Unlock a world of possibilities! Login now and discover the exclusive benefits awaiting you.
- Qlik Community
- :
- Forums
- :
- Analytics & AI
- :
- Products & Topics
- :
- App Development
- :
- Star schema dimensions: to join or not to join?
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Star schema dimensions: to join or not to join?
As data has been getting larger, I have had a renewed interest in whether denormalizing (joining) dimensions to fact tables in the Qlik data model results in the best calculation performance.
For a long time, we believed that denormalizing always led to the best calculation performance, at the expense of RAM, but now I have seen examples of denormalized data tables getting so large that the overhead from the increased app footprint seems to cancel out the calculation benefits we expected. This leaves me wondering if there are other options that can improve performance without making large apps even larger.
People tend to think only about the structure of a data model when making performance recommendations, which is useful, but ignores a hidden variable that I have discussed here before: the sort order of the data in that structure. (Please check that link for foundational background, else this will be hard to follow.) My theory is that people have long attributed improved performance to denormalizing, while much of the benefit is a hidden byproduct of the join operations, themselves: sorting the data. Data table sort order may in fact be more important than the structure of the data model.
Testing
I spent a few minutes Googling to see what the interwebs say about joining dimensions to fact tables and came across a post on the Infinity Insight blog with tests and data (excellent!) about the performance effects of denormalizing. Vlad provided the QVWs, which was helped me quickly test and demonstrate a few concepts below. It all starts with a simple, normalized data model with an Invoices fact table and Customer and Calendar dimensions. Below are the details on my three test cases.
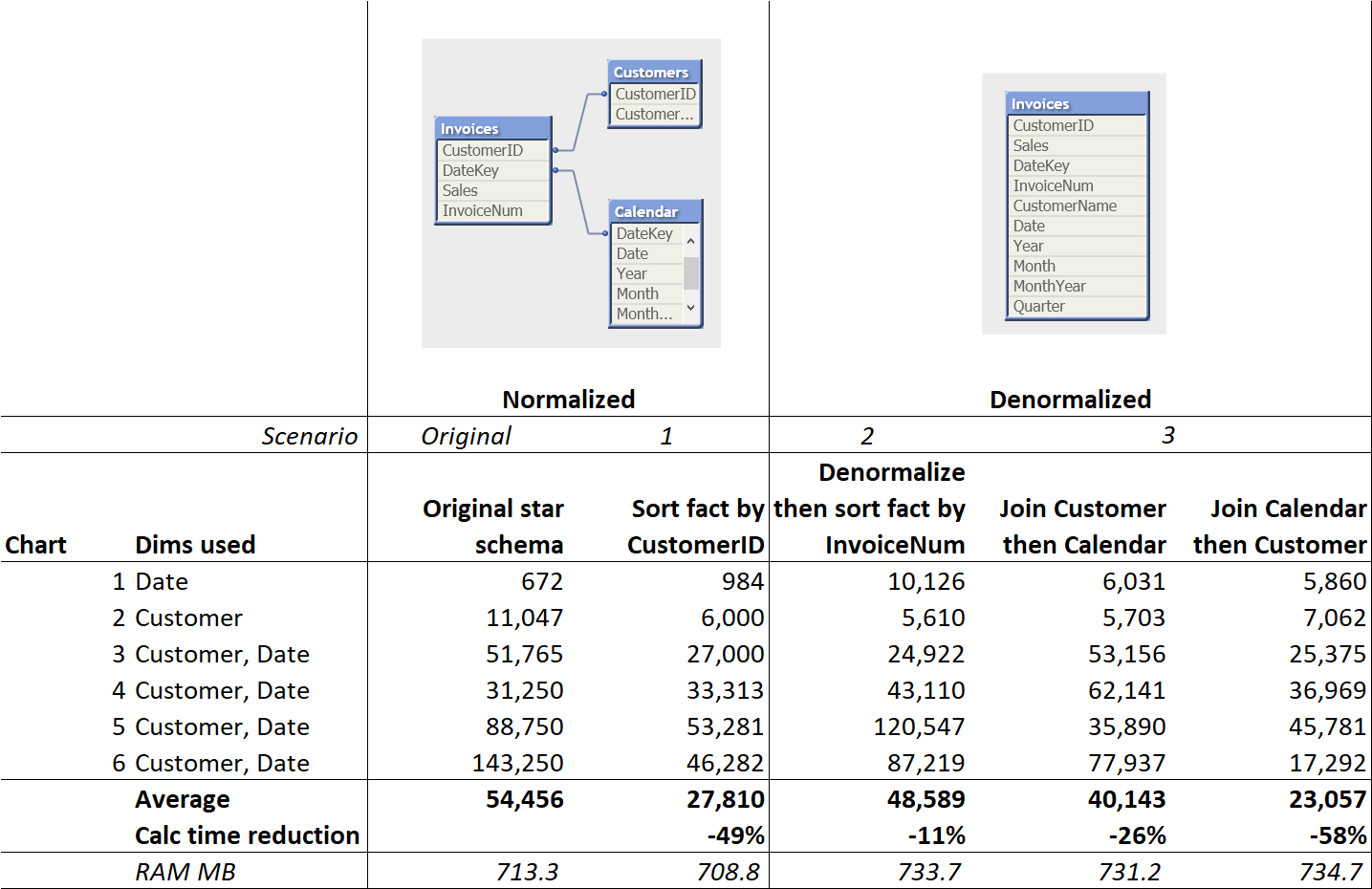
1. Sort Invoices fact table by CustomerID, don't join anything
Still using a normalized star schema, we have cut the average chart calculation time in half! In fact, this is the second best performance, overall, coupled with the lowest RAM consumption, without the data model looking any different from the original.
2. Join both dimensions, then re-sort by InvoiceNum to restore the original sort order
This example allows us to isolate what performance change is attributable to denormalizing alone, controlling for the change in sort order that normally results from the joins. Surprisingly, denormalizing only improved performance by 11%. It did help, but not by much, with increased RAM consumption. We got much better calculation times and lower RAM consumption in the first test case, which was still normalized.
3. Compare joining Calendar then Customer to joining Customer then Calendar
