Unlock a world of possibilities! Login now and discover the exclusive benefits awaiting you.
- Qlik Community
- :
- Forums
- :
- Analytics
- :
- New to Qlik Analytics
- :
- How to link multiple fact tables ?
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
How to link multiple fact tables ?
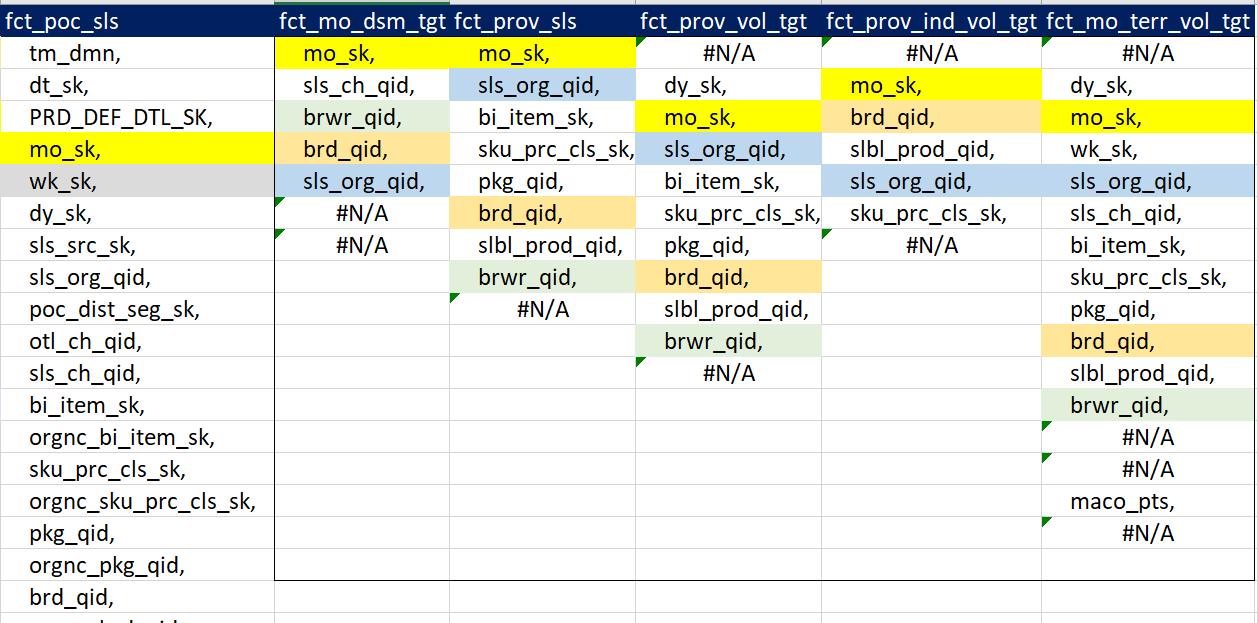
Objective: Purpose to reduce the size of 1 massive fact table that contains over 400 million rows of data. Currently this fact tables consists of data from 6 smaller fact tables, all concatenated together - there by blowing up the size exponentially.
Idea is to reduce the size by removing redundant keys / columns
What is the best approach to create a bridge table to remove column redundancy in all these different fact tables ?
Will that have any impact on performance ?
Column details of all fact tables:
Below is a screenshot of all common fields between these tables. The left most table being the main fact table with the most no. of rows and columns. The other tables have common fields listed below.