Unlock a world of possibilities! Login now and discover the exclusive benefits awaiting you.
- Qlik Community
- :
- Forums
- :
- Analytics
- :
- App Development
- :
- Re: Sum of values that follow some rules
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Sum of values that follow some rules
Hello,
I have a problem here and I am wondering how to make this works on Qlik Sense.
So, I have this table here to use as example.
| Col1 | Product | Col3 | Col4 |
| x | a | 2 | 0 |
| x | b | 3 | # |
| y | a | 7 | # |
| y | c | 8 | # |
What I need from this data is the sum of Col3 where Product has Col1 = 'X' AND 'Y' (Both).
Also this sum of Col3 have to consider just rows where Col4 = '#'.
So the result on this example will be '7'. Since only Product 'A' has the requirements and the 1st row is not Col4 = '#'.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Sum({<Col2 = P({$<Col1={'x'}>}Col2) * P({$<Col1={'y'}>}Col2), Col4-={0}>}Col3)
Even that this formula gives me the expected value, I was wondering if is really correct.
I am new using indirect set analysis and not sure if this case is ok to use that.
If someone has another alternative or some adjustment to the formula that I used, will be very welcome.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
May be this
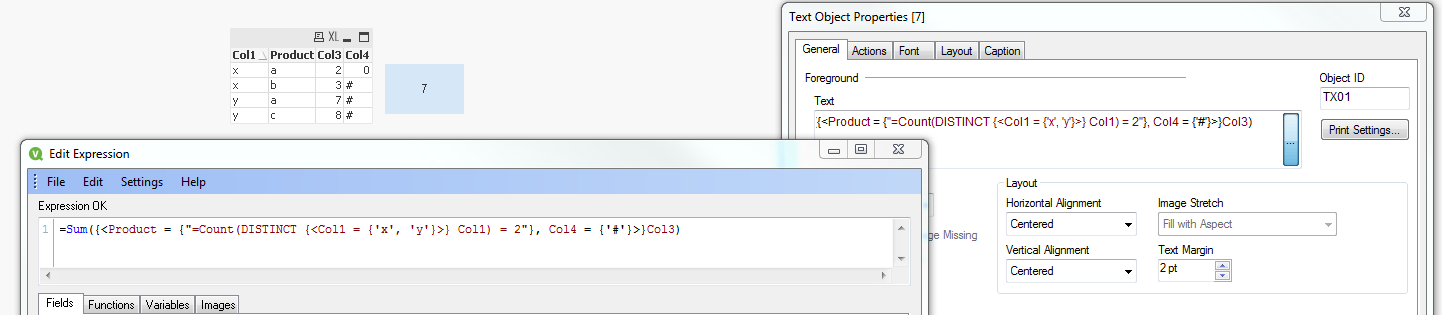
Sum({<Product = {"=Count(DISTINCT {<Col1 = {'x', 'y'}>} Col1) = 2"}, Col4 = {'#'}>}Col3)
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Sample qvw and image attached
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
This works for me:
sum(if(aggr(nodistinct concat(Col1),Product)='xy' and Col4='#', Col3))