Unlock a world of possibilities! Login now and discover the exclusive benefits awaiting you.
- Qlik Community
- :
- Forums
- :
- Groups
- :
- Location and Language
- :
- Россия и СНГ
- :
- Создание строк с полным перечнем дат из интервала ...
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Feature this Topic
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Создание строк с полным перечнем дат из интервала дат
Здравствуйте! Подскажите, пожалуйста, решение следующей задачи.
Есть статьи расходов, расчет которых нужно начинать с Даты1 и заканчивать Датой2.
| Статья | Дата начала включения в расчет | Дата окончания включения в отчет | Сумма ежедневная |
| Конференция | 01.05.2018 | 03.05.2018 | 50667 |
| расход | 01.05.2018 | 07.05.2018 | 57 |
Как сделать таблицу, чтобы было видна детализация на каждый день:
| Статья | Дата | Сумма ежедневная |
| Конференция | 01.05.2018 | 50667 |
| Конференция | 02.05.2018 | 50667 |
| Конференция | 03.05.2018 | 50667 |
| расход | 01.05.2018 | 57 |
| расход | 02.05.2018 | 57 |
| расход | 03.05.2018 | 57 |
| расход | 04.05.2018 | 57 |
| расход | 05.05.2018 | 57 |
| расход | 06.05.2018 | 57 |
| расход | 07.05.2018 | 57 |
Спасибо за помощь!
- Tags:
- Group_Discussions
Accepted Solutions
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Спасибо! Проблема решена!
Код:
[Интервалы]:
LOAD
[Дата начала включения в расчет],
[Дата окончания включения в отчет],
Статья,
[Сумма ежедневная]
FROM
(ooxml, embedded labels, table is исходные);
INNER JOIN
LOAD DISTINCT [Дата начала включения в расчет],
[Дата окончания включения в отчет],
AutoNumberHash128([Дата начала включения в расчет],[Дата окончания включения в отчет]) as [Интервал времени]
Resident [Интервалы];
[Даты]:
LOAD
Дата
FROM
(ooxml, embedded labels, table is периоды);
[Таблица соединения]:
Intervalmatch ([Дата]) LOAD [Дата начала включения в расчет] as [Начало интервала],[Дата окончания включения в отчет] as [Окончание интервала] Resident [Интервалы];
INNER JOIN
LOAD DISTINCT [Начало интервала],
[Окончание интервала],
AutoNumberHash128([Начало интервала],[Окончание интервала]) as [Интервал времени]
Resident [Таблица соединения];
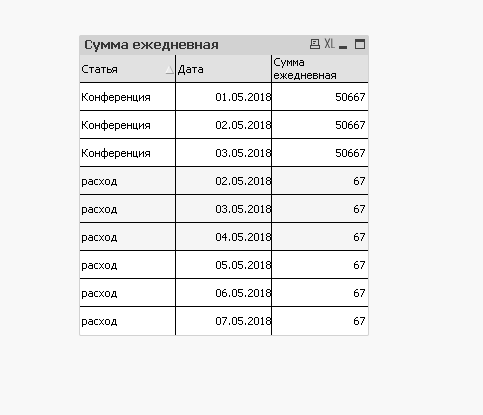
Результат:
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Привет, очень похожая тема здесь
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
А наоборот как сделать? с сокращением строк Group by понятно, а как увеличить количество строк, из одной сделать несколько? я крутил с циклами, но что-то не получается с переменными. Они выставляются только для первой строки. Как придумать переменные для каждой строки отдельно не знаю.
Вот код:
Customer:
LOAD
[Период 1] as P1,
[Период 2] as P2
FROM
(ooxml, embedded labels, table is исходные);
LET variable1=PEEK('P1',0,'Customer');
LET variable2=PEEK('P2',0,'Customer');
for a=$(variable1) to $(variable2)
TempGeoCode:
LOAD
$(a) as [Период],
Статья,
[Дата оплаты],
[Дата начала включения в расчет],
[Дата окончания включения в отчет],
[Сумма статьи],
[Период 1],
[Период 2],
[Кол-во периодов],
[Сумма ежедневная]
FROM
(ooxml, embedded labels, table is исходные);
NEXT
[map1]:
mapping LOAD
Период,
Дата
FROM
(ooxml, embedded labels, table is периоды);
TempGeoCode2:
LOAD
applymap ('map1',[Период]) as [Дата],
[Период],
Статья,
[Дата оплаты],
[Дата начала включения в расчет],
[Дата окончания включения в отчет],
[Сумма статьи],
[Период 1],
[Период 2],
[Кол-во периодов],
[Сумма ежедневная]
Resident TempGeoCode;
drop table TempGeoCode;
Файлы также прикладываю. !
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
А если просто ряд запросов с Concatenate.?
В каждом запросе переименовываем поля дат в Дата и делаем отдельные запросы на начальную, конечную даты.
В итоге все объединится в одну таблицу.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Для этого существует функция IntervalMatch()
Создайте таблицу со всеми датами от минимальной до максимальной. И при помощи функции IntervalMatch() присоедините их к таблице транзакций.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Спасибо! Проблема решена!
Код:
[Интервалы]:
LOAD
[Дата начала включения в расчет],
[Дата окончания включения в отчет],
Статья,
[Сумма ежедневная]
FROM
(ooxml, embedded labels, table is исходные);
INNER JOIN
LOAD DISTINCT [Дата начала включения в расчет],
[Дата окончания включения в отчет],
AutoNumberHash128([Дата начала включения в расчет],[Дата окончания включения в отчет]) as [Интервал времени]
Resident [Интервалы];
[Даты]:
LOAD
Дата
FROM
(ooxml, embedded labels, table is периоды);
[Таблица соединения]:
Intervalmatch ([Дата]) LOAD [Дата начала включения в расчет] as [Начало интервала],[Дата окончания включения в отчет] as [Окончание интервала] Resident [Интервалы];
INNER JOIN
LOAD DISTINCT [Начало интервала],
[Окончание интервала],
AutoNumberHash128([Начало интервала],[Окончание интервала]) as [Интервал времени]
Resident [Таблица соединения];
Результат:
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Коллеги, всем добрый день!
IntervalMatch также очень хорошо подходит для решения задачи по вычислению численности сотрудников компании в раскладке на каждый день, +можно посмотреть приращение, если имеется. Это работает в случае, когда у каждого сотрудника указаны даты приема и увольнения.