Unlock a world of possibilities! Login now and discover the exclusive benefits awaiting you.
- Qlik Community
- :
- Forums
- :
- Groups
- :
- Location and Language
- :
- Россия и СНГ
- :
- Re: Как разграничить доступ пользователя к данным?
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Feature this Topic
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Как разграничить доступ пользователя к данным?
Привет, коллеги!
Можно ли в QV разграничить доступ пользователей к данным подобным образом:
Например: есть данные о продажах товаров с показателями выручка и себестоимость.
Задача состоит в том что бы для определенных товаров пользователь мог видеть все показатели (выручка, себестоимость), а по всем остальным товарам ему была бы доступна только выручка.
у каждого пользователя свой набор товаров, для которых доступны все показатели.
Есть какие-либо решения или идеи?
Спасибо.
- Tags:
- Group_Discussions
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Эффективное решение сильно зависит от используемой модели данных и возможности вносить в нее изменнеия.
Например, если у вас в таблице фактов числовые значения выручки и себестоимости хранятся в одном столбце, а тип показателя (выручка/себестоимость) - в другом столбце. В этом случае возможно использовать сложный ключ товар+показатель для section access, и раздать права на данные имено так, как вы хотите.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Сергей, продемонстрируйте пожалуйста предложенное вами решение на примере. Я не понимаю как не связанная ни с чем таблица с себестоимостью должна работать. Реагировать на все сделанные селекты, отображаться в диаграмме, а как например посчитать маржу (выручка-с/с)?
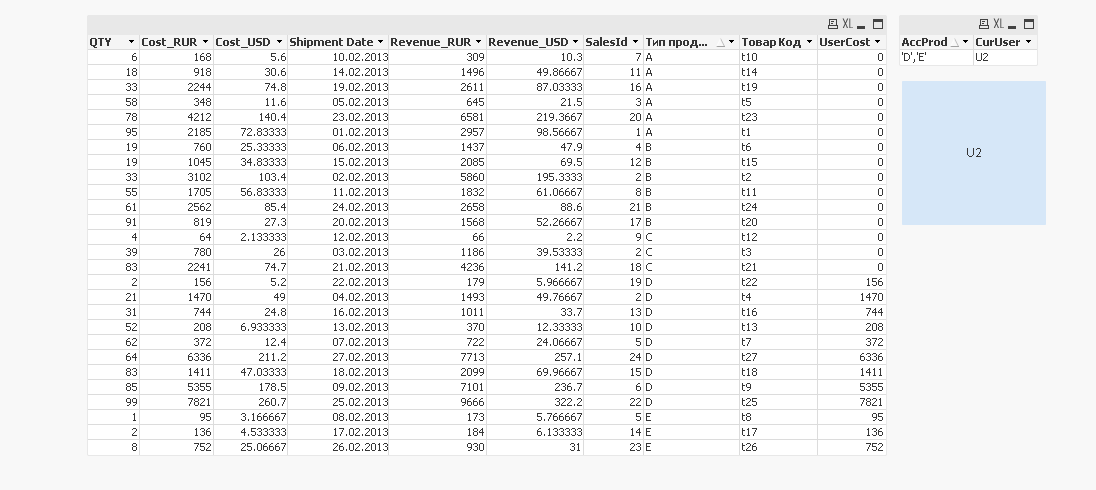
Например, есть такие данные (искусственные, но соответствующие нашей структуре данных). И например пользователю U1 нужно ввести ограничения на просмотр с/с по всем типам продукта кроме A. (Файл с данными также прикрепил)
| QTY | Сost_RUR | Сost_USD | Shipment Date | Revenue_RUR | Revenue_USD | SalesId | Тип продукта | Товар Код |
| 95 | 2185 | 72.83333 | 01.02.2013 | 2957 | 98.56667 | 1 | A | t1 |
| 33 | 3102 | 103.4 | 02.02.2013 | 5860 | 195.3333 | 2 | B | t2 |
| 39 | 780 | 26 | 03.02.2013 | 1186 | 39.53333 | 2 | C | t3 |
| 21 | 1470 | 49 | 04.02.2013 | 1493 | 49.76667 | 2 | D | t4 |
| 58 | 348 | 11.6 | 05.02.2013 | 645 | 21.5 | 3 | A | t5 |
| 19 | 760 | 25.33333 | 06.02.2013 | 1437 | 47.9 | 4 | B | t6 |
| 62 | 372 | 12.4 | 07.02.2013 | 722 | 24.06667 | 5 | D | t7 |
| 1 | 95 | 3.166667 | 08.02.2013 | 173 | 5.766667 | 5 | E | t8 |
| 85 | 5355 | 178.5 | 09.02.2013 | 7101 | 236.7 | 6 | D | t9 |
| 6 | 168 | 5.6 | 10.02.2013 | 309 | 10.3 | 7 | A | t10 |
| 55 | 1705 | 56.83333 | 11.02.2013 | 1832 | 61.06667 | 8 | B | t11 |
| 4 | 64 | 2.133333 | 12.02.2013 | 66 | 2.2 | 9 | C | t12 |
| 52 | 208 | 6.933333 | 13.02.2013 | 370 | 12.33333 | 10 | D | t13 |
| 18 | 918 | 30.6 | 14.02.2013 | 1496 | 49.86667 | 11 | A | t14 |
| 19 | 1045 | 34.83333 | 15.02.2013 | 2085 | 69.5 | 12 | B | t15 |
| 31 | 744 | 24.8 | 16.02.2013 | 1011 | 33.7 | 13 | D | t16 |
