Unlock a world of possibilities! Login now and discover the exclusive benefits awaiting you.
- Qlik Community
- :
- All Forums
- :
- QlikView
- :
- How to do this in the script
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
How to do this in the script
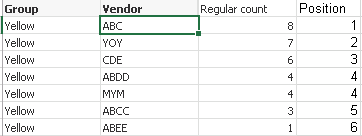
I have a basic row count function in a pivot table. when I use rank function it creates a tie for equals. is it possible to give position as show in the image below and can it be done at script level?
so when there is a tie I want the position not skip 4. so there will be 2 4's. in other words disregard the usual interpretation of "Rank"
also pls see qvw attached
- « Previous Replies
-
- 1
- 2
- Next Replies »
Accepted Solutions
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Trying to come up with a logic to explain to you made me realize when would Div by 5 break. Lets walk through the whole scenario and then I will explain when we would want to change from 5 to something else. (Massimo please free to correct me if I my understanding isn't right)
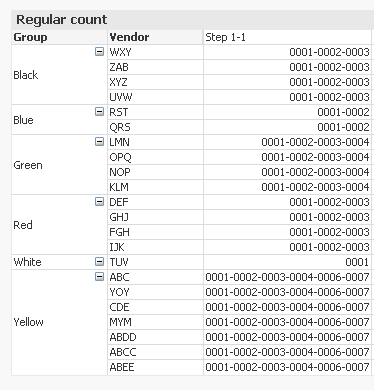
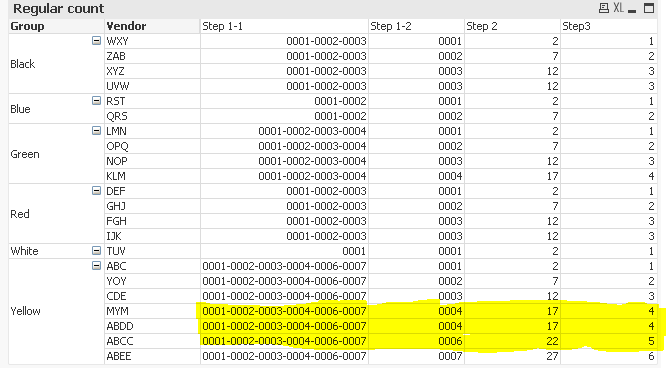
Step 1-1)
Concat(DISTINCT TOTAL <Group> Num(Aggr(Rank(Count({<FieldA = {'1'}>} ID),1,1),Group, Vendor), '0000'), '-', -Aggr(Count({<FieldA = {'1'}>} ID), Group, Vendor))
Concate a distinct (USING DISTINCT) list of possible ranks by each group (TOTAL <Group>) which is sorted in ascending order using the expression -Aggr(Count({<FieldA = {'1'}>} ID), Group, Vendor) and separated by '-'.
Assign the possible list of rank a particular formatting here where they should all be 4 digit. I think the assumption here is that the max rank would ever be 9999, if this is not true, then you can change from '0000' to '00000'. This will not cover upto 99999 (this is where the division will come into play, which I will go into later)
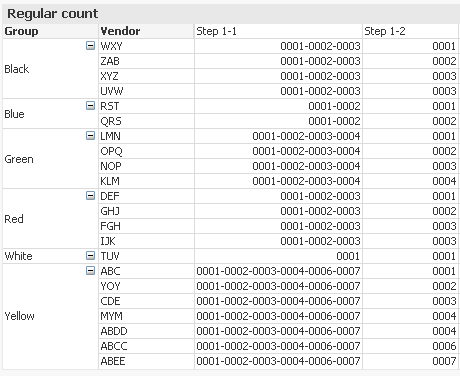
Step 1-2)
Num(Rank(Count({ < FieldA = {'1'}>} ID),1,1),'0000')
Find the rank for each row and assign it the same number formatting as the formatting assigned with the Concat function. '0000' or '00000'.
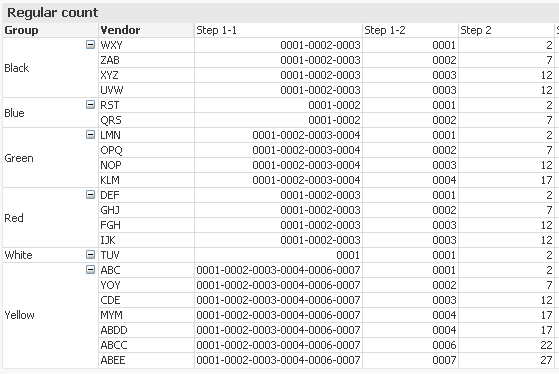
Step 2)
Index('-' & Concat(DISTINCT TOTAL <Group> Num(Aggr(Rank(Count({<FieldA = {'1'}>} ID),1,1),Group, Vendor), '0000'), '-', -Aggr(Count({<FieldA = {'1'}>} ID), Group, Vendor)),
Num(Rank(Count({ < FieldA = {'1'}>} ID),1,1),'0000'))
Find the location of '-' within the concatenated list of rank, but this index function has a third parameter telling it to look for which '-' in the list. The third parameter is basically the rank from Step 1-2 which goes like 1, 2, 3. So basically what is the location of first 1st '-', 2nd '-' and so on....
