Unlock a world of possibilities! Login now and discover the exclusive benefits awaiting you.
- Qlik Community
- :
- Forums
- :
- Analytics
- :
- New to Qlik Analytics
- :
- What am I doing wrong with my data model
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
What am I doing wrong with my data model
Hi guys, I need to better understand how Qliksense data models work and why mine is messing up
I come from a SQL background so understand joins though cant quite get my head round this....
I have successfully built some Qliksense apps to varying degrees of success but synthetic keys are confusing me. I've read various articles and stuff. This one seems very simple and I've gone back to basics. I'm working with 2 personal data files at this point on QlikCloud basic version so....
File 1 - rpt_ListContacts.txt
has fields
list_id,list_name,imported,campaign_id,call_date,call_hour,calls,dmcs,contacts,last_import_date
I load this, create the visuals/KPIs and everything stacks up just fine (which you would expect)
eg
dimensions list_id, call_date, call_hour
measures sum(dmcs), sum(contacts)
File 2 - rpt_ListLeads.txt
has fields
list_id,call_date,call_hour,leads
So the purpose of this file is to literally add sum(leads) to what I already have so
dimensions list_id, call_date, call_hour
measures sum(dmcs), sum(contacts), sum(leads)
In SQL I would do something like
select
c.list_id,
c.call_date,
c.call_hour,
sum(c.dmcs) as dmcs,
sum(c.contacts) as contacts,
sum(l.leads) as leads
from
rpt_ListContacts c
(right/left) join
rpt_ListLeads l
on c.call_date = l.call_date and c.call_hour = l.call_hour and c.list_id = l.list_id
group by
c.list_id,
c.call_date,
c.call_hour
When I add the 2nd file to my data model I get the synthetic key warning. This is what my model looks like.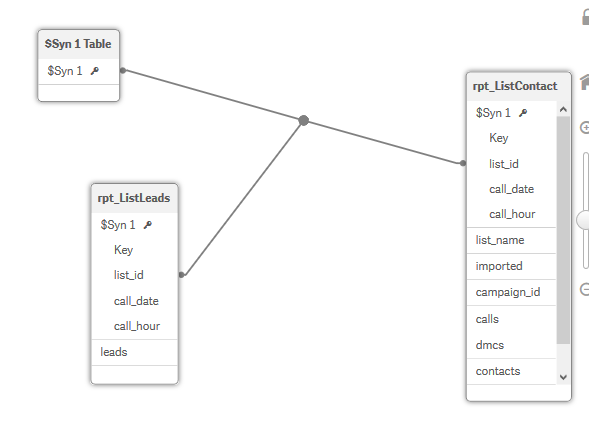
I also tried adding a key field as you can see by concatonating the list_id, call_date, and call_hour fields. I read that can help but dont quite get it.
Anyway, when I add a sum(leads) measure to my visuals(happens to be a pivot table but I guess that's not relevant as it does the same on a KPI), all the data from table 1 (rpt_listcontacts) remains good, however the sum(leads) from rpt_listleads is crazy wrong, like 100x higher than it should be. I cant quite figure out what the number is, I'm thinking its something like distinct date * list_ids * hours
I hope this makes sense and hope you can help me understand, is there something obvious glaringly wrong with my approach/understanding. Please let me know if I can provide anymore information here and look forward to your expert advise:)
- Tags:
- synthetic keys.
Accepted Solutions
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Matt,
So the purpose of this file is to literally add sum(leads) to what I already have so
This sentence suggest me that you want to append data to the current table (kind of UNION ALL), then can use the Concatenate(rpt_ListContact) on the second table load.
So your script will look like this
[rpt_ListContact]:
LOAD
[list_id],
[list_name],
[imported],
[campaign_id],
[call_date],
[call_hour],
[calls],
[dmcs],
[contacts],
[last_import_date]
FROM [lib://qlikid_reports/rpt_ListContact.txt]
(txt, codepage is 1252, embedded labels, delimiter is ',', msq);
Concatenate([rpt_ListContact])
LOAD
[list_id],
[call_date],
[call_hour],
[leads]
FROM [lib://AttachedFiles/rpt_ListLeads.txt]
(txt, codepage is 1252, embedded labels, delimiter is ',', msq);
Otherwise, the synthetic key is correct (I know a lot of people will tell you otherwise). I also had struggle with Qv at the beginning ( I share same background), and reading your query I understand that you predicted that call_date, call_hour and list_id will be appear in both, synthetic key simply creates a new table with all the combinations.
