта значений признака, т.е. при построении модели получаем более длинную таблицу.
- Во втором варианте для хранения признака используется два поля, т.е. при построении модели получаем потенциально более короткую, но и более "широкую" таблицу.
Поскольку 100% правильного варианта хранения подобных признаков нет, то выбирайте любой вариант, который окажется предпочтительнее для решения именно вашей задачи.
Каждый из вариантов сценария загрузки приведен на отдельной закладке ("Вариант 1" или "Вариант 2"), как и соответствующие каждому варианту объекты визуализации приведены на одноименных листах приложения.
Очевидно, что с точки зрения оптимизации, от автоматически создающегося синтетического ключа также имеет смысл избавиться, например, путем создания составного ключа.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Ваша идея использования функции IntervalMatch в данном случае абсолютно верна, т.к. по сути необходимо выполнять сопоставление объемов продаж за различные периоды времени.
Т.е. фактически нам необходимо последовательно "разметить" имеющиеся даты продаж для каждой из акций, сохранив атрибут разметки в одном или нескольких полях. Разметка должна проводиться по правилам:
- Даты относящиеся к периоду проведения акции [ДатаНачала <= x <= ДатаКонца]
- Даты относящиеся к периоду за который вы проводите сравнение, т.е.
[ДатаНачала - (ДатаКонца - ДатаНачала) - 1 <= x <= ДатаНачала - 1]. Обращаю внимание на то, что при расчете дат периода сравнения нужно не забыть отнять единицу, чтобы периоды сравнения и периоды проведения акций не пересекались. Также при использовании функции IntervalMatch всегда будьте внимательны, т.к. она выполняет сопоставление периодов включая граничные значения интервала.
После разметки расчет в объекте визуализации делается стандартным отбором значений по ранее рассчитанному признаку (выражение set-анализа).
В присоединенном примере я привел два варианта формирования таблицы данных в модели:
- В первом варианте для хранения признака используется одно и то же поле, в котором хранятся два варианта значений признака, т.е. при построении модели получаем более длинную таблицу.
- Во втором варианте для хранения признака используется два поля, т.е. при построении модели получаем потенциально более короткую, но и более "широкую" таблицу.
Поскольку 100% правильного варианта хранения подобных признаков нет, то выбирайте любой вариант, который окажется предпочтительнее для решения именно вашей задачи.
Каждый из вариантов сценария загрузки приведен на отдельной закладке ("Вариант 1" или "Вариант 2"), как и соответствующие каждому варианту объекты визуализации приведены на одноименных листах приложения.
Очевидно, что с точки зрения оптимизации, от автоматически создающегося синтетического ключа также имеет смысл избавиться, например, путем создания составного ключа.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Спасибо Сергей! Кажется это то что нужно. Была подобная мысль, но не довел ее до конца. Вопрос на засыпку- Реально ли решить этот пример используя только set analysis? Например динамически рассчитывая каждую строчку в таблице сравнения по значению столбцов Начальная дата сравнения и конечная дата.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Задачу расчета сравнения продаж до и во время проведения акции безусловно можно решить с использованием Set-анализа. Но вот вопросы желаемой визуализации результатов при этом нужно рассматривать более детально.
Например, вы можете написать формулу расчета продаж за период акции 'Акция1' в виде:
Sum( { 1 < НазваниеАкции = {'Акция1'},
Дата = {">=$(=Minstring( {< ДатаНачала = P( {< НазваниеАкции = {'Акция1'} >} ДатаНачала) >} ДатаНачала))<=$(=Minstring( {< ДатаКонца = P( {< НазваниеАкции = {'Акция1'} >} ДатаКонца) >} ДатаКонца))"}
>} Сумма)
и разместить ее в текстовом объекте. Такую же формулу можно написать для других Акций, заменив в ней значение модификатора поля НазваниеАкции на значение 'Акция2'. В третьей формуле - на 'Акция3' и так далее. Очевидно, что аналогичные формулы можно написать для периода сравнения по каждой акции.
Но если для отображения результатов мы захотим использовать стандартный объект Диаграмма (Таблица), то картина изменится.
Дело в том, что основная идея быстрого расчета значений в таблицах состоит в том, что для Выражения диаграммы описанного с использованием синтаксиса Set-анализа, процесс расчета состоит из двух этапов:
- Расчет подмножества значений на основании описанного модификатора множества (т.е. отбор только тех значений, для которых расчет имеет смысл). И это подмножество рассчитывается вне контекста измерений диаграммы.
- Для используемых в Выражении диаграммы функций агрегации включается контекст, т.е. функция агрегации рассчитывается по каждому из значений измерений с использованием значений отобранного ранее подмножества.
Указанный подход позволяет минимизировать время расчета значений Выражения диаграммы за счет использования минимально возможного набора значений по которым производится расчет и отсутствия каких-либо последующих проверок при вычислениях. Т.к. расчет подмножества возможного набора значений производится вне контекста измерений Диаграммы, то очевидно, что мы не имеем возможности подставлять в модификатор значение самого измерения, динамически изменяющееся от одной строки таблицы к другой.
Поэтому если мы захотим, чтобы в объекте Таблица в каждой из строк модификаторы задавались уникальным образом, то не останется ничего другого, кроме как оценивать оператором If( RowNo()) номер строки и формировать для каждой из строк свой модификатор. Т.е. технически это возможно, но:
- При большом количестве элементов измерения это становится нереальным, т.к. конструкцию If( RowNo()) придется описывать столько раз, сколько элементов измерений у вас должно присутствовать в таблице. Очевидно, что этот способ не будет работать для изменяющегося количества элементов измерений (в вашем случае - меняющемся количестве Акций).
- Выражение диаграммы становится очень сложным, т.к. помимо приведенного выше примера функции, вам придется вкладывать их в конструкции If(), а затем сами конструкции If() вкладывать друг в друга.
- Расчеты становятся неоптимальными с точки зрения быстродействия, т.к. по сути для расчета каждого значения в таблице, Qlik будет вынужден проводить анализ ваших вложенных конструкций If().
Прикрепил пример приложения с третьим вариантом, в котором скрипт загрузки является предельно простым, но за это приходится расплачиваться сложностью выражений в объектах визуализации. Поэтому несмотря на существенную гибкость Qlik, обеспечивающую возможность решения одних и тех же задач как с использованием сценария загрузки, так и с использованием объектов визуализации, следует всегда оценивать сложность и оптимальность различных вариантов решения применительно к конкретной задаче.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Огромное спасибо за развернутый ответ!