Step 3)
Div(Index('-' & Concat(DISTINCT TOTAL <Group> Num(Aggr(Rank(Count({<FieldA = {'1'}>} ID),1,1),Group, Vendor), '0000'), '-', -Aggr(Count({<FieldA = {'1'}>} ID), Group, Vendor)),
Num(Rank(Count({<FieldA = {'1'}>} ID),1,1), '0000')), 5) + 1
I don't think we have to use Div function here, I believe that if the list of rank is small you can also use Pick match, but for a larger rank, div will work better here.
The idea is that since we have used '0000' as number formatting the location of '-' will change by 5 each time (2, 7, 12, 17, 22, 27, 32, ......) so dividing this by 5 will give us (0, 1, 2, 3, 4, 5, 6) and adding one to this will give us (1, 2, 3, 4, 5). Now for the cases we have repeating rank we will get the same position of '-' and for the next highest rank, even the concatenated list of ranks wouldn't have the next set of rank making this expression possible to get the number incrementally (look at the three highlighted rows below).
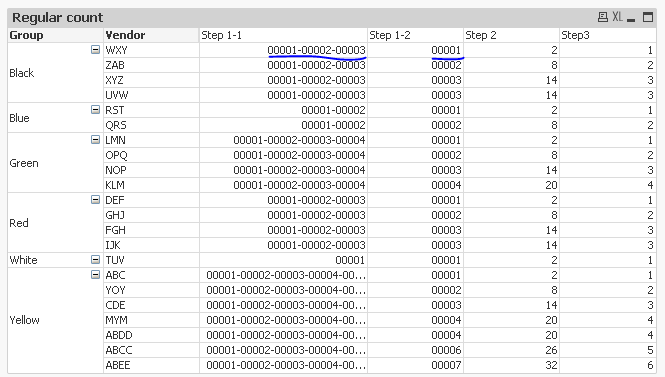
Now if for some reason we think that rank can run above 10,000, but less than 99,999, we might want to change the expression to this:
Div(Index('-' & Concat(DISTINCT TOTAL <Group> Num(Aggr(Rank(Count({<FieldA = {'1'}>} ID),1,1),Group, Vendor), '00000'), '-', -Aggr(Count({<FieldA = {'1'}>} ID), Group, Vendor)),
Num(Rank(Count({<FieldA = {'1'}>} ID),1,1), '00000')), 6) + 1
Apologize for the long post, but I hope this will clarify any doubts that we had and as mentioned above, if Massimo finds anything wrong with the logic here would be able to correct us as well.
Best,
Sunny
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Please take a look at the below link:
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thanks for sharing the post trdandamudi. I wonder if there are still limitations here (For instance what is the reason for dividing by 5), but was able to configure maxgro's expression for it to work here:
Div(Index('-' & Concat(DISTINCT TOTAL <Group> Num(Aggr(Rank(Count({<FieldA = {'1'}>} ID),1,1),Group, Vendor), '0000'), '-', -Aggr(Count({<FieldA = {'1'}>} ID), Group, Vendor)), Num(Rank(Count({ < FieldA = {'1'}>} ID),1,1),'0000')), 5) + 1
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Here is a script based solution:
Table:
LOAD * INLINE [
Group, Vendor, ID, Trans_ID, FieldA
Black, UVW, A65, A165, 1
Black, WXY, A66, A166, 1
Black, WXY, A67, A167, 1
Black, WXY, A68, A168, 0
...
];
TEMP:
LOAD Group,
Vendor,
Count(Vendor) as Count
Resident Table
Where FieldA = 1
Group By Group, Vendor;
Left Join (Table)
LOAD Group,
Vendor,
AutoNumber(Count, Group) as Rank
Resident TEMP
Order By Group, Count desc;
DROP Table TEMP;
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Sunny,
When you get a chance can you please let me know what exactly this expression is doing. It is little confusing with the division .
Thanks
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Trying to come up with a logic to explain to you made me realize when would Div by 5 break. Lets walk through the whole scenario and then I will explain when we would want to change from 5 to something else. (Massimo please free to correct me if I my understanding isn't right)
Step 1-1)
Concat(DISTINCT TOTAL <Group> Num(Aggr(Rank(Count({<FieldA = {'1'}>} ID),1,1),Group, Vendor), '0000'), '-', -Aggr(Count({<FieldA = {'1'}>} ID), Group, Vendor))
Concate a distinct (USING DISTINCT) list of possible ranks by each group (TOTAL <Group>) which is sorted in ascending order using the expression -Aggr(Count({<FieldA = {'1'}>} ID), Group, Vendor) and separated by '-'.