You mention that you get the synthetic key warning, but did you get any data errors? (Just remove the key column as you don't need it)
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
If you already have created the Key field, then you only need to keep the fields that build the Key in either one of the tables, in the one that holds potentially the complete set of field values.
Drop the field from the other table.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thank you sir and that kind of makes sense however I'm still getting the same results
So my script I changed
FROM
[rpt_ListContact]:
LOAD
[list_id] & [call_date] & [call_hour] AS Key,
[list_id],
[list_name],
[imported],
[campaign_id],
[call_date],
[call_hour],
[calls],
[dmcs],
[contacts],
[last_import_date]
FROM [lib://qlikid_reports/rpt_ListContact.txt]
(txt, codepage is 1252, embedded labels, delimiter is ',', msq);
[rpt_ListLeads]:
LOAD
[list_id] & [call_date] & [call_hour] AS Key,
[list_id],
[call_date],
[call_hour],
[leads]
FROM [lib://AttachedFiles/rpt_ListLeads.txt]
(txt, codepage is 1252, embedded labels, delimiter is ',', msq);
TO
[rpt_ListContact]:
LOAD
[list_id] & [call_date] & [call_hour] AS Key,
[list_id],
[list_name],
[imported],
[campaign_id],
[call_date],
[call_hour],
[calls],
[dmcs],
[contacts],
[last_import_date]
FROM [lib://qlikid_reports/rpt_ListContact.txt]
(txt, codepage is 1252, embedded labels, delimiter is ',', msq);
[rpt_ListLeads]:
LOAD
[list_id] & [call_date] & [call_hour] AS Key,
[leads]
FROM [lib://AttachedFiles/rpt_ListLeads.txt]
(txt, codepage is 1252, embedded labels, delimiter is ',', msq);
This indeed got rid of the synthetic key warning, though what i expect the totals to be on the added rpt_ListLeads.txt file are still C100x more than they should be
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Matt,
So the purpose of this file is to literally add sum(leads) to what I already have so
This sentence suggest me that you want to append data to the current table (kind of UNION ALL), then can use the Concatenate(rpt_ListContact) on the second table load.
So your script will look like this
[rpt_ListContact]:
LOAD
[list_id],
[list_name],
[imported],
[campaign_id],
[call_date],
[call_hour],
[calls],
[dmcs],
[contacts],
[last_import_date]
FROM [lib://qlikid_reports/rpt_ListContact.txt]
(txt, codepage is 1252, embedded labels, delimiter is ',', msq);
Concatenate([rpt_ListContact])
LOAD
[list_id],
[call_date],
[call_hour],
[leads]
FROM [lib://AttachedFiles/rpt_ListLeads.txt]
(txt, codepage is 1252, embedded labels, delimiter is ',', msq);
Otherwise, the synthetic key is correct (I know a lot of people will tell you otherwise). I also had struggle with Qv at the beginning ( I share same background), and reading your query I understand that you predicted that call_date, call_hour and list_id will be appear in both, synthetic key simply creates a new table with all the combinations.
You mention that you get the synthetic key warning, but did you get any data errors? (Just remove the key column as you don't need it)
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Another option, look at map_table.
It will look something like that:
[Map_rpt_ListLeads]
Mapping LOAD
[list_id] & [call_date] & [call_hour] AS Key,
[leads]
FROM [lib://AttachedFiles/rpt_ListLeads.txt]
(txt, codepage is 1252, embedded labels, delimiter is ',', msq);
[rpt_ListContact]:
Load
*,
Applymap('Map_rpt_ListLeads',Key,'No Key Found') as Leads;
LOAD
[list_id] & [call_date] & [call_hour] AS Key,
[list_id],
[list_name],
[imported],
[campaign_id],
[call_date],
[call_hour],
[calls],
[dmcs],
[contacts],
[last_import_date]
FROM [lib://qlikid_reports/rpt_ListContact.txt]
(txt, codepage is 1252, embedded labels, delimiter is ',', msq);
Then you'll add Leads to each combination (and actually that's closer to your query).
