Unlock a world of possibilities! Login now and discover the exclusive benefits awaiting you.
- Qlik Community
- :
- Forums
- :
- Groups
- :
- Location and Language
- :
- Россия и СНГ
- :
- Measuring the speed of loading a new calculated fi...
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Feature this Topic
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Measuring the speed of loading a new calculated field when large volumes of data
Colleagues,
during one of the discussions of the Qlik Community there was an idea to test in practice the following question. Often, in practice, there is a task to add to an existing table a new calculation field. The discussions often occur two variants.
Variant 1. Loading table starting (using From, Inline or Autogenerate). Next, using NoConcatenate to create a second table with all the fields of start table and add a new field. At the end of the starting table is deleted.
Variant 2. Loading table starting (using From, Inline or Autogenerate). Next, using Left Join add a new field.
Question: Which variant is faster when much data?
The following code was used for variant 1.
//load the start table
StartTable:
LOAD
RecNo() as ID,
Div(Rand()*100, 1) as Volume
AutoGenerate 100000000;
LET StartTime = Now(); //Start time
NoConcatenate
FinishTable:
LOAD*,
Volume - 50 as Volume1
Resident StartTable;
DROP Table StartTable;
LET FinishTime = Now(); //Finish time
LET ResultTime = Time(FinishTime - StartTime);
The following code was used for variant 2.
//load the start table
StartTable:
LOAD
RecNo() as ID,
Div(Rand()*100, 1) as Volume
AutoGenerate 100000000;
LET StartTime = Now(); //Start time
left Join
LOAD*,
Volume - 50 as Volume1
Resident StartTable;
LET FinishTime = Now(); //Finish time
LET ResultTime = Time(FinishTime - StartTime);
The measurements were performed on a single computer. For each variant, created from scratch a new clean database with no data. Create 100 million records in the starting table. Carried eight downloads the script of each variant.
The results were obtained as follows.
Variant 1
Example picture
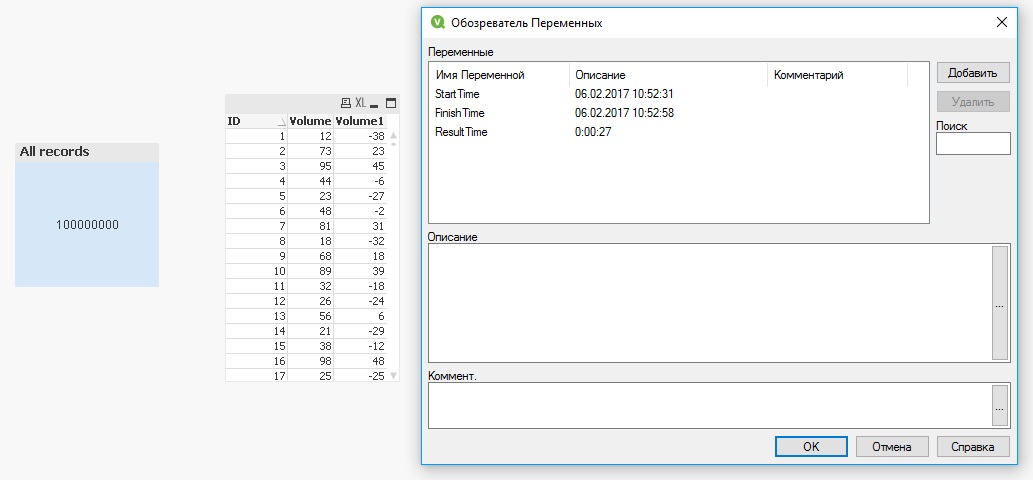
The average download time was ~27,9 seconds.