Assign the possible list of rank a particular formatting here where they should all be 4 digit. I think the assumption here is that the max rank would ever be 9999, if this is not true, then you can change from '0000' to '00000'. This will not cover upto 99999 (this is where the division will come into play, which I will go into later)
Step 1-2)
Num(Rank(Count({ < FieldA = {'1'}>} ID),1,1),'0000')
Find the rank for each row and assign it the same number formatting as the formatting assigned with the Concat function. '0000' or '00000'.
Step 2)
Index('-' & Concat(DISTINCT TOTAL <Group> Num(Aggr(Rank(Count({<FieldA = {'1'}>} ID),1,1),Group, Vendor), '0000'), '-', -Aggr(Count({<FieldA = {'1'}>} ID), Group, Vendor)),
Num(Rank(Count({ < FieldA = {'1'}>} ID),1,1),'0000'))
Find the location of '-' within the concatenated list of rank, but this index function has a third parameter telling it to look for which '-' in the list. The third parameter is basically the rank from Step 1-2 which goes like 1, 2, 3. So basically what is the location of first 1st '-', 2nd '-' and so on....
Step 3)
Div(Index('-' & Concat(DISTINCT TOTAL <Group> Num(Aggr(Rank(Count({<FieldA = {'1'}>} ID),1,1),Group, Vendor), '0000'), '-', -Aggr(Count({<FieldA = {'1'}>} ID), Group, Vendor)),
Num(Rank(Count({<FieldA = {'1'}>} ID),1,1), '0000')), 5) + 1
I don't think we have to use Div function here, I believe that if the list of rank is small you can also use Pick match, but for a larger rank, div will work better here.
The idea is that since we have used '0000' as number formatting the location of '-' will change by 5 each time (2, 7, 12, 17, 22, 27, 32, ......) so dividing this by 5 will give us (0, 1, 2, 3, 4, 5, 6) and adding one to this will give us (1, 2, 3, 4, 5). Now for the cases we have repeating rank we will get the same position of '-' and for the next highest rank, even the concatenated list of ranks wouldn't have the next set of rank making this expression possible to get the number incrementally (look at the three highlighted rows below).
Now if for some reason we think that rank can run above 10,000, but less than 99,999, we might want to change the expression to this:
Div(Index('-' & Concat(DISTINCT TOTAL <Group> Num(Aggr(Rank(Count({<FieldA = {'1'}>} ID),1,1),Group, Vendor), '00000'), '-', -Aggr(Count({<FieldA = {'1'}>} ID), Group, Vendor)),
Num(Rank(Count({<FieldA = {'1'}>} ID),1,1), '00000')), 6) + 1
Apologize for the long post, but I hope this will clarify any doubts that we had and as mentioned above, if Massimo finds anything wrong with the logic here would be able to correct us as well.
Best,
Sunny
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thank you very much for the detailed post and really appreciate for your valuable time.
Thanks
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi John,
Group:
LOAD
Group,
Vendor,
Count(Trans_ID) as [Regular Count]
Resident INLFED Group by Group, Vendor;
DROP Table INLFED;
Left Join (Group)
Load
Group,
Vendor,
AutoNumber([Regular Count],Group) as Position
Resident Group Order by Group, [Regular Count] desc;
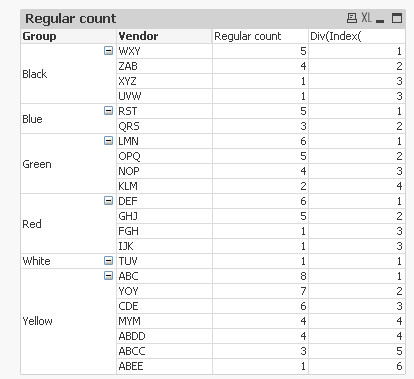
This gives for the Yellow group:
| Group | Vendor | Regular Count | Position |
|---|---|---|---|
| Yellow | ABC | 12 | 1 |
| Yellow | YOY | 7 | 2 |
| Yellow | CDE | 6 | 3 |
| Yellow | ABDD | 4 | 4 |
| Yellow | MYM | 4 | 4 |
| Yellow | ABCC | 3 | 5 |
| Yellow | ABEE | 1 | 6 |
Kind regards
Andrew
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
No problem trdandamudi. I think I need to thank you for bringing this technique to my notice. I would have not learned a new thing if it is not for you today. So thank you my friend.
Best,
Sunny
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
This one is very simple in nature but I am unable to pull the top 5. below: all 3 fields are from a table with out any aggregation.
how to show top 5: ABC, MYE, MYM, ABCC, ABCD, ABCE, YOU, YOY, CDE & CDF. as an expression on the front end not on the back end. QVW attached as well. Thanks again.
![]()
- « Previous Replies
-
- 1
- 2
- Next Replies »