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
OK cool thank you, I'm starting I think to see the wood for the trees and made some progress with this method. I'm happy that the synthetic key is correct I think 
So to throw a spanner in the works, the UNION ALL similarity bit makes complete sense to me
And now if I sum(leads) I get the correct result.
Now.... In table1 (rpt_ListContacts) I have a field called list_name which I'd like to filter on. This field does not exist in table2 (rpt_ListLeads). list_name is simply a definition of list_id
So
If I filter by list_id my table looks like this (see last field) which is good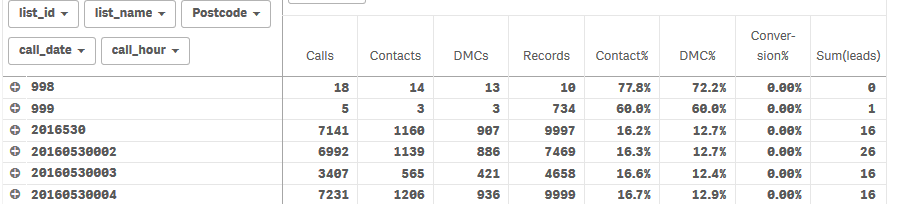 ....
....
And if I change it to list_name it looks like this
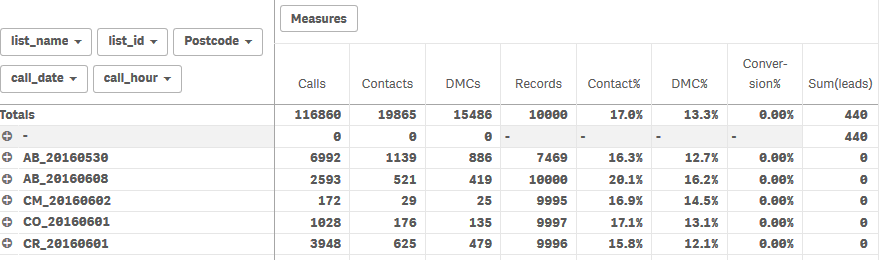
So I suppose internally (if we think of a UNION ALL) then I've got nulls where the list_name would be in table 2 hence it cant link up?
So I guess in laymans terms what I'm trying to get my head around is I need
select
c.list_id,
c.call_date,
c.call_hour,
sum(c.dmcs) as dmcs,
sum(c.contacts) as contacts,
sum(l.leads) as leads
from
rpt_ListContacts c
(right/left) join
rpt_ListLeads l
on c.call_date = l.call_date and c.call_hour = l.call_hour and c.list_id = l.list_id
where c.listname = @listname
group by
c.list_id,
c.call_date,
c.call_hour
I was hoping/expecting the association between list_id, call_date, call_hour in both tables would let me filter on column (for example) list_name in table 1 (rpt_listcontacts)
Making sense? really appreciate your assistance
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
OK I've marked the correct answer. I still need to get my head around this better, though the concatenate script from jmolinasa helped me achieve what I wanted
I did however have to put in what I would consider a hack to work properly (as I envisage it) and add my list_name field to both 'tables' exported from SQL so I could filter on that also
Learning curve, thanks for the replies
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thanks for marking it!
Is going to be a way of trial an error.
Some heads up, what I notice from Qv is that they use mapping tables often during the script, I find it kind of joins, as it only adds 1 extra column based on the key, but I'm a bit reluctant to use a silver bullet as I already experience (actually fixed) that a wrong join in sql can drive you to duplicated or triplicated results in some cases.
Regards,
Julio
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Cool thanks again.
Yeah I've not yet ventured to mapping tables, I saw your example, but for me as (luckily?) I have control over the data that comes in that was the quickest and logical solution for now. Deffo need to learn more scripting/change mindset
Cheers