Unlock a world of possibilities! Login now and discover the exclusive benefits awaiting you.
- Qlik Community
- :
- All Forums
- :
- Connectivity & Data Prep
- :
- Qlik CSV load fails to detect duplicate fields' na...
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Qlik CSV load fails to detect duplicate fields' names
Hello all,
Here is the scenario:
I do have a CSV file that has several identical fields' names:
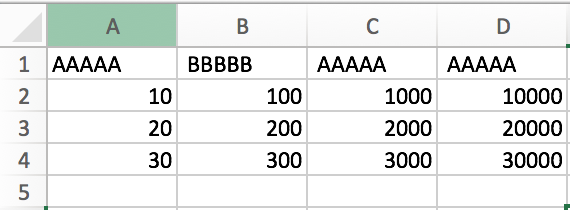
Loading this file in the original CSV format creates a problem since QS does not detect the duplicate fields' names until the actual script's loading.
The script it generated as:

Which requires fields renaming before the load:

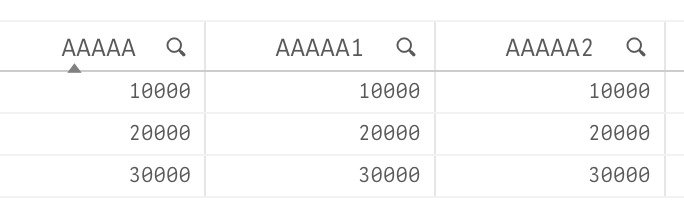
The problem is that Qlik loads the data for all these AAAAA fields from the last (??!!) field listed in the table:
Here is the result:
Using "Data Manager" and "Add Data" mode produces even more radical solution. Qlik just ignores duplicate fields:
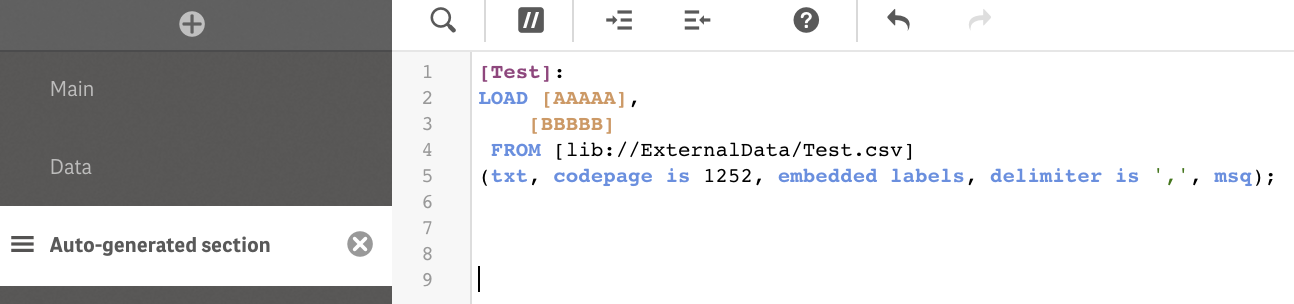
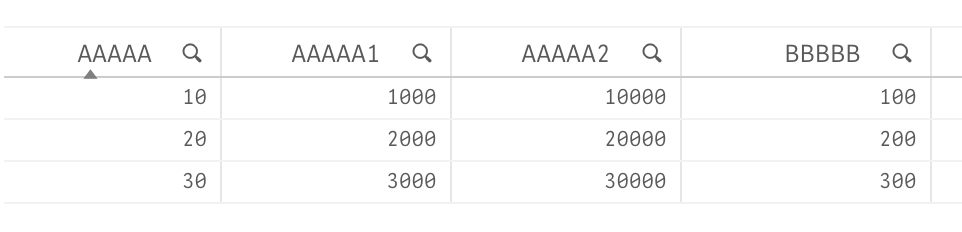
The same file converted to XLS format works fine. Qlik recognizes duplicates and generates the script as:

Which produces the proper result:
Any reason Qlik has not applied the same logic to CSV load?
I know that I can ignore file's Header and load data as @1, @2, ... @n fields... Which requires a lot of fields' renaming (I am loading US Census data with 500+ columns) and is not very stable because of the possible data structure changes....
I also know that this is a legacy issue and was discussed here few times (Same Field Names) and (Re: Reload Excel file with duplicate field name). But I am just wondering if any other solution would be suggested....
Appreciate a feedback and suggestions...
Regards,
Vlad