| 2 | 136 | 4.533333 | 17.02.2013 | 184 | 6.133333 | 14 | E | t17 |
| 83 | 1411 | 47.03333 | 18.02.2013 | 2099 | 69.96667 | 15 | D | t18 |
| 33 | 2244 | 74.8 | 19.02.2013 | 2611 | 87.03333 | 16 | A | t19 |
| 91 | 819 | 27.3 | 20.02.2013 | 1568 | 52.26667 | 17 | B | t20 |
| 83 | 2241 | 74.7 | 21.02.2013 | 4236 | 141.2 | 18 | C | t21 |
| 2 | 156 | 5.2 | 22.02.2013 | 179 | 5.966667 | 19 | D | t22 |
| 78 | 4212 | 140.4 | 23.02.2013 | 6581 | 219.3667 | 20 | A | t23 |
| 61 | 2562 | 85.4 | 24.02.2013 | 2658 | 88.6 | 21 | B | t24 |
| 99 | 7821 | 260.7 | 25.02.2013 | 9666 | 322.2 | 22 | D | t25 |
| 8 | 752 | 25.06667 | 26.02.2013 | 930 | 31 | 23 | E | t26 |
| 64 | 6336 | 211.2 | 27.02.2013 | 7713 | 257.1 | 24 | D | t27 |
заранее благодарен за ответ.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Добрый день.
ну вот например, такая идея:
Section Access;
LOAD * INLINE [
ACCESS, USERID
ADMIN, A1
USER, U1
USER, U2
];
Section Application;
let vCUser = QVUser();
List_ACL:
LOAD * INLINE [
CurUser, AccProd
A1, "'*'"
U1, "'B','C','D','E'"
U2, "'D','E'"
]
Where match(CurUser,'$(vCUser)');
let vUserAcc=peek('AccProd',0,'List_ACL');
LOAD *,
if(wildmatch([Тип продукта],$(vUserAcc)),Сost_RUR,0) as UserCost
INLINE [
QTY, Сost_RUR, Сost_USD, Shipment Date, Revenue_RUR, Revenue_USD, SalesId, Тип продукта, Товар Код
95, 2185, 72.83333, 01.02.2013, 2957, 98.56667, 1, A, t1
33, 3102, 103.4, 02.02.2013, 5860, 195.3333, 2, B, t2
39, 780, 26, 03.02.2013, 1186, 39.53333, 2, C, t3
21, 1470, 49, 04.02.2013, 1493, 49.76667, 2, D, t4
58, 348, 11.6, 05.02.2013, 645, 21.5, 3, A, t5
19, 760, 25.33333, 06.02.2013, 1437, 47.9, 4, B, t6
62, 372, 12.4, 07.02.2013, 722, 24.06667, 5, D, t7
1, 95, 3.166667, 08.02.2013, 173, 5.766667, 5, E, t8
85, 5355, 178.5, 09.02.2013, 7101, 236.7, 6, D, t9
6, 168, 5.6, 10.02.2013, 309, 10.3, 7, A, t10
55, 1705, 56.83333, 11.02.2013, 1832, 61.06667, 8, B, t11
4, 64, 2.133333, 12.02.2013, 66, 2.2, 9, C, t12
52, 208, 6.933333, 13.02.2013, 370, 12.33333, 10, D, t13
18, 918, 30.6, 14.02.2013, 1496, 49.86667, 11, A, t14
19, 1045, 34.83333, 15.02.2013, 2085, 69.5, 12, B, t15
31, 744, 24.8, 16.02.2013, 1011, 33.7, 13, D, t16
2, 136, 4.533333, 17.02.2013, 184, 6.133333, 14, E, t17
83, 1411, 47.03333, 18.02.2013, 2099, 69.96667, 15, D, t18
33, 2244, 74.8, 19.02.2013, 2611, 87.03333, 16, A, t19
91, 819, 27.3, 20.02.2013, 1568, 52.26667, 17, B, t20
83, 2241, 74.7, 21.02.2013, 4236, 141.2, 18, C, t21
2, 156, 5.2, 22.02.2013, 179, 5.966667, 19, D, t22
78, 4212, 140.4, 23.02.2013, 6581, 219.3667, 20, A, t23
61, 2562, 85.4, 24.02.2013, 2658, 88.6, 21, B, t24
99, 7821, 260.7, 25.02.2013, 9666, 322.2, 22, D, t25
8, 752, 25.06667, 26.02.2013, 930, 31, 23, E, t26
64, 6336, 211.2, 27.02.2013, 7713, 257.1, 24, D, t27
];
При каждом открытии документа следует выполнять обновление данных, тогда данные не будут загружаться согласно таблице доступа List_ACL
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Спасибо, за пример. Но обновление данных при открытии документа пользователем для нас не приемлемо.
