Unlock a world of possibilities! Login now and discover the exclusive benefits awaiting you.
- Qlik Community
- :
- Forums
- :
- Groups
- :
- Location and Language
- :
- Brasil
- :
- Re: ASSOCIACAO X JOIN
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Feature this Topic
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
ASSOCIACAO X JOIN
Senhores bom dia, gostaria de um auxilio, na verdade é mais uma duvida, como melhor pratica em se tratando de performance da aplicacao, qual a melhor forma de trabalhar com tabelas , é realizando uma associacao entre tabelas ou realizando um join? Obrigado a todos.
- Tags:
- Group_Discussions
Accepted Solutions
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Paulo, tudo depende.
Um modelo Star, Snow Flake ou Big Facto somente terá performance melhor ou pior entre eles dependendo da quantidade de registros entre as tabelas.
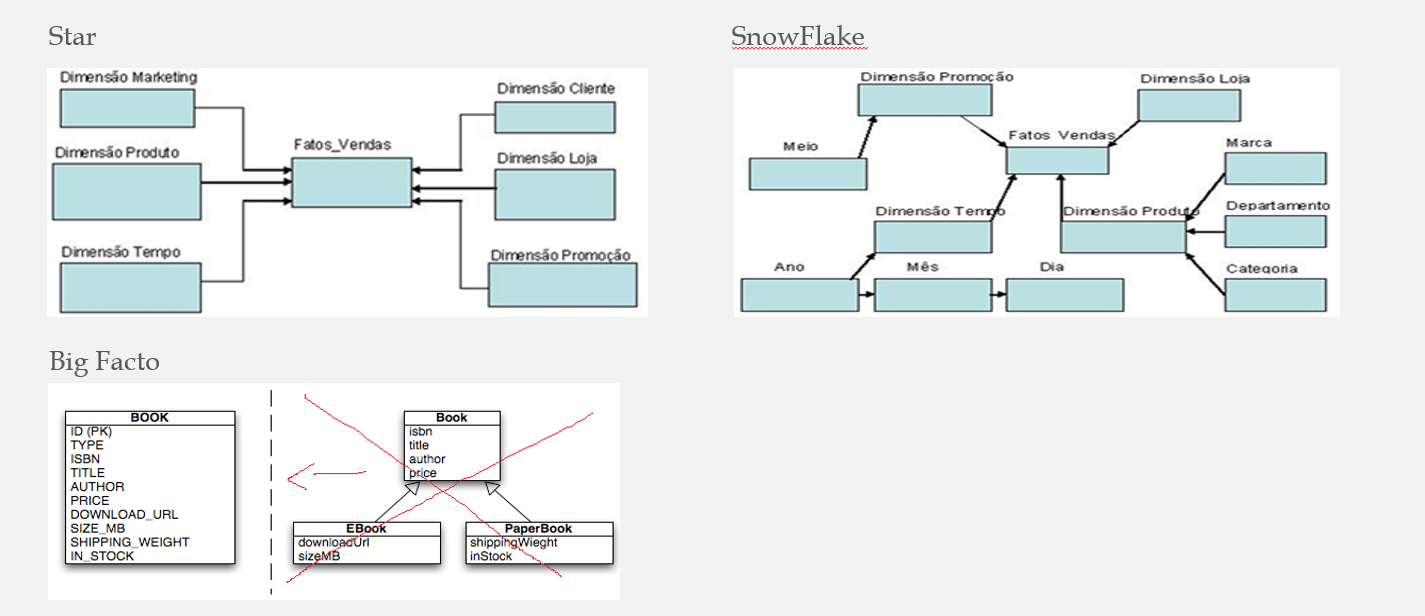
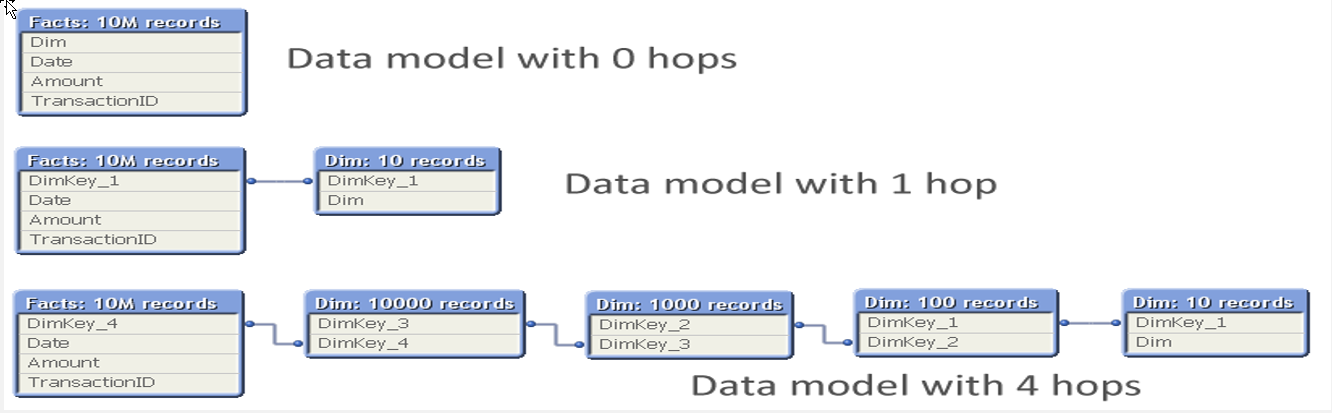
Então, se tiver um modelo SnowFlake com poucos registros nas pontas (4 hops no exemplo acima com poucos registros nas pontas) a performance não vai ser diferente do bigfacto, conforme A Myth about the Number of Hops
Se tiver grandes quantidades nas pontas, então melhor juntar.
Agora, tem questões a serem consideradas, por exemplo se tiver calculo de campos entre as tabelas.
Se na expressão tiver campos de tabelas diferentes – exemplo sum(Pedido_Qtde * TabelaPreco_ValorUnitario) “poderá” criar piora na performance (terá que criar o lookup das tabelas..(join) em tempo de calculo). Neste caso seria melhor ter (se possível) os dados já na mesma "linha" ou mesmo já calculado.
A performance não esta somente na modelagem. Está em como o campo é lido e gravado ( Symbol Tables and Bit-Stuffed Pointers ) , se tenho expressões com if (poderia usar set analisys ) , uso aggr ( que cria uma tabela virtual para calcular. E aqui também não estou dizendo que não pode usar, mas cuidar......), condicoes de calculo ajudam na performance tambem, pois evita o calculo desnecessario quando o usuario limpa todas as selecoes por exemplo.
