Unlock a world of possibilities! Login now and discover the exclusive benefits awaiting you.
- Qlik Community
- :
- All Forums
- :
- QlikView App Dev
- :
- Too much for if...
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Too much for if...
Hello,
I've a csv-table with almost 2 million rows.
Amongst others there some columns I want to "change".
For example:
Column "Test10" contains amonst others following data:
"Example1, Example2, Example4, Example5"
"Example1, Example4, Example5, Example6"
"Example1, Example2, Example6"
"Example2, Example4"
"Example1, Example2, Example4, Example5, Example7"
Now I want to put every "Example..." as a own row in a new column called "NewColumn" and when I select one of these, every row of column "Test10" which contains the selected "Example..." should be marked too.
I tried to use if, but there are more than 100 distinct "Example..."-entries.
- Tags:
- qlikview_scripting
Accepted Solutions
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Jens,
First off, you'd have to change the double quotes to single quotes so it's possible do identify a single field from your csv for the Example1, Example2, ... field.
On your original file, all of the Example values should be enclosed by single quotes, like:
'Example1, Example2, Example4, Example5'
Second, once you load that up, you'll just have to use the subfield() statement to separate all the "Example"s into one field.
For the dummy data in the teste.csv file attached, the following code:
LOAD
Col1,
Col2,
Col3,
trim(subfield(Col4,',')) as Teste
FROM
(txt, codepage is 1252, embedded labels, delimiter is ',', msq);
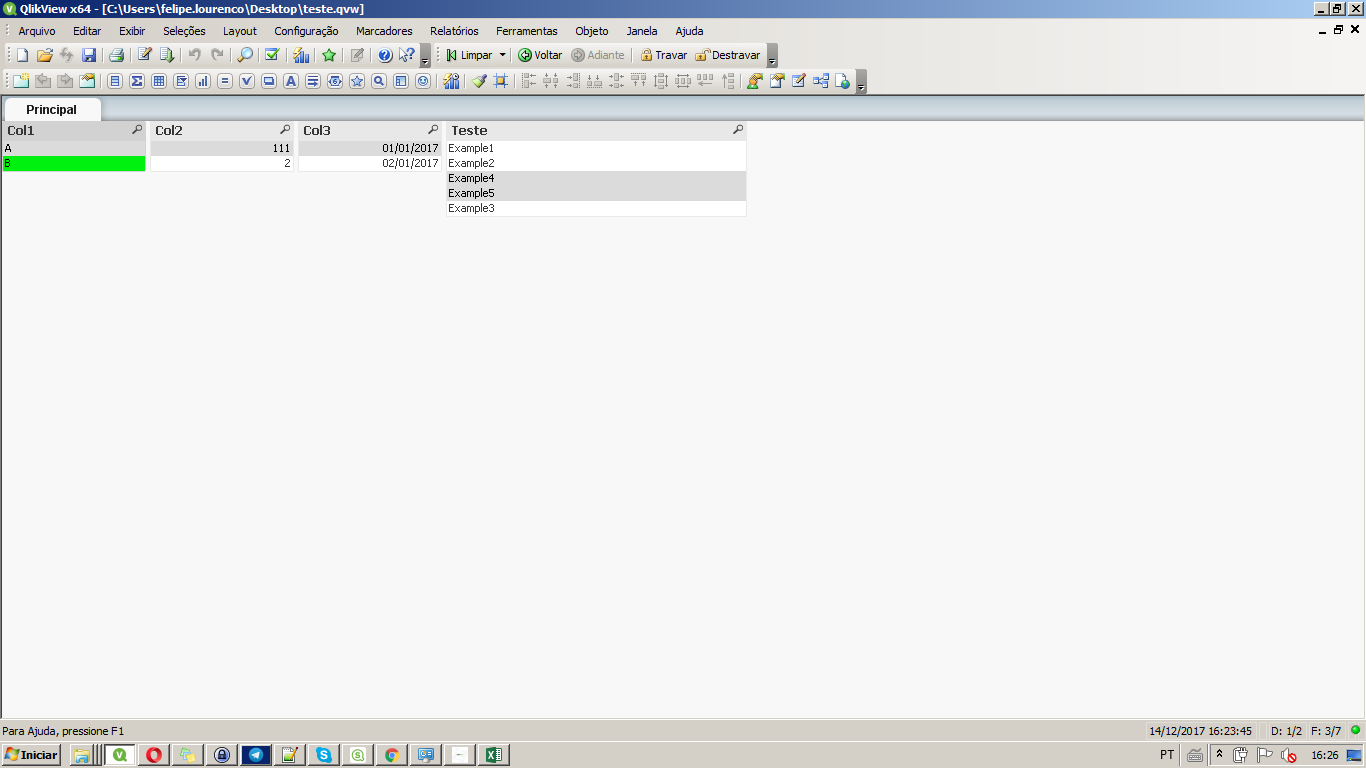
Gets the following in Qlik:
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Jens,
First off, you'd have to change the double quotes to single quotes so it's possible do identify a single field from your csv for the Example1, Example2, ... field.
On your original file, all of the Example values should be enclosed by single quotes, like:
'Example1, Example2, Example4, Example5'
Second, once you load that up, you'll just have to use the subfield() statement to separate all the "Example"s into one field.
For the dummy data in the teste.csv file attached, the following code:
LOAD
Col1,
Col2,
Col3,
trim(subfield(Col4,',')) as Teste
FROM
(txt, codepage is 1252, embedded labels, delimiter is ',', msq);
Gets the following in Qlik:
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi,
one solution might be:
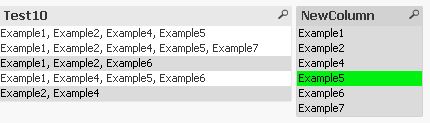
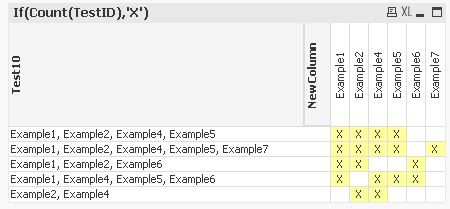
tabTests:
LOAD RecNo() as TestID, *
INLINE [
Test10
"Example1, Example2, Example4, Example5"
"Example1, Example4, Example5, Example6"
"Example1, Example2, Example6"
"Example2, Example4"
"Example1, Example2, Example4, Example5, Example7"
];
tabExamples:
LOAD TestID,
Trim(SubField(Test10,',')) as NewColumn
Resident tabTests;
hope this helps
regards
Marco
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Guys,
thank you for your answers... I didn't notice, that I can use SubField without telling, which block it should use. That's very helpful.
It worked with it... 
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
The Subfield will create additional rows based on how many delimiters the field has, on my example:
A,111,01/01/2017,'Example1, Example2, Example4, Example5'
B,2,02/01/2017,'Example1, Example2, Example3'
Becomes:
Col1 Col2 Col3 Teste
A 111 01/01/2017 Example1
A 111 01/01/2017 Example2
A 111 01/01/2017 Example4
A 111 01/01/2017 Example5
B 2 02/01/2017 Example1
B 2 02/01/2017 Example2
B 2 02/01/2017 Example3
Depending on how many combinations you have (you mentioned some up to 100) it can increase your data a lot.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Yes, thank you...
I noticed that after I postetd unfortunatelly... Now my edited post must be moderated first
Thanks a lot for your help!
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Glad to help .