У нас QV сервер. Все пользователи работают через него.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Еще вариант, делаем несколько разных колонок со сведениями по уровням доступа. И обрезаем доступ к ним по OMIT.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Игорь, доброго дня,
Прикрепляю простейший пример.
В нем заданы пользователи (все без пароля):
- U1 - U5, для которых в секции доступа задана возможность просматривать Cost по только одной из продуктовых групп (A-E соответственно)
- U6, для которого в секции доступа задана возможность просматривать Cost по 4-м первым продуктовым группам (A-D)
- Admin, для которого в секции доступа задана возможность просматривать Cost по всем группам продуктов одновременно (A-E)
Для простоты отслеживания "вырезаемых" данных я ввел идентификатор, соответствующий номеру строки в вашей исходной таблице.
Как я уже говорил, основной вопрос заключается в том, что вы будете дальше делать с этими данными. Т.е. какое их представление потребуется для конечных пользователей. Т.к. очевидно, что предложенный мной вариант имеет простое решение в части первоначального секционирования данных, но в плане желаемых вами вариантов визуализации может внести ограничения, т.к. работа с полученными "островками данных" имеет свою специфику.
Поэтому я, как и большинство коллег в этом диалоге явно указывали, что выбираемый вариант секционирования в полной мере будет зависеть от конечных задач вашего приложения.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Игорь, добрый день,
помог ли предложенный вариант?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Игорь,
мы решили проблему разделения прав доступа - посредством ограничения прав на лист.
Т.е. у нас есть файл ,в котором находятся данные на всю компанию. задача была ограничить доступ к фин данным по отделам.
В итоге мы выделили неодходимые показатели для каждого отдела на отдельный лист. И дали права каждому отделу на свой лист.
хотя может и не самый красивый метод, но рабочий.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Сергей, огромное спасибо за наглядный пример. Я разобрался с предложенным вариантом. К сожалению этот вариант нас не устраивает, т.к. сильно усложняет и ограничивает визуализацию данных (особенно учитывая, то что у нас уже внедрены и используются разработанные приложения и каким-либо образом ограничить их функционал или уменьшить производительность в принципе не возможно). На текущий момент у нас достаточно сложная модель с большим количеством аналитических показателей (финансовые, показатели продаж и пр.) связанных со спецификой бизнеса компании. Для нас приоритетно решать максимальное количество поставленных задач на этапе скрипта, а на уровне визуализации делать все как можно проще, быстрее и с минимальными ограничениями. Пользователь работает только с визуализацией и никакие объяснения об ограничениях или медленной работе (простых с точки зрения пользователя) расчетов его не устроят.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Павел, спасибо за совет. Но вариант для нас не подойдет. У нас один показатель должен быть доступен по всем товарам, а другой показатель тоже доступен, но по определенным товарным группам. Для разных пользователей свои группы.