enfim, bastante coisa....como salvar com compressão ou não (se a carga é feita em tempos curtos....), variáveis ( certo nicolett.yuri  ) etc....
) etc....
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Paulo, tudo depende.
Um modelo Star, Snow Flake ou Big Facto somente terá performance melhor ou pior entre eles dependendo da quantidade de registros entre as tabelas.
Então, se tiver um modelo SnowFlake com poucos registros nas pontas (4 hops no exemplo acima com poucos registros nas pontas) a performance não vai ser diferente do bigfacto, conforme A Myth about the Number of Hops
Se tiver grandes quantidades nas pontas, então melhor juntar.
Agora, tem questões a serem consideradas, por exemplo se tiver calculo de campos entre as tabelas.
Se na expressão tiver campos de tabelas diferentes – exemplo sum(Pedido_Qtde * TabelaPreco_ValorUnitario) “poderá” criar piora na performance (terá que criar o lookup das tabelas..(join) em tempo de calculo). Neste caso seria melhor ter (se possível) os dados já na mesma "linha" ou mesmo já calculado.
A performance não esta somente na modelagem. Está em como o campo é lido e gravado ( Symbol Tables and Bit-Stuffed Pointers ) , se tenho expressões com if (poderia usar set analisys ) , uso aggr ( que cria uma tabela virtual para calcular. E aqui também não estou dizendo que não pode usar, mas cuidar......), condicoes de calculo ajudam na performance tambem, pois evita o calculo desnecessario quando o usuario limpa todas as selecoes por exemplo.
enfim, bastante coisa....como salvar com compressão ou não (se a carga é feita em tempos curtos....), variáveis ( certo nicolett.yuri ) etc....
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Obrigado pelo retorno Alessandro, alucidou muita coisa que estava tentando desvendar