When people denormalize data models, the order of the joins can seem like an arbitrary decision, but as you can see, it does matter. Whatever is joined last is what ends up determining the final sort order of the fact table. Joining by Calendar last only yielded a 26% calculation improvement, while joining by Customer last yielded a 58% improvement, the best overall. The order in which tables are joined may lead one to falsely conclude that denormalizing helps a lot or just a little, while the difference they are observing is partly attributable to whatever order they happened to perform the joins. The resulting data structures look the exact same, and that's the only variable they are aware they are testing. Note that these are both better than 11%, because sorting by any dimension is likely to help in some charts, compared to total randomness. Also note that the denormalized data model with Calendar joined last performed worse than the first scenario's normalized data model.
In this specific app and data model, denormalizing improved performance by 11%, while sorting the fact table improved it by 49% -- significantly better. Combining the two yielded the best performance improvement, 58%.
Conclusions
- Data model structure/relationships are discussed most, but sort order is an important, hidden property affecting calculation performance.
- The positive effect of denormalizing has been overstated because people do not control for the sorting that also happens when they denormalize. In this case, a developer would have concluded that denormalizing improved performance by 26% or 58%, while it was truly just 11%, controlling for the sorting. (It's not either/or, of course.)
- If you are denormalizing, pay attention to the order in which you join tables, because the last table joined will determine the final sort order applied to the fact table. Try joining different tables last and choose the one that results in the most desirable UI performance. As you can see in the third example, just changing the order of the tables being joined -- arbitrary, to most -- doubled the performance improvement, even though the final data models have an identical structure.
Why did ordering by CustomerID seem to work so well, in this case? In the example QVW, 5 out of 6 chart have Customer as the first chart dimension. Ordering the underlying data model by Customer reduced the overhead of Qlik aggregating the data for display in each of those charts because the charts are grouping by something that has already been grouped via the sort order.
However, that won't be the case in every chart, in every application -- just this one. There is no reliable way to say what data model or sorting will always work best for you. It depends on how the data is being used in the front end of that app and what aspect of performance you care about most. You may even decide to tune the data model to improve one specific, slow chart, at a minor expense to all the others. It's a mix of art and science, but awareness, test cases, and data will lead you to the best results.
These results were so interesting that I plan to do a followup post, recreating in Qlik Sense and with another test case.
https://www.michaelsteedle.com/2019/06/star-schema-dimensions-to-join-or-not.html