Unlock a world of possibilities! Login now and discover the exclusive benefits awaiting you.
- Qlik Community
- :
- Forums
- :
- Analytics
- :
- New to Qlik Analytics
- :
- Re: How to remove row if two fields are the same
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
How to remove row if two fields are the same
I am dealing with a table with running records where one person should only appear once on a day. There are records where one person appear twice on a day. I need to remove these "duplicates" from the table before I can do any analysis. The other fields of the records might not be the same. I plan to keep only the records that have the latest Transaction ID. Eg. if a person has two records on the same day, one Transaction ID is 9011 the other is 9064, I want to keep 9064.
How can I do it? Can I do it in the LOAD step or in expressions?
Thanks in advance!
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Great Jade.  Did you manage to get the correct results now?
Did you manage to get the correct results now?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
just use this,
will work:)
Transactions:
Load
max(TransID) as TransactionId,
Floor(Date) as FloorDate,
[Person ID]
FROM [lib://test/test data.xlsx]
(ooxml, embedded labels, table is Sheet1)
Group by
[Person ID],
Floor(Date)
;
Left Join (Transactions)
Load
TransID as TransactionId ,
Floor(Date) as FloorDate,
*
FROM [lib://test/test data.xlsx]
(ooxml, embedded labels, table is Sheet1);
Drop fields TransactionId , FloorDate;
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
remember that if Date field is timestamp using Date(Date,'DD/MM/YYYY') as Date, wil not work, you have to use Floor(Date) as Date
cheers guys
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Lech,
I agree with your point. I assumed Jade's file has only the date field i.e DD/MM/YYYY (No timestamp) and provided the solution. So this is purely based on my assumption. Thanks for pointing out though. Have a good day.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
No worries.
Hopefuly it works for Jade finaly.
Cheers guys-i am starting weekend here Down Under
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Ohhh ok Lech . Have a nice evening and a happy weekend.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
| TransID | Date | PersonID |
| 9616 | 29/11/2016 | 41500 |
| 9601 | 29/11/2016 | 41500 |
| 7150 | 01/03/2016 | 41500 |
| 9570 | 08/11/2016 | 44626 |
| 8174 | 08/06/2016 | 44626 |
| 6744 | 06/11/2015 | 44626 |
| 3920 | 31/03/2015 | 44626 |
| 1971 | 18/11/2014 | 44626 |
| 8466 | 14/07/2016 | 2004647 |
| 8213 | 20/06/2016 | 2004647 |
| 7705 | 02/05/2016 | 2004647 |
| 6186 | 07/10/2015 | 2004647 |
| 5616 | 24/08/2015 | 2004647 |
| 8454 | 27/07/2016 | 2005542 |
| 8247 | 21/06/2016 | 2005542 |
| 8005 | 17/05/2016 | 2005542 |
| 6249 | 20/10/2015 | 2005542 |
| 1403 | 30/10/2014 | 2005542 |
Below is a script code, which excludes TransID lower in the first two rows
LOAD Date,
PersonID,
Max(TransID)
FROM
(the path to your table)
Group By Date, PersonID;
Regards
Andrey Kh
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
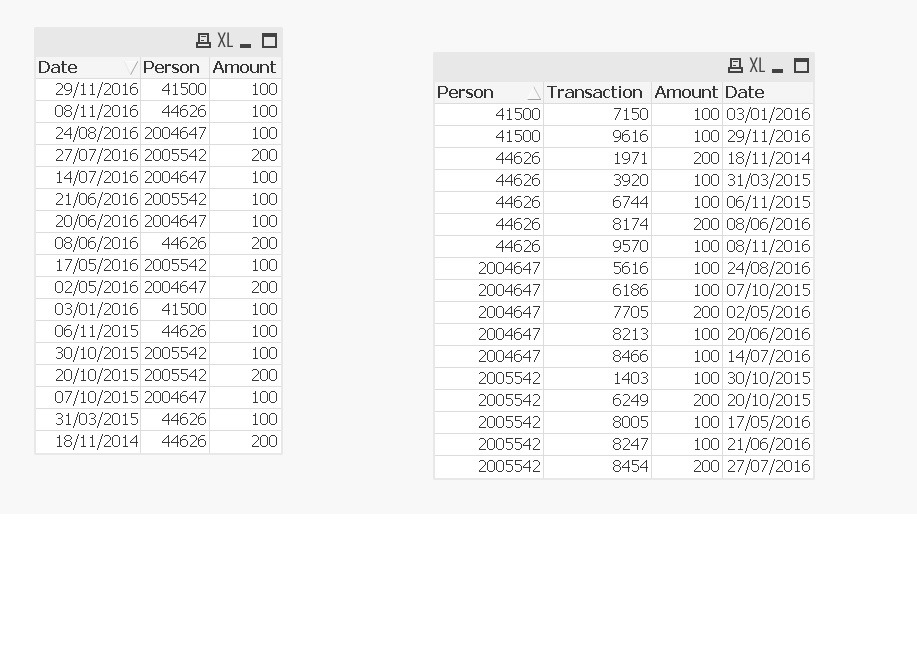
Hi Jade,
You can refer below script. You will get Amount against latest Transid. Above screenshot is from Qlikview and In above screenshot we can see single amount against TransId and not the average of Amount based on Person.
Data:
LOAD Max(Transid) as Transaction,
Date,
Person
FROM
Duplicate_rows_removal.xlsx
(ooxml, embedded labels, table is Sheet1)
group by Person,Date;
Data2:
Left Join(Data)
LOAD Transid as Transaction,
Date,
Amount
FROM
Duplicate_rows_removal.xlsx
(ooxml, embedded labels, table is Sheet1);
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
HI,
if you want to keep all your original data and filter them on expressions, you need to add a flag.
Transactions:
Load *
FROM [lib://test/test data.xlsx]
(ooxml, embedded labels, table is Sheet1);
Left Join (Transactions)
Load
max(TransID) as TransID,
Date(Date,'DD/MM/YYYY') as Date,
[Person ID],
1 as _LDT
Resident Transactions
Group by
[Person ID],
Date
;
I use _LDT for Last Daily Transaction and you need to use it in your expressions with set analysis.
Like that for example:
Sum({$<_LDT={1}>} Amount)
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Yes - good point. that would give you full picture how your data is working.
Lets hear from Jade whether he has finaly got it working.
regards
Lech
-------------------------------------------------------------------------------------------------------
Please mark CORRECT answer to help others an close already solved topics