Unlock a world of possibilities! Login now and discover the exclusive benefits awaiting you.
- Qlik Community
- :
- Forums
- :
- Analytics
- :
- New to Qlik Analytics
- :
- Qlik Sense Accumulate outside range visible in Gra...
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Qlik Sense Accumulate outside range visible in Graph
I am trying to show a snapshot in time of values which are accumulated based on [TRX Date].
The problem is that when I filter my graph to a specific time interval its accumulation ignores any values prior to the first date in the view.
It may be worth noting that the data is not necessarily in order of [TRX Date] in the source table.
As an example if I want to show someone the sum as at the end of the 5th and 6th of December respectively and the source data looks like this...
| [TRX Date] | [Debit]- [Credit] |
|---|---|
| 06/12/2014 | 3 |
| 04/12/2014 | 4 |
| 05/12/2014 | 5 |
| 07/12/2014 | 2 |
...then the output should be like this once I have filtered to the 5th and the 6th
| [TRX Date] | Accumulated [Debit]- [Credit] |
|---|---|
| 05/12/2014 | 9 |
| 06/12/2014 | 12 |
As you can see in the snaps below, the Y-axis ( [Debit] - [Credit] ) resets to show only the $2m movement on the 16th rather than start at around $75m after the filter excludes the dates prior. The x-axis shows [TRX Date].
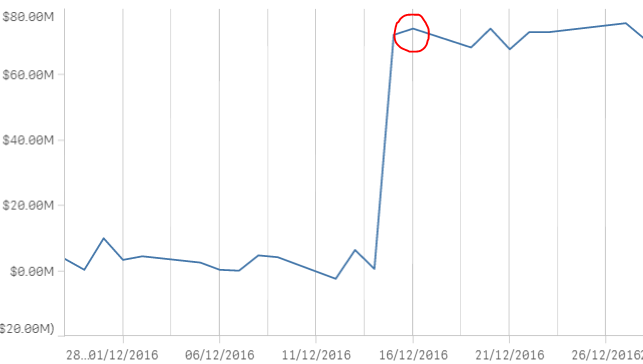
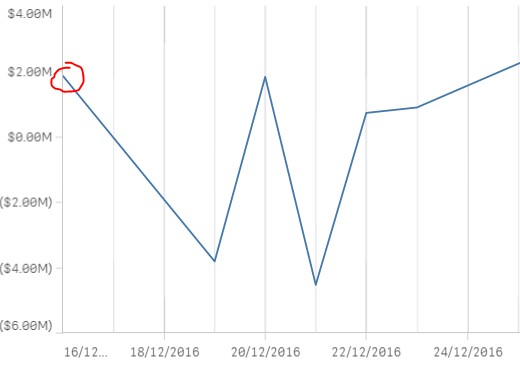
This is the syntax I have been trying
rangesum( above(
sum({$<[Segment 1]={'00'}, [Segment 2]={'00'}, [Segment 3]={'999'}, [Nominal Code]={'7120'}, OriginatingCurrency={'USD'}, LineRef -= {'Balance Brought Forward'} >}([Debit]-[Credit])/1000000)
,0,rowno()))
Accepted Solutions
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Amir,
There is an offer to transfer the accumulation to the level of the script, creating it in a separate field.
As variant
TableSource:
LOAD*Inline
[TRX Date, Debit- Credit
06/12/2014, 3
04/12/2014, 4
05/12/2014, 5
07/12/2014, 2];
NoConcatenate
Table1:
Load
Date(Date#([TRX Date], 'DD/MM/YYYY')) as [TRX Date] ,
[Debit- Credit],
RangeSum( [Debit- Credit], peek( 'DebitCreditSum' ) ) as DebitCreditSum //accumulation field
Resident TableSource
Order By [TRX Date];
Drop Table TableSource;
Example implementation in the attached file QVF.
Regards,
Andrey
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Does anyone know how to do this?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Amir,
There is an offer to transfer the accumulation to the level of the script, creating it in a separate field.
As variant
TableSource:
LOAD*Inline
[TRX Date, Debit- Credit
06/12/2014, 3
04/12/2014, 4
05/12/2014, 5
07/12/2014, 2];
NoConcatenate
Table1:
Load
Date(Date#([TRX Date], 'DD/MM/YYYY')) as [TRX Date] ,
[Debit- Credit],
RangeSum( [Debit- Credit], peek( 'DebitCreditSum' ) ) as DebitCreditSum //accumulation field
Resident TableSource
Order By [TRX Date];
Drop Table TableSource;
Example implementation in the attached file QVF.
Regards,
Andrey
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thanks Andrey, I'll try this out later
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I suggest you go with the AsOf calendar method.
This is a very flexible way of accumulating values, outside of the visual scope.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thanks, it works for that limited table (only TRX Date and Debit-Credit columns). However, since the real data has more columns I tried adding complexity by simulating a 'Nominal Code' column scattered randomly in the mix. This seems to throw off the values (e.g. it says 8 on the 4th which I was expecting to be 4, 13 on the 5th which should be 14 etc.)
Attaching the qvf file which includes the new set analysis in the table and the adjusted load script
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi again,
I realised it was because I forgot to add the new column (Nominal Code) to the 'Sort By'. Once I did that it worked! Attached file shows final version which works. Thank you so much for your help!
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Andrey,
I tried to use this code to test the concept on a more complex source table which is more akin to the live data.
I have the test data in an excel sheet but cannot seem to get the modified load script to work. Can you see what I've done wrong?
Table1:
LOAD [Journal Entry],
[Segment 1],
[Segment 2],
[Segment 3],
[Nominal Code],
[Series],
Date(Date#([TRX Date], 'DD/MM/YYYY')) as [TRX Date],
[Account Number],
[Account Description],
[Debit Amount],
[Credit Amount],
[Originating Currency],
[Description],
[LineRef],
[OriginatingDebit],
[OriginatingCredit],
[Batch Number],
[Back Out JE],
[Correcting JE],
[Originating Source],
RangeSum( [OriginatingDebit]-[OriginatingCredit], peek( 'DebitCreditSum' ) ) as DebitCreditSum
Resident Sheet1
Order By [LineRef],[Nominal Code],[TRX Date];
Drop Table Sheet1;
FROM [lib://Qlik/7100 Early test data for Qlik accumulation.xlsx]
(ooxml, embedded labels, table is Sheet1);