Unlock a world of possibilities! Login now and discover the exclusive benefits awaiting you.
- Qlik Community
- :
- Forums
- :
- Analytics
- :
- App Development
- :
- Re: Share Filters Across Multiple Datasets
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Share Filters Across Multiple Datasets
I have two datasets that are similar, but different.
One is basically a snapshot A of current data with a lot of dimensions.
Then there is a second dataset B which is bascially a historic view of A, but has a reduced set of dimensions and an additional date column.
Example for A (current sales):
| COMPANY | COUNTRY | DIVISION | GROUP | PRODUCT | SALES |
|---|---|---|---|---|---|
| 548 | US | 25 | 3 | 92854872 | 3200 |
| 849 | CA | 10 | 2 | 39745927 | 10000 |
| 948 | CA | 12 | 2 | 49285921 | 5000 |
Example B (historical sales per country and group):
| DATE | COUNTRY | GROUP | SALES |
|---|---|---|---|
| 01/09/2017 | US | 3 | 2000 |
| 01/09/2017 | CA | 2 | 12000 |
| 01/10/2017 | US | 3 | 3200 |
| 01/10/2017 | CA | 2 | 15000 |
I would like to show the current and the historical datasets separately on two sheets.
Each sheet should have some common filters: COUNTRY and GROUP
How can I make it then when someone filters one of the page with one of the filters, that the same filter gets applied to the other dataset as well?
As a side remark: in my scenario that common filters would not only be COUNTRY and GROUP, but a total of 10 shared dimensions.
Thank you!
Regards,
Herbert
Herbert: named datasets correctly
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
If it shared data set then you can use Copy List Box object from Sheet 1 and paste it on second one as Linked Object as can be seen from screen shot below
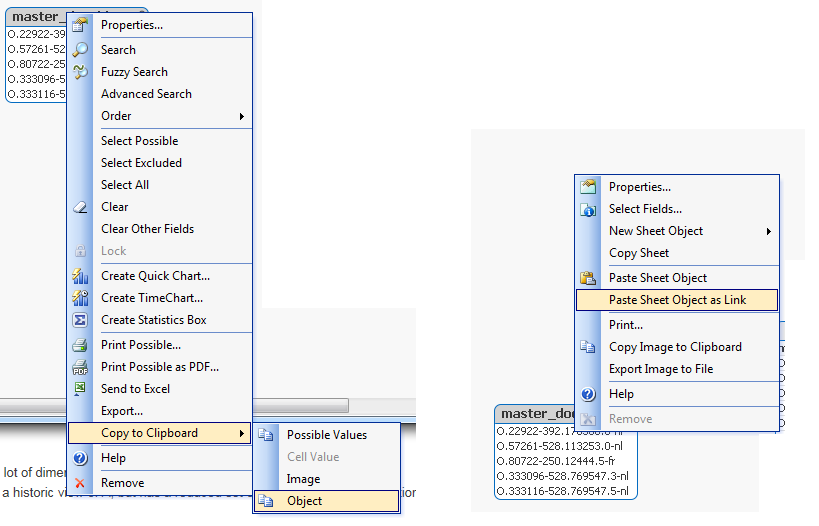
you will be able to do it for all dimension that are common across sheets
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Selections (filters) are by default global. That is, a selection made in the field COUNTRY will filter any sheet or object that uses data from that field. You don't have to do anything special to get this behavior.
In your case, you will probably want to concatenate the two tables to avoid having a synthetic key. For example, the script would look like:
Data:
LOAD *
FROM Current...;
Concatenate (Data)
LOAD *
History...;
-Rob
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
That does not look like my Qlik Sense?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Rob,
thank you for your reply.
Maybe I am too SQL-minded, but I don't think I can (or should try to) concatenate two datasets that only share a set of dimensions, but differ many other columns and also column count.
I should also say that at the moment I am using purposedly similar, but different column names, something like:
CURR_COUNTRY (dataset A)
HISTORY_COUNTRY (dataset B)
Here is how my load file roughly looks like (again: leaving out several other imension columns for table A):
LOAD
"CURR_COMPANY",
"CURR_COUNTRY",
"CURR_DIVISION",
"CURR_GROUP",
"CURR_PRODUCT",
"CURR_SALES";
SQL
SELECT
COMPANY AS CURR_COMPANY,
COUNTRY AS CURR_COUNTRY,
DIVISION AS CURR_DIVISION,
GROUP AS CURR_GROUP,
PRODUCT AS CURR_PRODUCT,
SALES AS CURR_SALES
FROM A;
LOAD
"HISTORY_DATE",
"HISTORY_COUNTRY",
"HISTORY_GROUP",
"HISTORY_SALES_SUM";
SQL
SELECT
DATE AS HISTORY_DATE,
COUNTRY AS HISTORY_COUNTRY,
GROUP AS HISTORY_GROUP,
SALES AS HISTORY_SALES_SUM
FROM B;
Can you help me understand this if I can/should concatenate that logical different tables?
Thanks!
Regards,
Herbert
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Yes, you are being too SQL minded. 
Renaming columns will make the app more difficult to write and will not leverage Qliks associative logic -- which is the secret sauce.
It may seem unnatural to concatenate tables with unlike columns, but trust me, this is the way we do it in Qlik. Renaming columns will things much more difficult. A Company is a Company, whether it's history or current.
-Rob