Variant 2
Example picture
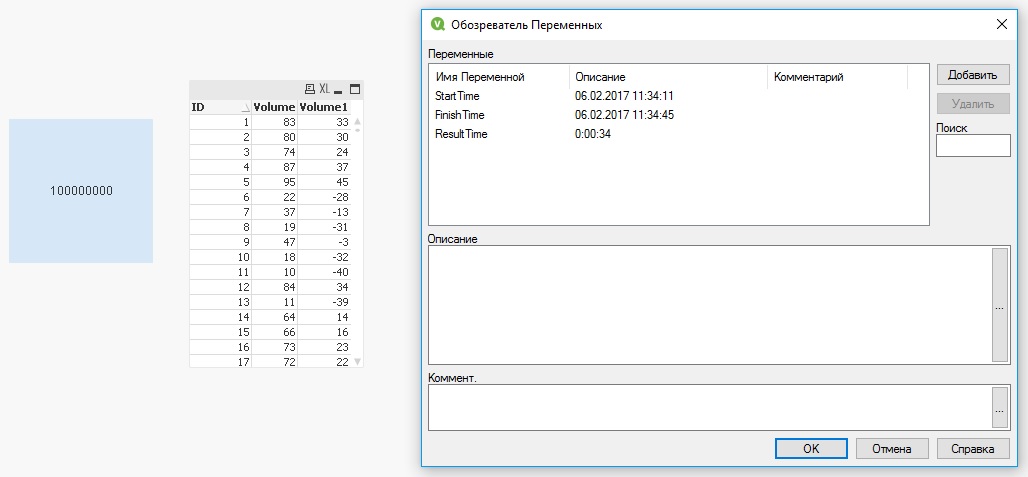
The average download time was ~33,0 seconds.
Conclusion: The rate of data download variant 1 above variant 2 download speed by ~18,3%. For a small data size speed difference is likely to be not noticeable, it may be used any of the variants. For large amounts of data difference of speed should be considered depending on the circumstances.
I am glad, if these measures show someone interesting.
Regards,
Andrey
- Tags:
- Group_Discussions
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Andrey, you have to be concerned that your second approach has a severe vulnerability to data inconsistency risk. Consider that your fact table to which you are adding a new calculated field has several fully duplicated rows. This case is rather likely in real environments, and if you make a join like the one you mentioned you'll inevitably come with a set of unintentionally multiplicated records which will misrepresent your calculations. The code below is an illustration.
So I would strongly NOT recommend using Left Join for a task of adding a calculated field to a logical table. The safest and most practical method would still be using a temporary table with resident load from a previously loaded table and subsequent deletion of the latter. An alternative approach would be Preceeding Load feature, though it has it's own limitations, see Rob Wunderlich's article The Cost of Preceding Load | Qlikview Cookbook
/* load 3 records of data with 2 of them beeing fully similar */
[fact table]:
LOAD
*
Inline
[
Dim1 , Dim2 , Measure1
DimValue1-1 , DimValue2-1 , 1
DimValue1-1 , DimValue2-1 , 1
DimValue1-2 , DimValue2-2 , 2
]
;
/* adding a calculated field through Left Join */
Left Join ([fact table])
LOAD
*,
( Measure1 * 10 ) as Measure2
Resident
[fact table]
;
/* !!! ending up with 5 records of data, which is an undesired result */
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Vasily,
thank you for your reply and your thoughts. It was only on the comparison of download speed in those cases where the use of the left connection is possible (key fields by definition can not have two identical values, for example).
And of course you're right. We have to understand the applicability of the LEFT JOIN use at load.
Thank you for your helpful comment.
Regards,
Andrey
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Although the above task is not within the theme this document, let's we will solve it - the task is set and has not been solved. As variant, to the source code we will add two lines (the source code is left unchanged, the added one is highlighted in red)
/* load 3 records of data with 2 of them beeing fully similar */
[fact table]:
LOAD
RecNo() as ID, //Add artificial key field
*
Inline
[
Dim1 , Dim2 , Measure1
DimValue1-1 , DimValue2-1 , 1
DimValue1-1 , DimValue2-1 , 1
DimValue1-2 , DimValue2-2 , 2
]
;
/* adding a calculated field through Left Join */
Left Join ([fact table])
LOAD
*,
( Measure1 * 10 ) as Measure2
Resident
[fact table]
;
DROP Field ID From [fact table]; //Delete artificial key field
/* !!! ending up with 5 records of data, which is an undesired result */
Result
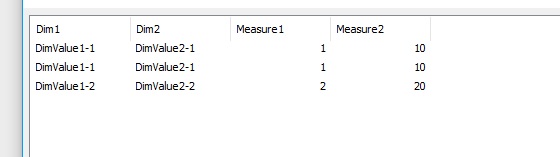
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Well, now you ended up with adding calculated field twice, first one being artificial key ))) This trick might double reload time of this part of the script. I cannot think of any scenario where it could be useful. However, thanks for your research, now I'm quite sure that the simplier method with temporary resident is also the most effective and safe. No doubt.